
Ce projet avait deux objectifs principaux. Le premier consistait à construire un réseau neuronal convolutif (CNN) à partir de zéro. Une approche très élaborée a testé les effets de la modulation de divers paramètres sur la précision de la classification pour chaque couche ajoutée dans l’architecture CNN. Le deuxième objectif était de démontrer la puissance du transfer learning dans le contexte des tâches de computer vision. Le Transfer Learning est un outil précieux du deep learning qui permet aux individus d’accéder aux connaissances acquises à partir de modèles très complexes formés sur des millions d’images étiquetées. L’exécution de ces modèles peut prendre des semaines, même lorsque plusieurs GPU sont utilisés, donc ceci est impossible sur un PC ordinaire.
1. Introduction
L’année dernière, plus de 47 000 articles scientifiques ont été publiés dans le domaine de l’intelligence artificielle. Ce domaine a connu une évolution rapide du fait de sa contribution significative à l’échelle mondiale et individuelle. Au niveau mondial, l’IA est utilisée pour améliorer les secteurs de l’énergie, de l’agriculture et de l’éducation, pour en nommer quelques-uns. Au niveau individuel, l’IA est impliquée dans la plupart de nos vies quotidiennes, qu’il s’agisse d’un filtre anti-spam pour nos courriels ou d’une détection faciale sur nos téléphones.
Le secteur médical connaît également une formidable expansion de l’IA. Des appareils portables qui suivent notre santé en temps réel, jusqu’aux politiques gouvernementales influencées par le pouvoir prédictif des algorithmes informatiques modernes. Une autre application puissante de l’IA en médecine est le domaine de digital pathology. Dans ce domaine, computer vision est une branche dédiée à enseigner les ordinateurs à « voir ». Bien que nous puissions considérer la capacité de voir comme acquise en tant qu’êtres humains, enseigner aux ordinateurs à « voir » est un défi important et sera au centre de ce projet. Puisqu’il s’agit d’un projet axé sur computer vision, il semble approprié que les données utilisées impliquent de prévoir la cécité chez les patients diabétiques.
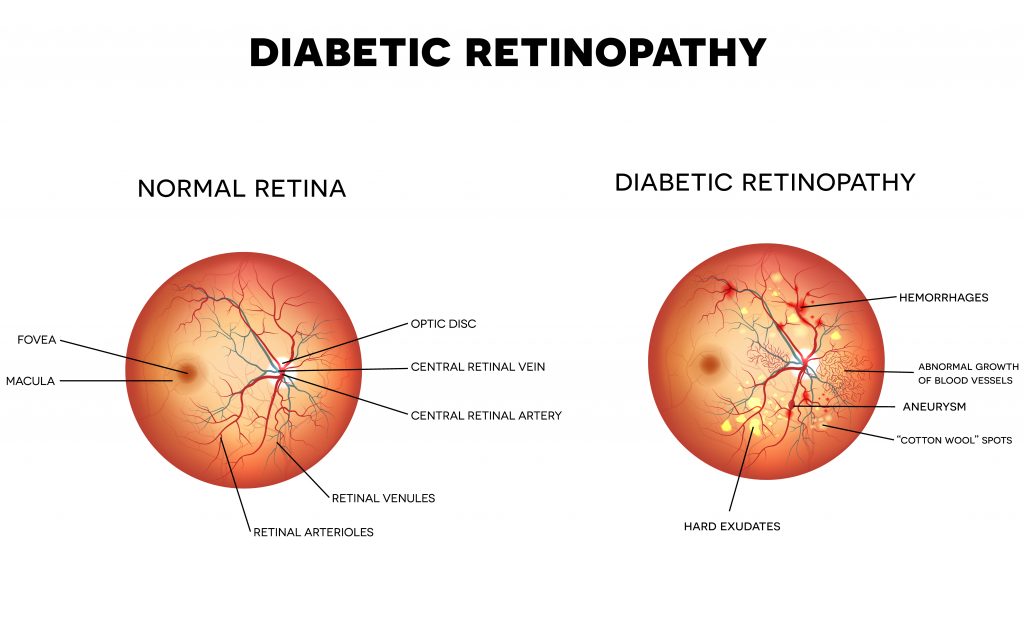
La rétinopathie diabétique (RD) est une affection qui se présente dans les patients atteints de diabète de type I ou II (figure 1). Au fil du temps, lorsque les niveaux de glucose dans le sang restent chroniquement élevés, les petits vaisseaux sanguins nourrissant l’œil sont endommagés. L’une des premières conséquences est que les parois des vaisseaux commencent à s’affaiblir, entraînant de petits renflements appelés anévrismes.
À mesure que la maladie progresse, ces renflements se rompent (hémorragie), entraînant une fuite de sang dans l’œil. Dans les stades ultérieurs, l’œil commence à développer de nouveaux vaisseaux pour compenser le flux sanguin réduit ; cependant, ces vaisseaux sanguins anormaux, en plus des fibres nerveuses locales, décomposent les lipides et les protéines qui fuient dans la région (cotton wool spots et exsudats durs). Enfin, aux stades les plus sévères, le tissu cicatriciel se développe et peut provoquer le décollement de la rétine de l’œil. En fin de compte, cela conduit à des dommages importants aux fibres nerveuses optiques et à la cécité (Mayo Clinic, 2018).
2. Méthodes
2.1 Environment
Tous les scripts ont été écrits en utilisant Python 3 sur un notebook Jupyter disponible sur le site Web de Kaggle. L’accès à un GPU NVIDIA Tesla K80 a été fourni, ce qui a augmenté la vitesse de formation de 12,5x selon les spécifications du site Web. Pour accéder au notebook complet, voici un lien vers mon Github.
2.2 Base de données
L’ensemble de données se composait de 3 662 images couleur haute résolution étiquetées pour l’ensemble d’apprentissage et 1 928 non-étiquetées pour l’ensemble d’essai. Les images ont été classées en 5 groupes en fonction de la gravité de la RD présente. L’étiquette 0 représente le groupe de référence. Les étiquettes 1 à 4 représentent respectivement une RD légère, modérée, sévère et proliférative. Un résumé visuel de la distribution des diagnostics se trouve ci-dessous (figure 2a).
Un déséquilibre clair de la taille des groupes est évident avec plus de 1 800 images représentant le groupe de référence (étiquette = 0) et moins de 300 dans la catégorie la plus sévère (étiquette = 4). Bien que ce déséquilibre soit attendu dans les données du monde réel, cela pose un problème pour de nombreux modèles machine learning. En plus des classes déséquilibrées, les images dans l’ensemble de données diffèrent en taille et en organisation spatiale (figure 2b). Les techniques utilisées pour atténuer les conséquences sont présentées dans la section 2.3.
#visualize distribution of diagnoses
g = sns.countplot(train_df['diagnosis'])
sns.despine()
train_df['diagnosis'].value_counts()
#example of images present in dataset
def display_samples(df, columns=2, rows=2):
fig=plt.figure(figsize=(5*columns, 4*rows))
for i in range(columns*rows):
image_path = df.loc[i,'id_code']
image_id = df.loc[i,'diagnosis']
img = cv2.imread(f'../input/aptos2019-blindness-detection/train_images/{image_path}.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
fig.add_subplot(rows, columns, i+1)
plt.title(image_id)
plt.imshow(img)
plt.tight_layout()
display_samples(train_df)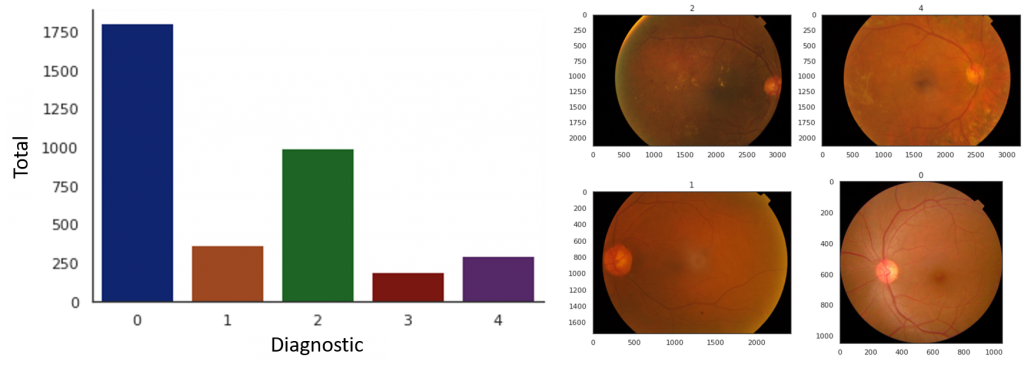
2.3 Prétraitement d’images
2.3.1 Redimensionnement
Lors de la définition de l’architecture du modèle, qui sera expliquée en détail dans une section suivante, l’une des conditions requises est de définir une dimension fixe des images. Lors de l’exécution de cette tâche, il est important de garder à l’esprit qu’il existe un équilibre entre la vitesse de calcul et la perte d’informations. Pour élaborer, lorsque vous réduisez la taille d’une image, vous supprimez des informations (pixels). Moins d’informations signifie des temps d’apprentissage plus rapides ; cependant, cela peut également signifier une précision globale réduite. Pour être compatible avec les modèles préformés utilisés pour transfer learning, une taille d’image de 224 x 224 a été sélectionnée.
#resizing images
def get_pad_width(im, new_shape, is_rgb=True):
pad_diff = new_shape - im.shape[0], new_shape - im.shape[1]
t, b = math.floor(pad_diff[0]/2), math.ceil(pad_diff[0]/2) # padding the top (t) and bottom (b) of images
l, r = math.floor(pad_diff[1]/2), math.ceil(pad_diff[1]/2) # padding the left (l) and right (r) of images
if is_rgb:
pad_width = ((t,b), (l,r), (0, 0))
else:
pad_width = ((t,b), (l,r))
return pad_width
def preprocess_image(image_path, desired_size=224): #choosing image size
im = Image.open(image_path)
im = im.resize((desired_size, )*2, resample=Image.LANCZOS)
return im2.3.2 Augmentation des données
Les groupes déséquilibrés est un problème courant dans machine learning. Lors de la formation de nos modèles, l’objectif est de constater une amélioration de la précision par rapport aux itérations (époques) suivantes. Lorsque la taille des groupes diffère considérablement, les groupes sous-représentés seront vus moins souvent et ne seront donc pas appris ainsi que leurs homologues surreprésentés. Pour atténuer les conséquences d’une surreprésentation ou d’une sous-représentation, l’augmentation des données est utilisée.
Il est important de noter que l’augmentation des données n’augmente pas le nombre d’échantillons d’apprentissage présents. En ajustant des paramètres spécifiques, des changements aléatoires sont appliqués aux images d’apprentissage originales. Ces modifications aléatoires sont appliquées à chaque époque, ce qui signifie que le modèle s’entraînera sur des images « différentes » à chaque itération. Le protocole utilisé pour ce projet a été sélectionné dans la liste complète disponible sur Keras. En résumé, une plage a été fournie pour les rotations aléatoires (jusqu’à 30 °) et le zoom (jusqu’à 10%). Les retournements horizontaux et verticaux ont également été utilisé.
import os
from keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
def generate_plot_pics(datagen,orig_img):
dir_augmented_data = "/kaggle/working/augmented_preview"
try:
# if the preview folder does not exist, create
os.mkdir(dir_augmented_data)
except:
# if the preview folder exists, remove
# the pictures in the folder
for item in os.listdir(dir_augmented_data):
os.remove(dir_augmented_data + "/" + item)
# convert the original image to an array
x = img_to_array(orig_img)
# reshape (sample, nrow, ncol, 3) where 3 = R,G,B (would be 1 for grey scale)
x = x.reshape((1,) + x.shape)
# randomly generate pictures
i = 0
Nplot = 8
for batch in datagen.flow(x,batch_size=1,
save_to_dir=dir_augmented_data,
save_prefix="pic",
save_format='png'):
i += 1
if i > Nplot - 1: # generate 8 pictures
break
# plot the generated data
fig = plt.figure(figsize=(8, 6))
fig.subplots_adjust(hspace=0.02,wspace=0.01,
left=0,right=1,bottom=0, top=1)
# original picture
ax = fig.add_subplot(3, 3, 1,xticks=[],yticks=[])
ax.imshow(orig_img)
ax.set_title("original")
i = 2
for imgnm in os.listdir(dir_augmented_data):
ax = fig.add_subplot(3, 3, i,xticks=[],yticks=[])
img = load_img(dir_augmented_data + "/" + imgnm)
ax.imshow(img)
i += 1
plt.show()
#rotation_range in degrees.
datagen = ImageDataGenerator(rotation_range=30)
generate_plot_pics(datagen,orig_img)
#zoom_range: Float or [lower, upper]. Range for random zoom.
#If a float, [lower, upper] = [1-zoom_range, 1+zoom_range].
datagen = ImageDataGenerator(zoom_range=0.1)
generate_plot_pics(datagen,orig_img)
#vertical flip
datagen = ImageDataGenerator(vertical_flip=True)
generate_plot_pics(datagen,orig_img)
#horizontal flip
datagen = ImageDataGenerator(horizontal_flip=True)
generate_plot_pics(datagen,orig_img)3. Résultats
3.1 Construire un réseau neuronal convolutif de zéro
3.1.1 Sélectionner les fonctions d’activations et d’optimisations
La première étape du processus de construction de mon CNN à partir de zéro a été de déterminer l’optimiseur et la fonction d’activation la plus performante pour la tâche de classification. Les sept optimiseurs ont chacun été testés pour leurs performances à l’aide des six fonctions d’activation utilisées pour la couche de classification. Chacun des 42 combinaisons a été testé sur un modèle de base composé de 3 couches alternées de convolution et de max pooling. Les filtres de convolution ont augmenté (16, 32, 64) avec chaque couche. La sortie de la couche finale introduite dans une couche dense puis dans la couche de classification.
Les fonctions d’activation pour toutes les couches cachées sont restées constantes avec relu. En résumé, la fonction d’activation softmax a surpassé le reste, tandis que les optimiseurs adam et adamax ont surpassé les autres. Bien qu’adamax a fonctionné légèrement mieux qu’adam, j’ai choisi de continuer avec adam. La raison pour laquelle j’ai choisi adam plutôt qu’adamax est due à la prévalence dans la littérature. En sélectionnant adam, qui est beaucoup plus courant, les résultats seront plus faciles à comparer avec d’autres modèles.
3.1.2 Détermination du nombre optimal de couches de convolution
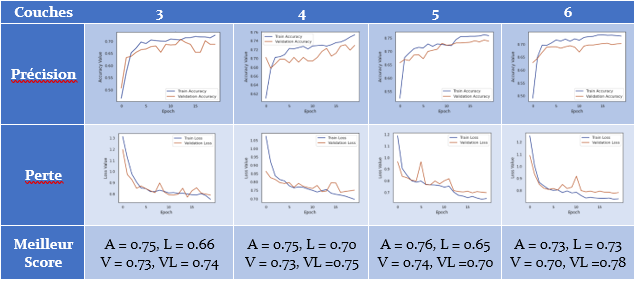
Après avoir sélectionné l’optimiseur et la fonction d’activation la plus performante, l’étape suivante consistait à déterminer le nombre de couches à ajouter dans la base de convolution. Les résultats des modèles contenant 3 à 6 couches de convolution sont présentés ci-dessous (tableau 1). Malgré des performances très similaires, le modèle à quatre couches semble présenter un avantage. Remarque dans les figures du tableau, à la fin du modèle à 4 couches, la précision et la perte semblent suggérer qu’avec des époques supplémentaires, une performance plus élevée serait attendue. Cela contraste avec les trois autres modèles qui semblent se stabiliser vers la fin de leurs essais respectifs.
3.1.3 Évaluation du rôle du kernel dans les performances du modèle
Avec un modèle aux performances décentes, l’influence de la taille du kernel a été évaluée. Les résultats comparant les kernel 3 x 3, 5 x 5 et 7 x 7 sont présentés ci-dessous (tableau 2). Les trois modèles ont fonctionné de manière similaire pour la précision et le score de perte. Visuellement, les kernel 3 x 3 et 7 x 7 semblent avoir une plus grande pente, ce qui suggère qu’il y aurait une augmentation des performances avec des époques d’apprentissage supplémentaires.
Vers la fin des essais avec les kernel 5 x 5, la précision et la perte semblent plafonner. De plus, les ensembles d’apprentissage et de validation semblent être divergents, ce qui indique que ce réseau commence à se surajuster. Finalement, le kernel 3 x 3 a été sélectionnée. Lors de la classification des images, ce sont généralement les petites caractéristiques locales qui seront les plus utiles pour distinguer une classe d’une autre.

3.1.4 Affiner le modèle à l’aide de dropout et batch normalization
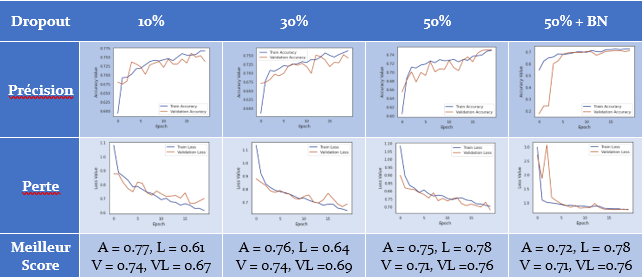
Jusqu’à présent, nous avons optimisé autant que possible le modèle de classification des images. Bien qu’il ne s’agisse pas d’un modèle exceptionnel, le fait qu’il fonctionne aussi bien sur les ensembles d’apprentissage et de validation suggère qu’il peut être généralisable. Bien que le modèle ne semble pas sur-ajusté, les manipulations du dropout (10%, 30%, 50%) et batch normalization ont été explorées pour voir si elles offraient un avantage en termes de performances. Ci-dessous, les résultats de ces essais sont résumés (tableau 3). Après inspection visuelle, les essais utilisant 10% et 30% dropout semblent diverger dans leurs ensembles respectifs d’apprentissage et de validation, ce qui n’était pas évident lorsque 50% dropout a été utilisé. Enfin, alors que batch normalization seule n’a eu aucun effet sur les performances du réseau, lorsque c’est associé à un dropout de 50%, une réduction significative de la variabilité entre les époques était évidente.
3.1.5 Résumé
Cette section a exploré les étapes de la construction d’un CNN à partir de zéro pour une tâche de computer vision multi-classification. En commençant par la sélection des fonctions d’activation non-linéaires et des optimiseurs, il a été déterminé que la fonction d’activation softmax combinée avec adam en tant qu’optimiseur fonctionnait le mieux. Ensuite, des couches de convolution et de max pooling alternées ont été ajoutées séquentiellement pour déterminer la meilleure architecture générale pour notre tâche. Il a été déterminé qu’une base de convolution à 4 couches surpassait les bases à 3, 5 et 6 couches.
Après avoir étudié les effets sur les performances de la taille du kernel sur le modèle de base, une fenêtre 3 x 3 a été sélectionnée pour l’extraction maximale des informations locales. Enfin, lorsque l’on compare les effets en utilisant batch normalization et une gamme de taux dropout (10 – 50%), c’est un taux de 50% qui semble démontrer les meilleures performances après inspection visuelle. La section 3.2 explorera transfer learning en comparant les modèles préformés VGG16, ResNet50 et Xception.
top_model = Sequential()
top_model.add(Conv2D(filters = 16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
top_model.add(MaxPooling2D(pool_size=(2, 2)))
top_model.add(Conv2D(filters = 32, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
top_model.add(MaxPooling2D(pool_size=(2, 2)))
top_model.add(Conv2D(filters = 64, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
top_model.add(MaxPooling2D(pool_size=(2, 2)))
top_model.add(Conv2D(filters = 128, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
top_model.add(MaxPooling2D(pool_size=(2, 2)))
top_model.add(Flatten())
top_model.add(Dense(512, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(5, activation='softmax'))
top_model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(),
metrics=['accuracy'])
top_model.summary()
history = top_model.fit_generator(
data_generator,
steps_per_epoch=x_train.shape[0] / batch_size,
epochs=epochs,
validation_data=(x_val, y_val),
callbacks=[#EarlyStopping(monitor = 'accuracy', patience=5, restore_best_weights=True),
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=4, verbose=0, mode='auto', min_delta=0.001, cooldown=0, min_lr=0)
]
)3.2 Transfer learning
La section suivante a exploré comment transfer learning peut être utilisé pour améliorer le succès du diagnostic pour les tâches de computer vision en utilisant deux techniques. Plus précisément, le premier a utilisé une technique appelée feature extraction en figeant les bases de convolution et en les entraînant soit avec une couche dense (dense à dropout à classifier) ou une couche de global average pooling (pooling à dropout à classifier). La deuxième technique, appelée fine-tuning, comparait les performances après avoir défigé les deux derniers blocs.
3.2.1 Feature extraction
Lorsque la technique utilisant la couche dense a été comparée à celle utilisant la couche de global average pooling, la première a donné des résultats significativement meilleurs pour les trois modèles préformés (tableau 4). Dans chaque cas, global average pooling n’a pas pu dépasser les résultats atteint avec le modèle que j’ai construit. Pour ceux qui utilisent une couche dense, ResNet50 et Xception avaient une plus grande précision ; cependant, ils surajustent de manière significative le modèle évident lorsque l’on compare les scores de validation et les pertes. Le VGG16 utilisant la couche dense était le seul modèle à éviter de surajuster les données, mais il n’était pas aussi performant que mon modèle. Vous trouverez ci-dessous un exemple de code pour charger et exécuter le modèle VGG16 (pour feature extraction)

#import vgg16 model
from keras.applications import VGG16
vgg16_base = VGG16(weights = 'imagenet', include_top = False, input_shape = input_shape)
vgg16_base.summary()
from keras import models
from keras import layers
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
#model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(layers.Dense(5, activation='softmax'))
model.summary()
#compile model
vgg16_model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(learning_rate=0.00005),
metrics=['accuracy'])
history = vgg16_model.fit_generator(
data_generator,
steps_per_epoch=x_train.shape[0] / batch_size,
epochs=epochs,
validation_data=(x_val, y_val),
callbacks=[#EarlyStopping(monitor = 'accuracy', patience=5, restore_best_weights=True),
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=4, verbose=0, mode='auto', min_delta=0.001, cooldown=0, min_lr=0)
]
)3.2.2 Fine-tuning le base de convolution
Contrairement aux résultats de la feature extraction, c’est la couche de global average pooling qui a surpassé la couche dense lorsque les deux blocs de convolution supérieurs ont été défigés (tableau 5). Tous les modèles utilisant une couche dense surajustent les données, comme évident dans la divergence des données d’apprentissage et de validation. Cela était également vrai pour ceux qui utilisent une couche de global average pooling, quoique dans une moindre mesure. Malgré cela, la plus grande précision a été observée avec ResNet50 en utilisant une couche dense, atteignant 94% de précision sur l’ensemble d’apprentissage et 82% sur l’ensemble de validation. Vous trouverez ci-dessous un exemple de code pour affiner les 2 dernières couches de convolution du modèle VGG16.

#unfreeze final 2 convolution blocks
vgg16_base.trainable = True
set_trainable = False
for layer in vgg16_base.layers:
if layer.name == 'block4_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
vgg16_model.compile(loss='categorical_crossentropy',
optimizer=optimizers.Adam(learning_rate=0.00005),
metrics=['accuracy'])
history = vgg16_model.fit_generator(
data_generator,
steps_per_epoch=x_train.shape[0] / batch_size,
epochs=epochs,
validation_data=(x_val, y_val),
callbacks=[#EarlyStopping(monitor = 'accuracy', patience=5, restore_best_weights=True),
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=4, verbose=0, mode='auto', min_delta=0.001, cooldown=0, min_lr=0)
]
)3.2.3 Résumé
Alors que feature extraction à l’aide des modèles préformés a entraîné une plus grande précision du modèle construit à partir de zéro, elles étaient sujettes à un surajustement significatif et fonctionnaient très mal sur l’ensemble de validation. Dans l’ensemble, les modèles utilisant la couche dense pour alimenter le classificateur ont nettement surperformé ceux utilisant une couche de global average pooling. Le réseau VGG16 était le seul à éviter de sur-ajuster les données ; cependant, il n’a pas pu fonctionner mieux que le modèle que j’ai construit dans la section 3.1. L’avantage du transfer learning devient évident lorsque les modèles préformés sont affinés. Tous les modèles ont surpassé mon modèle d’environ 5% en utilisant VGG16 à près de 20% en utilisant ResNet50 pour la précision.
3.3 Qu’a-t-on appris grâce au transfer learning?
Le but de ce projet était de démontrer l’utilité de transfer learning pour les tâches de computer vision. Alors que feature extraction était sujette à un surajustement des données et fonctionnait mal sur l’ensemble de validation, fine-tuning des modèles préformés a donné des résultats impressionnants. Le fait que feature extraction ait mal fonctionné ne devrait pas surprendre lorsque l’on considère la base de données sur laquelle VGG16, ResNet50 et Xception ont été formés.
Imagenet est une énorme base de données d’images, cependant, les images sont toutes des images de tous les jours telles que des animaux, des personnes, etc. Les poids des couches plus profondes de ces modèles représenteraient certainement des caractéristiques très différentes de celles présentes dans les images actuelles. En défigeant certains des couches ultérieurs, toutes les fonctionnalités généralisables les plus utiles ont été conservées.
La capacité d’exploiter la puissance et la profondeur disponibles à partir de modèles de pointe modifie actuellement le paysage médical. Une étude récente publiée dans Nature Digital Medicine, sur une tâche similaire à celle présentée ici, a rapporté une sensibilité de 97% en utilisant leur modèle deep learning, contre 74% pour les professionnels (opthamologues, infirmiers ophtalmologues et techniciens) avec > 2 ans d’expérience (Ruamviboonsuk et al., 2019). Au cours de la prochaine décennie, à mesure que les données d’images médicales deviendront plus disponibles, le domaine de la pathologie numérique explosera, ouvrant la voie au domaine émergent de la médecine personnalisée au niveau mondial.
Références
Mayo Clinic. (2018). Diabetic retinopathy. Retrieved from https://www.mayoclinic.org/diseases-conditions/diabetic-retinopathy/symptoms-causes/syc-20371611
Ruamviboonsuk, P., Krause, J., Chotcomwongse, P., Sayres, R., Raman, R., Widner, K., … Webster, D. R. (2019). Deep learning versus human graders for classifying diabetic retinopathy severity in a nationwide screening program. Nature Digital Medicine, 25(March), 9. https://doi.org/https://doi.org/10.1038/s41746-019-0099-8
Ressources utiles
Je tiens à remercier les auteurs trouvés dans le lien pour leur perspicacité et leur sagesse. J’ai tellement appris!
Jason Brownlee a d’excellents tutoriels sur pratiquement tout!
Je ne saurais trop recommander Andrew Ng. J’ai audité certains de ses cours sur Coursera et il est un des meilleur professeur sur le sujet. Il a également des vidéos YouTube si vous êtes intéressé.
Crédit de l’image de couverture : Bacila Vlad – Unsplash license



{kind=link}