
L’IA déchaîne notre imaginaire, et il n’est pas rare de voir des titres sensationnels suggérant qu’elle peut « penser », « comprendre », s’adapter à l’instar d’un être humain.
Mais est-ce vraiment le cas ? Si elle peut me battre sur de la reconnaissance d’image ou compréhension de texte, établir une stratégie optimale dans un jeu vidéo, cela implique-t-il qu’elle « pense réellement » ?
Pour répondre à cette grande question, je vous propose de découvrir ensemble quels sont les rouages internes des IA d’aujourd’hui, pour que vous puissiez juger par vous-même !
Cette question a été divisée en deux articles :
- Partie I = présentation du problème, l’approche du machine learning (cet article)
- Partie II = les avantages du deep learning et de l’apprentissage par renforcement (à venir !)
Que signifie « penser » ? Qu’est-ce que l’on veut retrouver chez une IA ?
D’après le Wikitionnaire (j’aurais tout aussi bien pu citer le Larousse), la définition principale qui va nous intéresser est la suivante : exercer l’activité de l’esprit ; accomplir quelque opération de l’intelligence ; concevoir ; imaginer ; réfléchir.
Puisque qu’aucune intelligence artificielle n’a passé le test de Turing avec succès (ce test où on discute librement avec une personne inconnue et on doit déterminer s’il s’agit d’une IA ou d’un humain), on peut dire que la définition du mot « penser » est trop forte pour une IA, et on va considérer qu’il s’agit d’un abus de langage. Dans cas, qu’espère-t-on retrouver chez une IA pour dire qu’elle pense ? Quel étage de la pyramide de la conscience concerne les robots ?
Une IA qui pense, tel que je l’entends, est une IA capable de comprendre son environnement au-delà de ce qu’on lui a appris, de faire des plans (anticiper les conséquences d’actions), chercher à acquérir de nouvelles connaissances et faire ses propres choix (sans entrer dans la question du libre-arbitre). Quelque part, je dirai que le plus important est d’avoir sa propre interprétation du monde.
Est-ce qu’un seul modèle d’IA actuelle répond à ces critères ?
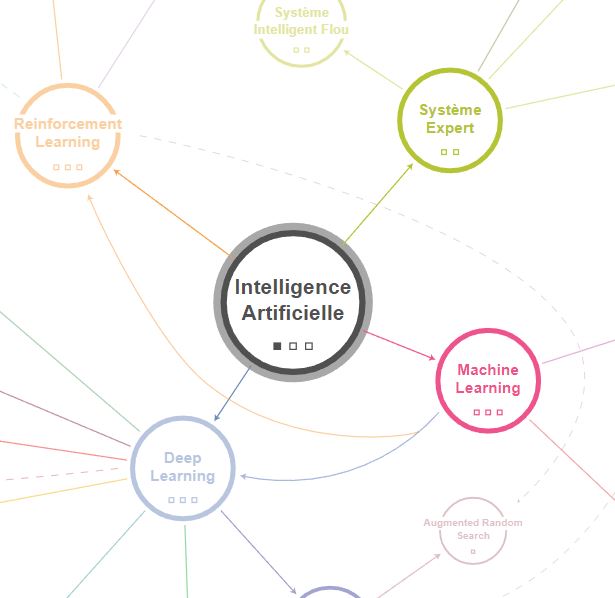
Une intelligence artificielle repose, aujourd’hui, sur un algorithme précis (même si on peut en combiner plusieurs, on ajoute simplement des fonctionnalités à l’IA sans cohérence globale et autonome), que l’on peut répartir en 4 classes principales comme présentés sur la carte interactive de l’IA par KnowMap (données ici par ordre de complexité et de potentiel « d’intelligence ») :
- les systèmes experts, qui sont les algorithmes les plus anciens et les plus simples
- le machine learning, que l’on va diviser en deux blocs : les algorithmes supervisés et les algorithmes non-supervisés
- le deep learning, qui regroupe plusieurs champs distincts
- le reinforcement learning, ou apprentissage par renforcement
Pour chaque famille, on va s’interroger sur les limites des modèles/idées sous-jacentes, et essayer de répondre à la question « Est-ce qu’une IA basée sur un algorithme de type Deep Learning, par exemple, peut penser ?« .
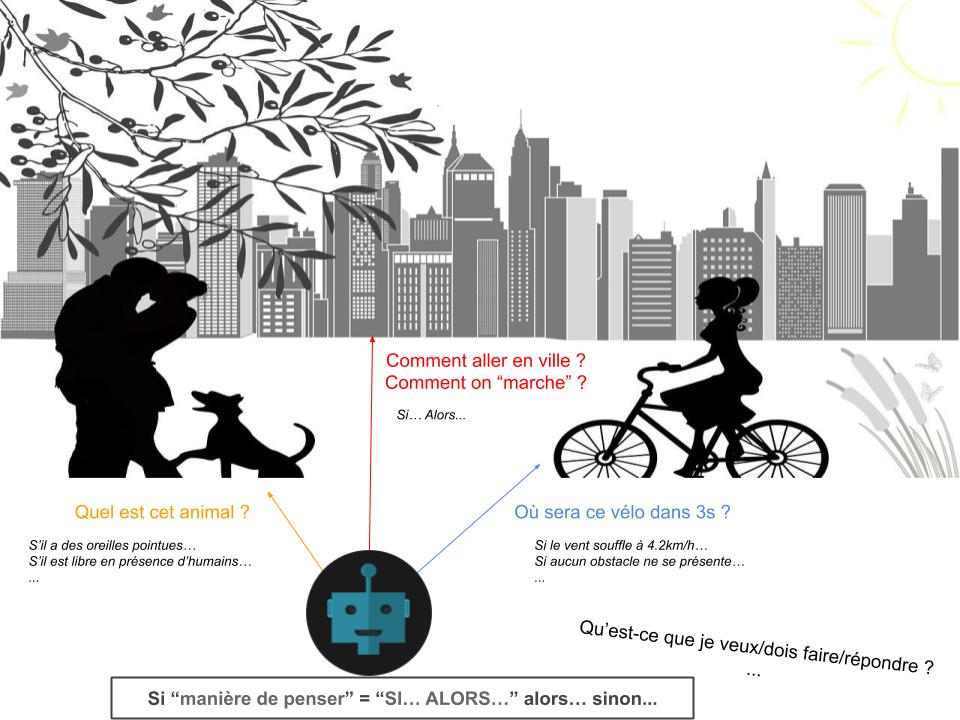
L’intelligence artificielle « de base » : les systèmes experts
Ce type d’IA est le plus simple et le plus ancien, mais soulève depuis les années 60 la question de l’autonomie d’une machine (historiquement, les premières idées d’automates remontent à l’Antiquité avec Philon de Byzance).
Prenons pour exemple l’algorithme suivant de prédiction de la météo :
SI la température est élevée
SI le taux d'humidité est faible
RENVOYER il va faire beau aujourd'hui
SINON
RENVOYER des orages sont à prévoir dans la journée
SINON
RENVOYER des nuages devraient apparaîtreL’intelligence qu’il y a là-dedans est celle de l’humain qui a écrit l’algorithme, qui a partagé ses connaissances sous forme de moteur de règles. Une telle IA ne « pense » pas et n’a PAS les outils pour le faire, car l’ensemble de son code est des « SI… ALORS… » : tout le monde connait les exceptions grammaticales de la langue française, alors imaginer que le monde qui nous entoure puisse se résumer en intégralité à des « SI… ALORS… » (au moins pour qu’on soit considérés comme « intelligent » en l’analysant ainsi) me paraît impossible, ne serait-ce qu’à cause du fait que le monde évolue.
Comment écrire des règles qui feraient évoluer les règles que l’on aurait trouvées ? Et les règles qui modifieraient ces règles gérant l’évolution ? Et ainsi de suite ?
Le machine learning supervisé et non-supervisé
Dans cette partie on va s’intéresser au machine learning, sans prendre en compte les algorithmes de deep/reinforcement learning car ils ont une approche totalement différente.
Les algorithmes de machine learning sont généralement divisés en deux groupes :
- Apprentissage supervisé : se dit d’un algorithme qui apprend à prédire à partir d’exemples annotés. Typiquement, une IA à qui on donne des exemples de prix d’appartements en fonction de leur superficie pour qu’elle en déduise un modèle est une IA supervisée.
- Apprentissage non-supervisé : c’est l’opposé de l’apprentissage supervisé i.e. on donne à l’IA des données et elle a pour objectif de trouver quelque chose qui les différencie en structures logiques. Par exemple, on donne une liste d’utilisateurs avec leur film préféré à une IA dont le but est de recommander un film à un nouvel utilisateur (en cherchant un profil approchant).
Jusqu’où peut aller l’apprentissage supervisé ?
Les algorithmes de machine learning supervisés sont assez variés, que ce soit pour de la classification, la régression ou les méthodes dites ensemblistes. J’ai notamment en tête la méthode des k plus proches voisins, Naïves Bayes, les arbres de décision, SVM, les régressions (linéaires, polynomiales, etc…), ElasticNet, LightGBM, XGBoost, Random Forest, et bien d’autres encore (que vous retrouverez en détail dans le livre Machine learning avec Python, dans la collection O’Reilly).
Fondamentalement, l’objectif du Machine Learning supervisé est de recevoir un ensemble de données (taille d’un appartement, nombre de pièces) avec des sorties correspondantes (prix) puis d’en déduire une sorte de « modèle » permettant d’extrapoler à des nouvelles données absentes de la base d’entraînement. Les données sont les points du schéma ci-contre, et la droite tracée correspond à ce que le modèle a compris.

C’est de méthodes statistiques que s’inspire l’algorithme de machine learning pour déduire les règles qui régissent le monde qu’on lui donne à analyser ! La décision que prendra une IA, sa « prédiction », pourra être (souvent) expliquée par le modèle et sera reproductible.
Contre-intuitivement, notez que beaucoup d’événements naturels peuvent être modélisés par des statistiques alors qu’a priori ça ne devrait pas être spécialement possible/logique. Par exemple, la loi de Poisson décrit bien l’arrivée de bateaux dans un port, tandis que la loi Normale fonctionne à merveille pour décrire la répartition des tailles humaines (pour un âge/sexe fixé).
Dès lors, avec suffisamment d’algorithmes de Machine Learning, on devrait logiquement pouvoir créer une IA qui « pense » et peut s’adapter au monde.
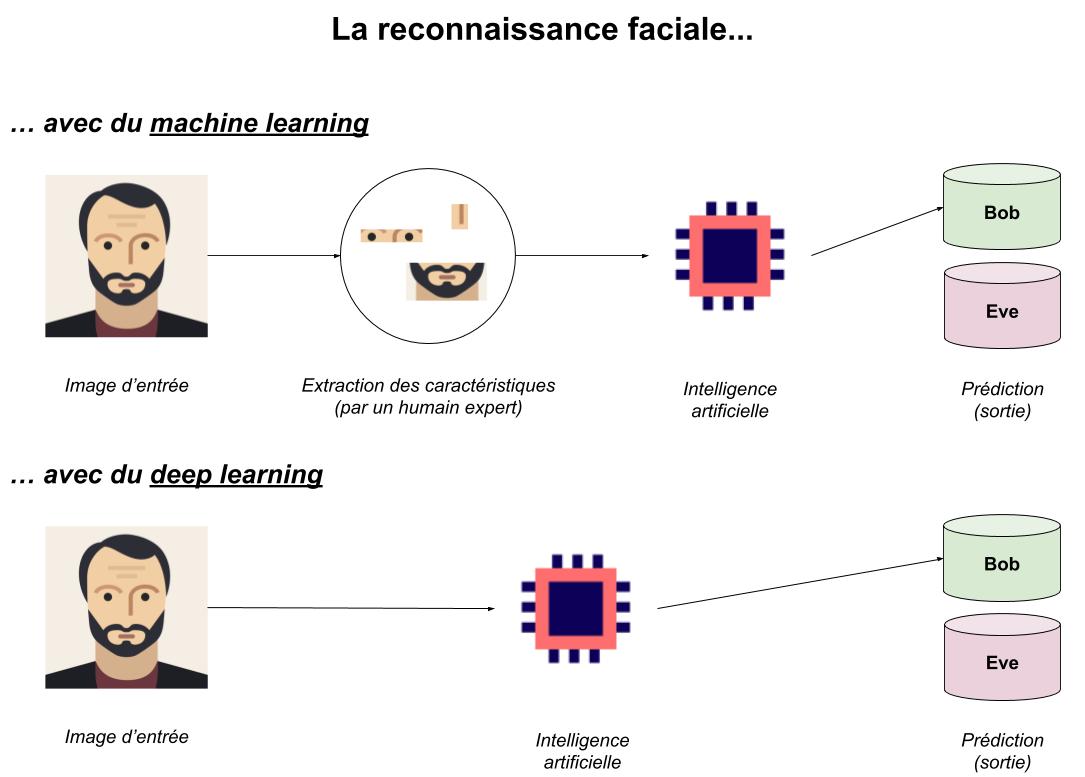
Oui mais. En réalité, comme le montre le schéma précédent, le machine learning a une grosse faiblesse : pour apprendre quelque chose, l’algorithme a besoin que les données soient « apprivoisées » (i.e. préparées). L’IA ne pourra déduire des modèles des données d’entrée que s’il n’y a pas trop de bruit. Pour la reconnaissance faciale, cela se traduit par l’extraction manuelle (par un humain) des yeux, du nez, de la bouche, etc… Bien sûr, on peut écrire un algorithme capable d’extraire les yeux d’une image (c’est le cas, avec Haar cascade par exemple), mais pour ça il faudra d’abord construire un jeu de données à la main pour l’entraîner.
Spontanément, un algorithme de machine learning aura beaucoup de mal à déterminer les informations pertinentes à conserver/transformer, et c’est pour ça que le travail du Data Scientist est déterminant de nos jours : pour son expertise dans l’analyse et la préparation des données… puis le choix du modèle adapté, car chaque algorithme aura ses spécificités et cas d’application !
En résumé, le Machine Learning est adapté à la compréhension d’un problème précis et pré-déterminé mais a du mal à se généraliser à d’autres secteurs que celui d’origine. L’IA ne « pense » pas au sens littéral mais construit un modèle statistique relativement simple qui va décrire le monde : on reste au niveau des mathématiques et il manque les mécanismes permettant d’aller au-delà (notamment la capacité d’adaptation à un tout nouvel environnement).
Et en machine learning non-supervisé ?
La question se règle encore plus rapidement que pour de l’apprentissage supervisé. En effet, le non-supervisé est la découverte de structures dans les données, sans que cela ait véritablement de « sens » : si je vous donne les chiffres de 0 à 9 et vous demande d’en faire deux groupes, vous me répondrez 0 2 4 6 8 et 1 3 5 7 9 (nombres pairs/impairs) ou 0 1 2 3 4 et 5 6 7 8 9, mais il n’y aura pas de « bonne » réponse car rien n’était attendu au départ.
Pour le machine learning non-supervisé c’est la même chose, en fonction du nombre de groupes demandés mais aussi d’une part d’aléatoire dans l’initialisation des paramètres, le découpage pourra être différent et en soi n’aura pas de « sens » directement. Par contre, ce découpage pourra servir à d’autres choses, par exemple pour recommander un film à un utilisateur (placé dans un groupe d’utilisateurs similaires).
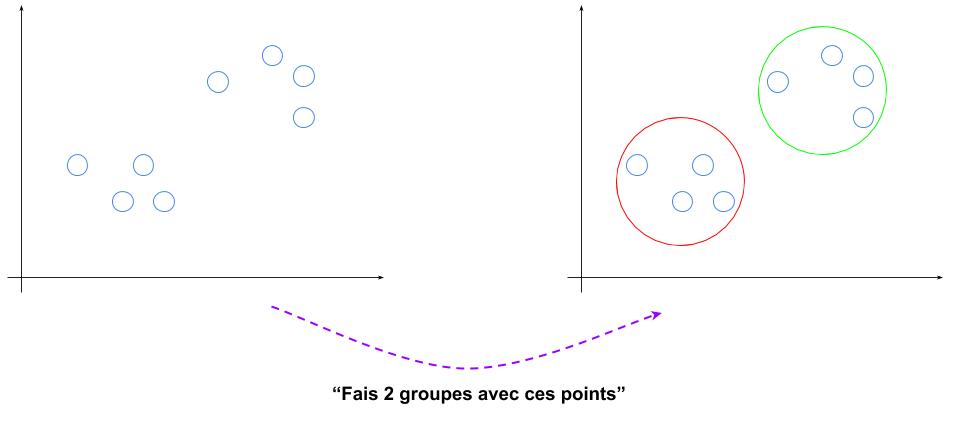
On peut donc considérer que l’apprentissage non-supervisé est plus un outil (d’analyse) qu’une intelligence et on peut l’écarter : il n’y a pas de réflexion derrière mais des calculs mathématiques de distance (ci-dessus, on cherche les points qui sont proches pour les regrouper) par exemple.
Conclusion
Dans ce premier article nous avons pu comprendre ensemble quelle est la problématique et comment fonctionne le machine learning (les systèmes experts sont suffisamment simples conceptuellement pour être laissés de côté). Les perspectives d’autonomie semblent insuffisantes pour la majorité des solutions abordées…
Mais peut-être que le deep learning, capable de traduire le langage naturel ou de reconnaître facilement différentes races de chiens sera-t-il capable de mieux comprendre le monde ? Et qu’en est-il de l’apprentissage par renforcement utilisé par Boston Dynamics pour que leurs robots aient l’allure (et la dextérité) de chats/chiens ? Affaire à suivre dans la partie II !
Crédit de l’image de couverture : imjanuary – Pixabay License



{kind=link}
{kind=link}