
S’il est bien une technologie qui revient régulièrement dans le monde du Big Data, c’est Spark. Mais de quoi s’agit-il exactement, à quoi sert ce « spark », comment l’utiliser en intelligence artificielle ?
Dans cette série d’articles autour de Spark 3 nous allons commencer par tout mettre en place sous Windows 10 ou 11 pour ensuite partir à la conquête du monde (virtuel) !
Lien vers les autres parties :
[Part 3] Spark Dataframes
[Part 4] Spark Streaming
[Part 5] Spark ML sur AWS
A quoi sert Spark ?
Apache Spark est un framework gratuit et open source permettant de réaliser des calculs de manière distribuée. Autrement dit, lorsqu’on souhaite lire et agir sur des données par exemple pour compter le nombre de logements par ville à partir de la liste (très longue) du cadastre, Spark fournit les outils pour que plusieurs ordinateurs se réunissent et procèdent au calcul ensemble.
Si Hadoop se concentre sur l’utilisation des disques durs pour faire les calculs, Spark s’appuie sur la mémoire RAM ce qui en fait la solution la plus rapide du marché, sa simplicité comparée à l’écosystème d’Hadoop (Hive, Mahout…) le rendant le framework absolu du Big Data.
A noter que Spark peut être programmé avec du Python, du Java, du Scala (Spark est codé en Scala) ou du .NET.
Comment installer Spark sous Windows ?
1ère étape : téléchargement et installation
Quelles versions utiliser ? Aller sur le site de spark et vérifier les versions maximales, par exemple « Spark runs on Java 8/11, Scala 2.12/2.13, Python 3.6+ and R 3.5+ ».
– La première étape est d’installer Python 3 dans une version récente. Pour ma part j’utilise Python 3.9.10 car elle est compatible avec TensorFlow-GPU (nous verrons rapidement comment utiliser TensorFlow for Spark).
– Ensuite il faut installer Java JDK (ce qui installe en même temps le Java JRE) et valider son installation en saisissant dans une console Windows (pour ma part 8u321, la version 11 ne fonctionnant pas) : « java -version »
– Puis il faut télécharger Spark (ici 3.2.1) pour Hadoop sans Scala (option par défaut normalement) et le dézipper dans le dossier de son choix.
FACULTATIF : Dans le dossier de Spark, on peut changer les messages d’erreurs pour n’afficher que les erreurs (et éviter du spam). Aller dans le dossier « conf », dupliquer le fichier « log4j.properties.template » et le renommer en « log4j.properties ». Ouvrir le fichier puis changer la valeur de la variable « log4j.rootCategory » pour « ERROR, console ».
– Enfin, télécharger le fichier « winutils » (faire une recherche internet si la version hébergée sur le site est trop ancienne).
Dans le dossier spark (ou ailleurs), créer un dossier « winutils » puis un sous-dossier « bin » et dézipper le fichier à l’intérieur. Ce fichier permettra d’utiliser spark sur l’ordinateur Windows en mode local.
Exécuter les deux commandes Windows suivantes depuis le dossier bin via la console :
mkdir \tmp\hive
.\winutils.exe chmod 777 \tmp\hiveCette commande va créer un dossier « hive » dans le dossier « tmp » à la racine du disque et donner les droits d’écriture à winutils pour créer des fichiers temporaires liés au lancement de spark en local.
Voici les dossiers que vous devriez obtenir à la fin de toutes les installations :
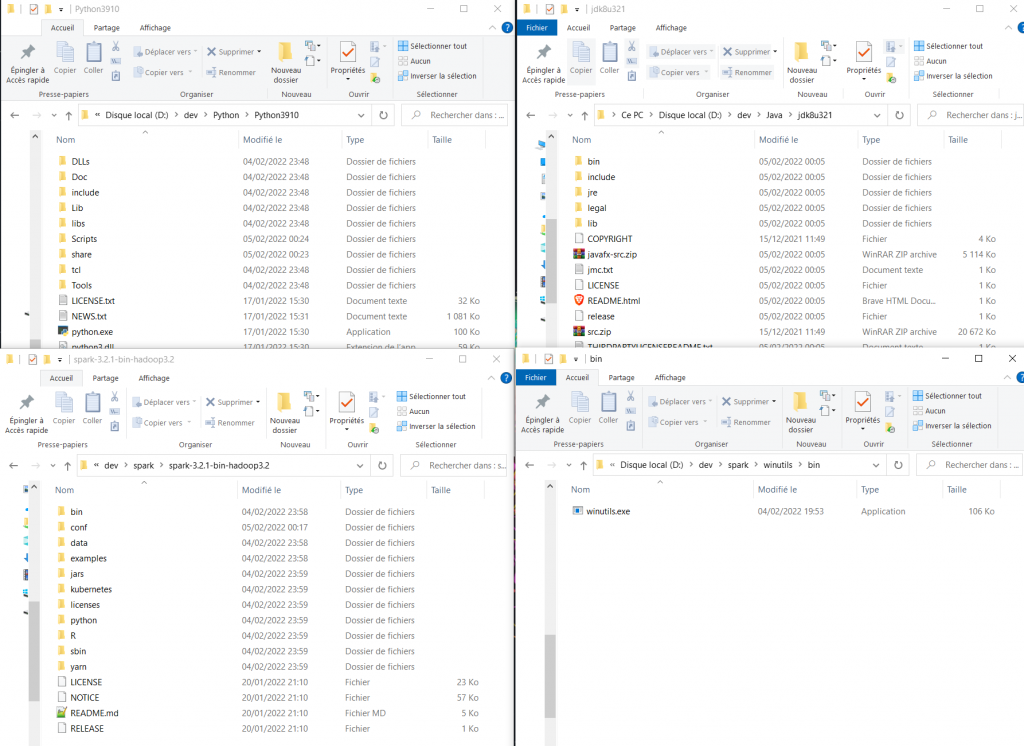
2ème étape : ajout au Path
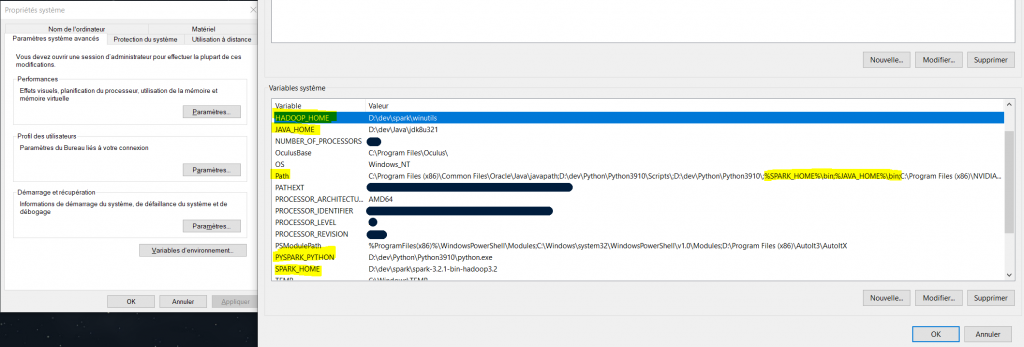
Dans les variables d’environnement Windows, créer une variable :
– SPARK_HOME
avec pour valeur le chemin du dossier de spark (dans mon cas : D:\dev\spark\spark-3.2.1-bin-hadoop3.2)
– JAVA_HOME
avec pour valeur le chemin du dossier java (dans mon cas : D:\dev\Java\jdk8u321)
– HADOOP_HOME
avec pour valeur le chemin du dossier winutils (dans mon cas : D:\dev\spark\winutils)
– PYSPARK_PYTHON
avec pour valeur le chemin vers le fichier python.exe (dans mon cas : D:\dev\Python\Python3910\python.exe)
Ensuite dans la variable « Path » ajouter :
%SPARK_HOME%\bin
%JAVA_HOME%\bin
Voici la configuration finale des variables d’environnement :
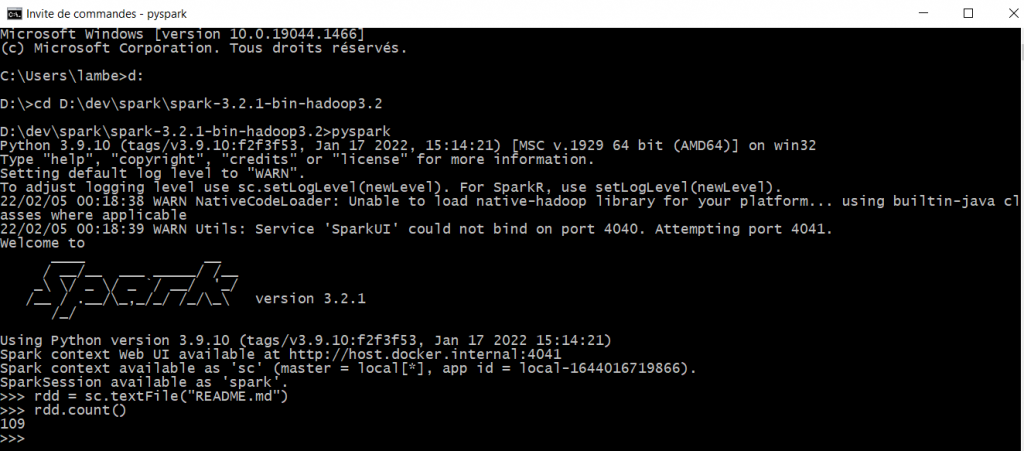
Vérification de l’installation
Ouvrir une console dans le dossier de SPARK_HOME et lancer la commande « pyspark ». Le logo de Spark devrait apparaître. Ensuite écrire les deux lignes suivantes (sous réserve qu’un fichier README.md existe dans le dossier de spark) :
rdd = sc.textFile("README.md")
rdd.count()Vous obtenez alors dans la console le nombre de lignes du fichier README.md, félicitations tout fonctionne !
Erreurs possibles :
Le chemin spécifié n’existe pas –> cette erreur au moment d’écrire « pyspark » dans la console est due à la version 11 de Java. Il faut installer une version 11 antérieure ou la version 8 de Java.
« Could not initialize class org.apache.spark.storage.StorageUtils$ » –> cette erreur au moment d’écrire « pyspark » dans la console est liée également à la version de Java (17 au lieu de 8 ou 11, cf les compatibilités).
Dernière étape : installer pyspark sous Python 3
Pour terminer ce tutoriel sur l’installation de Spark 3, il faut installer le module « pyspark ».
Dans une console, exécutez la ligne suivante : « pip install pyspark ».
Une fois l’installation réussie, on peut tester que tout fonctionne en ouvrant une console dans le dossier de SPARK_HOME puis en écrivant « python ».
Ensuite il faut exécuter le code suivant et obtenir en résultat le même nombre de lignes que précédemment !
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local").setAppName("TestPySpark")
sc = SparkContext(conf=conf)
rdd = sc.textFile("README.md")
rdd.count()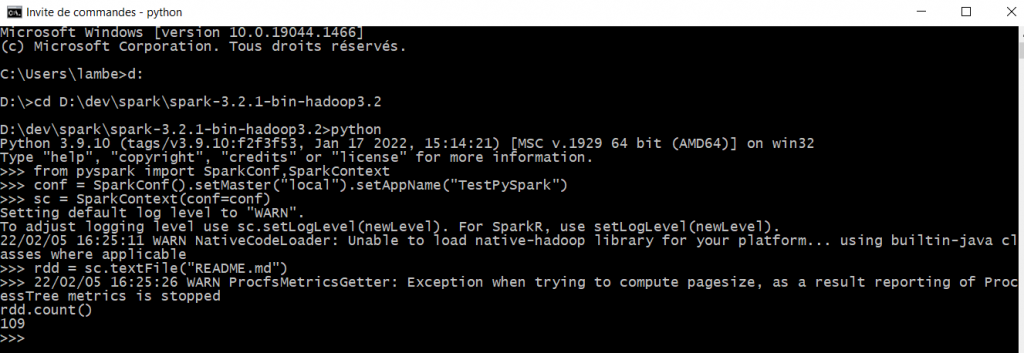
Crédit de l’image de couverture : Fabiano Rodrigues via Pexels – License Pexels



 ^^){kind=link}