L’intelligence artificielle est partout dans la presse. Le machine learning est partout dans les entreprises. Le deep learning est partout dans la recherche.
Quel est le lien entre ces trois disciplines, et surtout, qu’est-ce qui les différencie ?
L’intelligence artificielle
Historiquement, les débuts de l’IA remontent à Alan Turing dans les années 1950, et le mot veut tout dire et ne rien dire.
En effet, dans l’imaginaire commun, lorsqu’on parle d’intelligence artificielle, on désigne par là un programme qui peut effectuer des tâches d’humain, en apprenant toute seule. Or, l’IA telle que définie dans l’industrie est plutôt « des algorithmes plus ou moins évolués qui imitent des actions humaines ».
Par exemple, un programme qui nous dit si on est en surpoids (en lui donnant notre taille et poids), est une IA : l’utilisation de la logique IF… THEN… ELSE… dans un programme en fait une IA, sans qu’elle soit « réellement » intelligente. De la même manière, une machine de Turing est une IA.
A l’inverse, une intelligence artificielle forte (AGI) ou une superintelligence artificielle (ASI) sont totalement autonomes et auto-apprenantes (mais il n’en existe aucune à l’heure actuelle a priori) !
En résumé, si l’Intelligence Artificielle est un domaine très vaste qui regroupe en partie des algorithmes qui « ne font pas rêver », il y a aussi des algorithmes plus performants, notamment dans le machine learning.
une intelligence artificielle est un algorithme dont le résultat se veut un « minimum intelligent » (i.e. il doit ressembler à celui d’un expert humain)
Le machine learning
Partons d’un exemple simple : imaginons que vous vouliez créer une IA qui vous donne le prix d’un appartement à partir de sa superficie.
Dans les années 1950, vous auriez fait un programme du type « si la superficie est inférieure à 20m², le prix vaut 60 000€, si elle est entre 20m² et 30m², le prix vaut 80 000€, etc… », ou peut-être « prix = superficie*3 000 ».
Si vous avez un ami statisticien, il pourrait alors vous dire que ces approximations ne sont pas satisfaisantes, et qu’il suffirait de constater le prix de plein d’appartements dont on connait la superficie pour estimer le prix d’un nouvel appartement de taille non-référencée ! Votre ami vient de donner naissance au machine learning (qui est donc un sous-domaine de l’intelligence artificielle).
En effet, apparu dans les années 1980, le machine learning (ML) est l’application de méthodes statistiques aux algorithmes pour les rendre plus intelligents. L’enjeu du ML est bien de construire des courbes qui approximent les données et permettent de généraliser facilement. Il repose donc sur la capacité des algorithmes à recevoir beaucoup de données et à « apprendre » d’elles (i.e. corriger les courbes d’approximation) !
Le machine learning est un domaine large, qui comprend de très nombreux algorithmes. Parmi les plus célèbres, on retrouve :
- Les régressions (linéaires, multivariées, polynomiales, régularisées, logistiques…) : ce sont des courbes qui approximent les données (cf schéma ci-dessus)
- L’algorithme de Naïve Bayes : l’algorithme donne la probabilité de la prédiction, sachant les événements antérieurs. Par exemple, quel est le prix le plus probable sachant que l’appartement fait 43.7m².
- Le clustering : toujours grâce aux mathématiques, on va grouper les données en paquets de manière à ce que dans chaque paquet les données soient les plus proches possibles les unes des autres. C’est utilisé notamment pour des recommandations de films « proches » des films que vous avez déjà vus !
- Les arbres de décision : en répondant à un certain nombre de questions et en suivant les branches de l’arbre qui portent ces réponses, on arrive à un résultat (avec un score de probabilité)
- Ainsi que des algorithmes plus perfectionnés reposant sur plusieurs techniques de statistiques : Random Forest (une forêt d’arbres de décision qui votent), Gradient Boosting, Support Vector Machine…
ML = IA + STATS
le ML adapte son algorithme mais a besoin d’un expert pour les données
De ce qui vient d’être expliqué, on comprend pourquoi le ML est « l’IA auto-apprenante » : l’algorithme détermine lui-même quelle est la meilleure approximation des données, et ce n’est pas un humain qui dit « les coefficients de l’équation qui approxime les données sont 0.375, 174.83578563 et 283.2874 » (en général, c’est impossible pour un humain de trouver ces valeurs, car il y a trop de données à prendre en compte… tandis qu’une machine a « juste » à faire les calculs).
Le deep learning
En dépit de sa puissance, le ML pur a beaucoup de failles. La première est qu’un expert humain doit, au préalable, faire du tri dans les données.
Par exemple, pour notre appartement, si vous pensez que l’âge du propriétaire n’a pas d’incidence sur le prix, il n’y a aucun intérêt à donner cette information à l’algorithme, car si vous lui en donnez trop, il pourrait voir des relations là où il n’y en a pas…
Ensuite, la seconde (qui découle de la première) : comment faire pour reconnaître un visage ? Vous pourriez donner à l’algorithme plein d’informations sur la personne (écart entre les yeux, hauteur du front, etc…), mais ce ne serait pas très adaptatif ni précis.
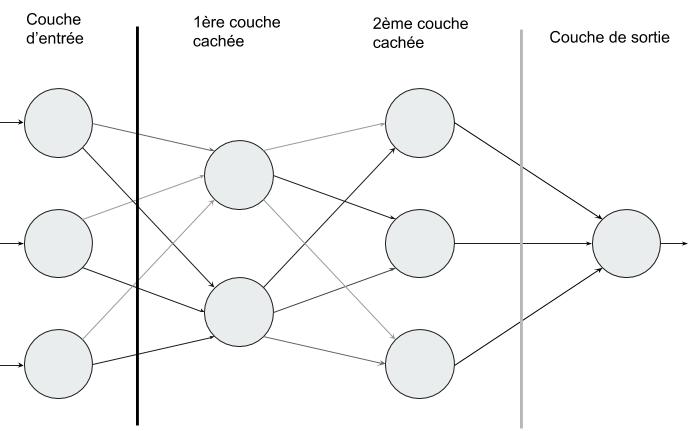
Ainsi est née l’idée du Deep Learning (DL) vers 2010 : s’inspirer de comment marche notre cerveau (avec des réseaux de neurones) pour pousser l’analyse plus loin et savoir extraire les données soi-même !
Le DL (qui est donc un sous-domaine du ML) repose donc sur ce qu’on appelle des réseaux de neurones artificiels (profonds), c’est-à-dire un ensemble de neurones (ce sont de petites calculatrices qui effectuent une opération mathématique) qui s’envoient des nombres en fonction de leurs liaisons, jusqu’à des neurones de sortie (en général !). Grâce à cette architecture, le DL est capable de reconnaître des visages, de synthétiser des textes ou encore de conduire une voiture autonome !
Vous avez du mal à voir où sont les statistiques dans tout ça ? En fait, l’algorithme va adapter les liaisons entre ses neurones (il va les renforcer ou les détruire), pour qu’en sortie on ait une bonne approximation des données d’entrée. Par exemple, dans un réseau qui aura appris à prédire le prix d’un appartement, si on donne en entrée « 20 », alors en sortie on aura un nombre très proche de « 60 000 ».
Voici quelques exemples d’algorithmes de deep learning :
- les réseaux de neurones artificiels (ANN) : ce sont les plus simples et sont souvent utilisés en complément car ils trient bien les informations
- les réseaux de neurones convolutifs (CNN) : spécialisés dans le traitement de l’image, ils appliquent des filtres à des données pour en faire ressortir de nouvelles informations (par exemple, faire ressortir les contours dans une image peut aider à trouver où est le visage)
- les réseaux de neurones récurrents (RNN) : les plus connus sont les LSTM, qui ont pour faculter de retenir de l’information et de la réutiliser peu après. Ils servent pour l’analyse de texte (NLP), puisque chaque mot dépend des quelques mots précédents (pour que la grammaire soit correcte)
- Ainsi que des versions plus avancées, comme les auto-encoders, les machines de Boltzmann, les self-organizing maps (SOM)…
En conclusion sur le deep learning, il permet de se passer d’un expert humain pour faire le tri dans les données, puisque l’algorithme trouvera de lui-même ses corrélations. Pour reprendre l’exemple de la reconnaissance faciale, l’algorithme de DL déterminera de lui-même s’il doit tenir compte de l’écart entre les yeux (entre les pixels) ou si cette information n’est pas assez déterminante comparée à d’autres (et c’est effectivement le cas).
DL = ML + Réseaux de neurones
le DL extrait l’information pertinente des données et adapte son algorithme
Le DL est du ML utilisé avec des réseaux de neurones. Le ML est de l’IA reposant sur des statistiques. L’IA est l’imitation d’une réponse d’un expert dans un domaine.
Et l’apprentissage par renforcement dans tout ça ?
Dernier point, qui ne fait plus partie de l’article : il est une méthode d’apprentissage dite « par renforcement » qui est utilisée sur certains algorithmes pour permettre, notamment, à un voiture d’apprendre à conduire toute seule par la pratique. C’est ce type d’apprentissage qui a aussi permis à Google DeepMind de gagner aux échecs.
Crédit de l’image de couverture : Lambert Rosique



{kind=link}