")
Cet article est le premier d’une suite d’article intitulée « Machine Learning pour débutant ».
Dans cette suite, nous allons abordé toutes les techniques de bases de l’apprentissage automatique (Machine Learning) en partant des modèles de prédiction (regression, clasification) jusqu’au systemes de recommendations en passant par les SVM et les réseaux de neurones…
Pour chacun de ces techniques, nous allons expliqué étape par étape et le plus simplement possible le processus permettant de le developper de A à Z.
A la fin de cette suite, nous espérons que vous aurez compris toutes les techniques de bases du Machine Learning.
Prérequis
Il y a certains prérequis qui ne sont pas obligatoires mais qui rendraient beaucoup plus facile la compréhension de cette suite d’articles. Ces prérequis sont les suivants :
- Quelques notions d’algèbre linéaire (manipulation des matrices et vecteurs).
- Quelques notions de probabilités et de statistiques (distribution de probabilités, moyenne, variance).
- Python pour calcul numérique (Numpy).
Introduction
Selon Arthur Samuel (1959); Machine Learning (ou apprentissage automatique) est un domaine d’études qui permet aux ordinateurs d’apprendre sans être explicitement programmés.
Selon Tom Mitchell (1998) ; Un programme informatique est dit apprendre de l’expérience E en ce qui concerne une certaine tâche T et une certaine mesure de rendement P, si son rendement sur T, tel que mesuré par P, s’améliore avec l’expérience E.
Il existe plusieurs types d’apprentissages automatiques parmis lesquels on peut citer :
– Les apprentissages (supervisé, non supervisé, et par renforcement).
– Les systems de recommandations, etc.
Apprentissage supervisé
D’aprés wikipedia, l’apprentissage supervisé est une tâche d’apprentissage automatique consistant à apprendre une fonction de prédiction à partir d’exemples étiquetés.
En d’autres termes, l’apprentissage supervisé est le faite de trouver, à partir d’un ensemble de données \(E_n = \{(x^1,y^1),…,(x^n,y^n)\}\) , une fonction \(f : X \rightarrow Y \)
de tel sorte que pour tout \((x^i,y^i) \in E_n\) on ait \(f(x^i)\approx y^i\).
L’image ci-dessous présente le workflow d’un apprentissage supervisé :
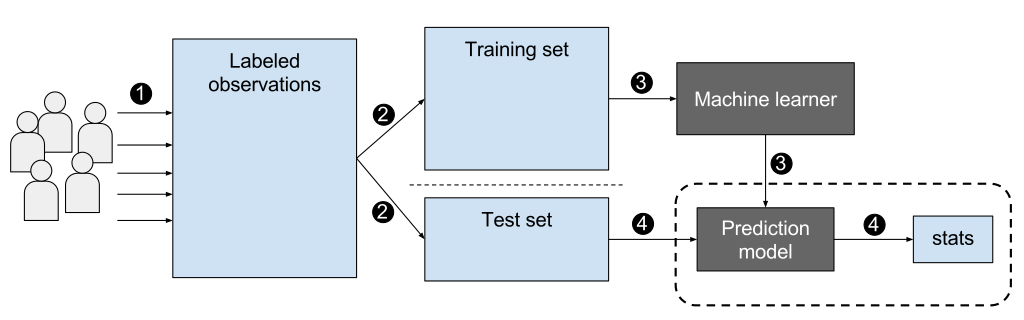
EpochFail – CC BY-SA
Il existe deux types de modèles d’apprentissages supervisés : les modèles de régressions et les modèles de classifications.
Régression
Un modèle de regréssion permet de prédire une valeur continue (quantitative). Cela signifie que l’ensemble des valeurs de sortie Y qu’on essai d’estimer avec la fonction f est un ensemble de réels : \(Y \subset \mathbb{R}\).
Supposons qu’on veut créer un modele \(f : X \rightarrow Y \) qui prédit le prix d’une maison en sachant la surface en \(m^2\)
Dans Cet exemple, X représente l’ensemble des surfaces des maisons et Y représente l’ensemble des prix.
Si on veut estimer le prix d’une maison de surface s, on calcule \( f(s)\).
Classification
Un modèle de classification permet de prédire une valeur discrète (qualitative). Cela signifie que l’ensemble des valeurs de sortie Y qu’on essai d’estimer avec la fonction f est un ensemble fini : \(Y=\{0,1,…,n\}\).
Supposons qu’on veut créer un modele \(f : X \rightarrow Y \) qui prédit si un mail est un spam ou pas.
Dans Cet exemple, X représente l’ensemble des mails à analyser et \(Y=\{0,1\}\); 1 si le mail est un spam et 0 sinon.
Si on veut analyser un mail m, on calcule \( f(m)\).
Apprentissage non supervisé
Selon wikipedia, à la différence de l’apprentissage supervisé, un algorithme d’apprentissage non supervisé doit opérer à partir d’exemples non étiquetés. il doit extraire automatiquement les catégories à associer aux données (exemples) qu’on lui soumet.
L’algorithme cherche à maximiser d’une part l’homogénéité des données au sein de chaque catégorie et, d’autre part, à former des catégories aussi distincts que possible.
Le problème d’apprentissage non supervisé le plus fréquent est le clustering qui consiste à regrouper un ensemble d’éléments hétérogènes sous forme de sous groupes homogène.
Mais il existe aussi la réduction de dimension qui (comme son nom l’indique) consiste à réduire la dimension des données.
Clustering
Comme indiquer sur mon article intitulé Clustering avec l’algorithme DBSCAN, le clustering vise à diviser un ensemble de données en différents « paquets » homogènes, en ce sens que les données de chaque sous-ensemble partagent des caractéristiques communes, qui correspondent le plus souvent à des critères de proximité (similarité informatique) que l’on définit en introduisant des mesures et classes de distance entre objets.
Ci-dessous, une image qui montre des données partitionnées par un algorithme de clustering :
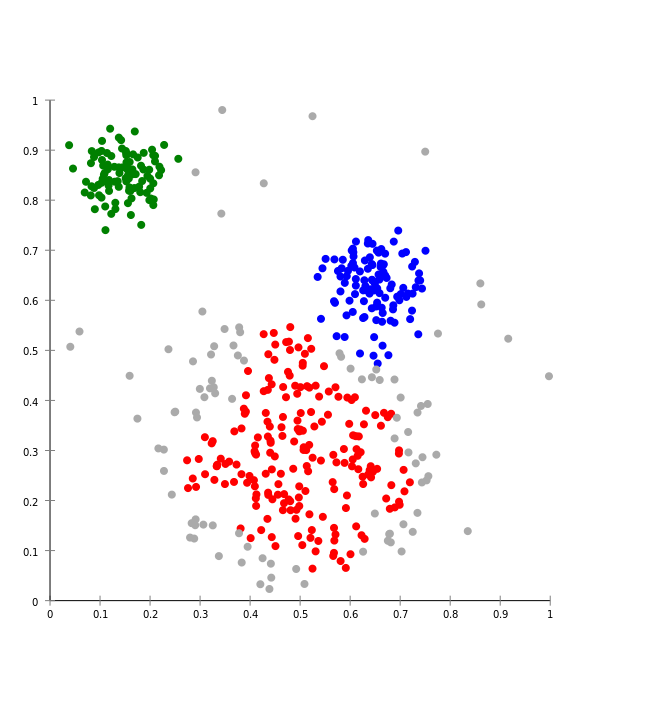
Réduction de dimension
La réduction de dimension consiste à prendre des données dans un espace de grande dimension, et à les remplacer par des données dans un espace de plus petite dimension sans perdre la variance.
En d’autres termes, la réduction de dimension permet de projeter des données issues d’un espace de grande dimension dans un espace de plus petite dimension.
La réduction de dimension est utile en machine learning car les données de plus petites dimension peuvent être traitées plus rapidement. Et il permet aussi de lutter contre le fléau de la dimension.
Conclusion
Dans cet article, nous avons aborder de petites introductions sur les méthodes d’apprentissages (supervisé et non supervisé) les plus utilisées en machine learning. Ces méthodes seront developper plus en détail sur les prochains articles de cette suite.
Il existe d’autres méthodes apprentissages, qui seront eux aussi developper dans cette suite d’articles, comme les SVM, les systemes de recommendation, les systemes de detection d’anomalies, etc.
Le prochain article de la suite portera sur « la regréssion linéaire avec une seule variable ».
Crédit de l’image de couverture : Chire – CC BY-SA 3.0



 jusqu'au systemes de recommendations en passant par les SVM et les réseaux de neurones etc.){kind=link}
{kind=link}
{kind=link}
{kind=link}