
IA pour les échecs et le GO, robots équilibristes ou drones, IA dans les jeux vidéos… l’apprentissage par renforcement vient de faire un bon de géant, avec la publication assez récente de l’algorithme « Augmented Random Search » alias ARS, par l’Université de Berkeley (Californie).
Quinze fois plus rapide que les anciens algorithmes, ARS permet par exemple au MuJoCo (les pantins virtuels qui doivent courir et sauter) d’apprendre par eux-même en des temps records !
Le plus étonnant ? C’est l’algorithme le plus simple et le plus basique de toute cette branche de l’IA !
Comme à notre habitude, nous verrons ensemble les tenants et les aboutissants de cette révolution, puis nous mettrons en place l’algorithme sur nos ordinateurs.
Qu’est-ce que l’apprentissage par renforcement ?
L’apprentissage par renforcement est une famille d’algorithmes de Machine Learning dont la particularité est d’explorer son environnement plutôt que d’avoir des données à ingérer.
Typiquement, une IA de cette famille qui jouerait à Mario sur émulateur se serait entraînée ainsi :
- première partie : l’IA ne connait absolument rien, excepté les actions qu’elle peut faire (aller à gauche/droite et sauter). Par contre, elle a un « feedback » sur son environnement et perçoit donc les ennemis, les objets, sans savoir ce qu’ils signifient. Elle meurt donc instantanément.
- après quelques parties : l’IA se rend compte qu’en se déplaçant vers la droite elle a un meilleur score final (elle est plus proche de l’arrivée), mais ne reconnait toujours pas les ennemis. Elle observe l’effet de ses actions sur son environnement.
- après encore plusieurs parties : l’IA sait qu’elle doit éviter les ennemis (car sinon son score sera moyen), qu’elle doit prendre les bonus, sauter au-dessus du vide… Elle a adaptée sa stratégie de déplacement à ce qu’elle a appris des conséquences de ses actions !
A l’inverse, pour les autres familles du machine learning, on aurait dû lui donner des exemples (apprentissage supervisé) :
- si tu vas vers la droite alors qu’il y a un ennemi, tu perds
- si tu sautes en avant alors qu’il y a un trou, tu perds
- si tu détectes un bonus au-dessus de toi et que tu sautes, tu gagnes des points
On voit donc que la charge de programmation humaine n’est pas la même, et il est très difficile d’être exhaustifs dans le second cas, ce qui fait du renforcement la méthode la plus adaptée à la programmation de robots autonomes, qui sauront réagir et s’adapter à toute situation nouvelle !
Voici une petite vidéo de ces fameux MuJoCo (MUlti-JOint dynamics with COntact), où l’IA observe l’effet de ses actions et adapte sa stratégie de déplacement en fonction de ce qu’elle a appris pour atteindre le bout de la carte.
L’augmented random search, 15 fois plus rapide que les algorithmes classiques !
On a vu que l’apprentissage par renforcement est très puissant… mais on devine aussi pourquoi il n’est pas du tout performant.
En effet, pour mesurer l’effet d’une action sur son environnement, l’IA a besoin de la répéter des milliers de fois dans des milliers de situations différentes. Or, pour arriver à certaines situations, cela peut demander du temps.
Par exemple, si le premier gouffre dans Mario n’est présent qu’au bout de 10 minutes de jeux, il faudra que l’IA aille s’y confronter plusieurs fois avant d’optimiser sa technique de saut en longueur ! Cela va donc demander des semaines d’entraînement… Comme pour les robots de Boston Dynamics, qui sont entraînés d’abord virtuellement (pour gagner du temps et rencontrer plus de situations, cf la vidéo en lien) puis dans le monde réel.
C’est là qu’intervient Augmented Random Search, l’algorithme élaboré par Horia Mania, Aurelia Guy et Benjamin Recht du département EECS de l’Université de Californie Berkeley : de design extrêmement simple, il apprend aussi bien que les algorithmes habituels (par exemple, ceux de Q-Learning ou l’A3C) en 15 fois moins de temps !
Si on s’en réfère au document de l’équipe, ARS trouve plus rapidement la solution à un environnement (par exemple, sauter ou nager) que les autres algorithmes de reinforcement learning testés, tout en restant assez stable (dépendance en ses paramètres de départ), et avec une politique d’apprentissage différente des autres : au lieu d’apprendre les conséquences de chaque action, ARS n’apprend qu’après un ensemble d’actions. On parle d’algorithme dans l’espace des « policies » (qui signifie la stratégie globale qu’adopte l’IA) plutôt que dans l’espace des actions.
Comment marche l’ARS ?
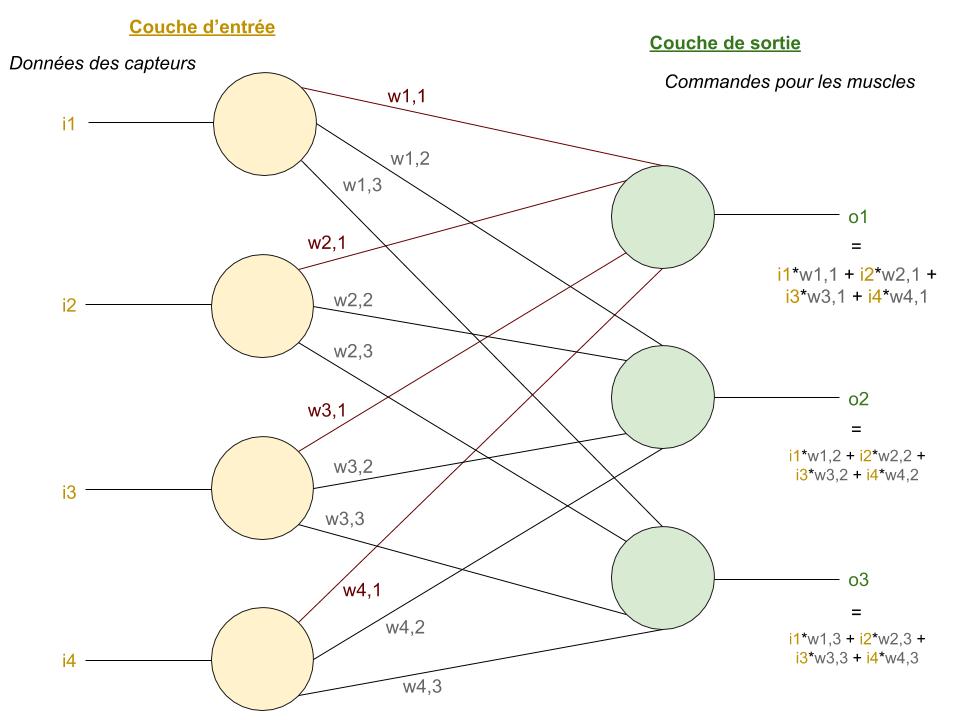
Architecture de l’augmented random search
Si vous avez lu nos autres focus, vous connaissez déjà l’architecture de l’ARS : il s’agit d’un réseau de neurones artificiels (ANN) à 1 couche d’entrée 0 couches cachées et 1 couche de sortie !
- La couche d’entrée a autant d’entrées qu’il y a de capteurs de l’environnement. Par exemple, pour le MuJoCo, l’IA a des retours sur la force exercée sous ses pieds (donc s’ils touchent le sol, etc…)
- La couche de sortie, qui est l’action que doit faire chaque muscle du MuJoCo (force de contraction…)
Il n’y a aucune fonction d’activation, ce qui fait que la sortie est la somme pondérée (par les poids des liaisons entre les neurones) des entrées. Cependant, pour la mise à jour des poids dans la phase d’apprentissage, nous n’utiliserons pas la descente de gradient mais… la méthode des différences finies.
Et voilà ! On vous l’avait dit, ARS est un algorithme très étonnant car une architecture aussi simple, a priori, ne devrait pas pouvoir fonctionner. En effet, cela signifie qu’une relation linéaire (i.e. de la forme a*x1 + b*x2 + c*x3 +…) entre les neurones contrôlant les muscles permet à un corps de courir, de sauter, et de se déplacer totalement dans un environnement complexe !
Comment apprendre ? Au hasard avec la méthode des différences finies !
Habituellement, un ANN apprend en calculant l’erreur qu’il a commise pour un exemple donné et en regardant l’impact des poids (liaisons entre les neurones) sur cette erreur : il s’agit de la descente de gradient (calcul de la dérivée partielle de l’erreur par rapport à un poids donné).
Or, ici l’ARS fait beaucoup plus simple (pour simplifier, on n’a gardé dans le schéma que les poids associés aux neurones de sortie o1 et o2, mais dans la pratique il y aura aussi o3 !) :
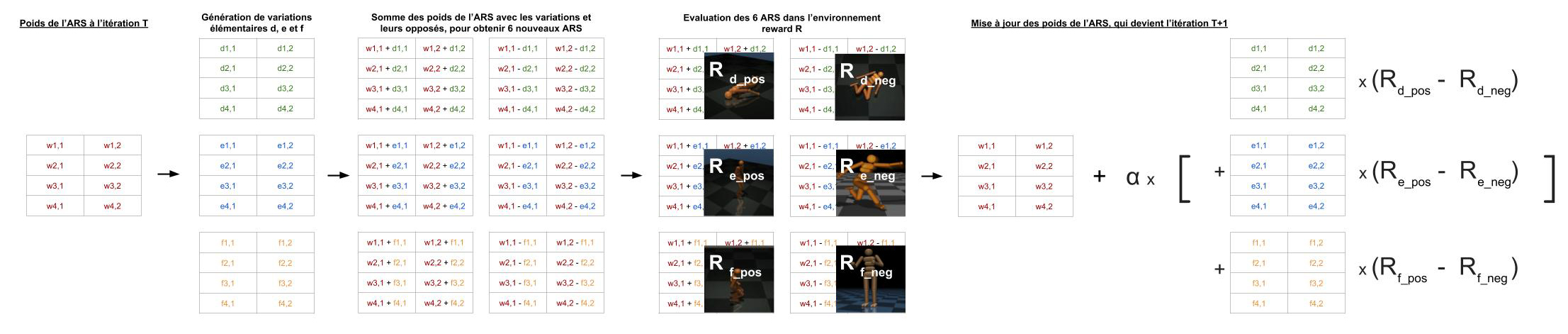
- Pour chaque poids du réseau, on génère 3 nombres proches de zéro
- Ensuite on crée 6 ARS en calculant les poids du réseau plus les premiers nombres générés, les poids moins les premiers nombres générés, puis pareil avec les seconds nombres et les troisièmes nombres.
- Pour chacun de nos 6 ARS (liés à 3 matrices de variations notées d, e, f ci-dessus), on lance la simulation et regarde quelle est la reward finale (la « note » de la prestation de l’IA). Ces 6 ARS sont appelés les « directions », car on cherche comment modifier les poids (dans quelle direction aller) pour que l’IA s’améliore.
Remarque : dans la pratique, on utilise 16 directions (soit 8 matrices de variations).
- Ensuite on met à jour l’ARS de départ en fonction des résultats de nos tests avec les 6 ARS : à chaque fois, on va ajouter aux poids la variation multipliée par l’écart entre sa version positive et sa version négative. Le tout sera multiplié par un coefficient de normalisation (détaillé dans la partie ARS vs BRS).
Explication : cela peut paraître étrange d’ajouter la différence, puisqu’on pourrait se dire que si la reward pour une variation (positive ET négative) est très élevée, ça veut dire que l’IA se débrouille beaucoup mieux. C’est bien le cas, en effet, mais si les deux sont élevés et proches (en valeur absolue), ça veut aussi dire que l’on ne sait pas dans quelle direction partir (on est sur une arête de la courbe de rewards). Ne pouvant décider de quel côté aller, on restera « entre les deux » jusqu’à trouver une direction qui ne fait aucun doute. D’où la différence entre les rewards positives et négatives, qui permet d’éviter de se disperser.
Remarque : une fois encore, dans la pratique, on préfère ne pas garder les 8 couples de variations mais seulement les 4 meilleurs (ceux dont l’écart entre reward positive et reward négative est le plus grand)
Comme vous le voyez, l’optimisation de notre IA (son entraînement) se fait en testant aléatoirement d’autres IA très proches et en ne gardant les conseils que de celles qui sont meilleures.
Pourquoi parle-t-on de version augmentée ? Quelle est la différence entre ARS et BRS ?
BRS pour « basic random search », la version de base d’ARS sans les petites augmentations ne présente que trois différences avec ARS (qui existe donc en version 1 et 2, améliorées en 1-t et 2-t : en général, ARS désigne la version finale complète qui est 2-t) sur lesquelles nous allons revenir ici.
1. Multiplication du coefficient \(\alpha\) par l’inverse de « l’écart type entre les rewards » (standard deviation en anglais)
Explication : notre coefficient \(\alpha\) est plus ou moins le learning rate de l’algorithme. Or, les rewards obtenues par les différents ARS peuvent varier considérablement. Par exemple aux premières itérations la reward peut être de -10, et plus tard de +800. Ces valeurs intervenant dans la mise à jour des poids, le learning rate est censé contrôler la grandeur de laquelle vont évoluer les poids… mais comme il peut y avoir des facteurs 1000 entre rewards, on voit que le learning rate seul ne suffit pas, et que nos poids risquent d’être mis à jour (cela a généralement un impact négatif sur l’algorithme) d’un grand nombre subitement !
La division par l’écart type permet de normaliser les rewards et donc de ne pas subir de telles variations dans l’apprentissage.
2. Normalisation des états à la volée
Le principe est le suivant : dans notre réseau, il arrive des états (mesurés par les capteurs) dans les neurones i1, i2, i3… Si on ne normalise pas ces états, la même chose que pour la mise à jour des poids risque de se produire : à un moment, un capteur va envoyer une valeur très élevée par rapport aux autres capteurs, ce qui va avoir une réponse tragique en sortie (des sorties qui habituellement ne s’activent pas trop vont avoir des valeurs élevées et induire un comportement incohérent).
Il faut donc normaliser les entrées, comme dans tous les algorithmes de machine learning (on parle de data preprocessing), mais puisqu’on ignore quelles sont les valeurs extrêmes des différentes entrées, il faut garder en mémoire quelles sont ces valeurs maximales et les utiliser pour normaliser.

3. Conservation des meilleures directions : celles dont l’écart entre les rewards positives et négatives est le plus élevé. On gardera par exemple le top 4 (4 écarts donc 8 directions)
Cette modification améliore la vitesse de convergence de l’ARS puisque la mise à jour des poids se fait dans la direction moyenne de toutes les directions explorées (et on enlève les directions peu intéressantes).
Implémentation de l’ARS en Python grâce à gym et pybullet
L’ARS commande ce guépard pour le faire courir à droite de l’écran. Le déplacement n’est pas encore optimal après seulement 100 itérations (mais est atteint en moins d’une heure !)…
Dans cette partie nous allons voir ensemble comment entraîner l’ARS pour faire courir un guépard en 2D (half-cheetah en anglais) vers la droite de l’écran, sans avoir rien à programmer en rapport avec la course.
Le code fournit dans ce tutoriel celui présenté par Hadelin de Ponteves dans le tutoriel Udemy : Artificial Intelligence 2018: Build the Most Powerful AI par SuperDataScience, car il est très clair et concis. On vous recommande d’aller y faire un tour, leurs cours sont parmi les plus influents et mieux notés de la plateforme (à juste titre) ! Le code ne nous appartenant pas, il ne sera exceptionnellement pas déposé sur Github.
Remarque : le code est donné directement dans les parties, car il s’agit vraiment de la retranscription en Python du contenu de la publication de Berkeley. Ceci étant, rien ne vous empêche d’essayer d’écrire votre propre V2 de l’ARS puis de comparer votre code à celui-ci !
Préparation de l’environnement
Nous n’aurons pas besoin de grand chose cette fois-ci.
Commencez par installer Python 3 si ce n’est pas déjà fait, en l’ajoutant au Path. Prenez bien la version 64 bits si votre ordinateur le permet (attention, le lien pointe vers Windows).
Ensuite nous allons installer deux librairies :
- gym et pybullet qui sont deux librairies importantes lorsque l’on fait de l’apprentissage par renforcement, car elles contiennent de nombreux utilitaires ainsi que tout un tas d’environnements possibles : 2600 jeux d’Atari, des routes avec des voitures, des fusées à faire atterrir, des équilibristes et pendules, des chariots, des bras/mains robotisés mais surtout des mujoco dont le guépard, l’insecte, le sauteur, l’humanoïde, le nageur et le marcheur !
Remarque : il existe aussi « MuJoCo » qui permet de créer des environnements réalistes avec une physique, mais il est payant donc nous ne nous en servirons pas.
Ouvrez une invite de commande et saisissez :
pip install gym==0.10.5 pip install pybullet==2.0.8
Attention : nous n’utiliserons pas les dernières versions pour des raisons de compatibilité.
Remarque : si jamais les vidéos par la suite ne fonctionnent pas, vous pouvez essayer l’une des trois techniques ci-dessous.
- Utiliser Anaconda3 pour votre environnement Python et saisir la commande suivante
conda install -c conda-forge ffmpeg
- Installer ffmpeg directement dans Python et de le lire avec du Python
pip install ffmpeg-python
Les imports
Créez un simple fichier Python : il contiendra la totalité du code de l’ARS.
Sans surprise, nos imports contiendront gym et pybullet, ainsi que « os » pour créer les répertoires de sauvegarde des vidéos et numpy pour travailler sur les vecteurs :
# Importing the libraries import os import numpy as np import gym from gym import wrappers import pybullet_envs
Les hyper-paramètres
Ensuite, nous allons créer une classe dans laquelle nous placerons tous les hyper-paramètres de notre réseau de neurones. En particulier, on aura la vitesse d’apprentissage (learning rate), le nombre de directions à explorer ainsi que le nombre de meilleures directions à conserver (16), et le nom de l’environnement pour qu’il puisse démarrer « HalfCheetahBulletEnv-v0 ».
# Setting the Hyper Parameters
class Hp():
def __init__(self):
self.nb_steps = 1000
self.episode_length = 1000
self.learning_rate = 0.02
self.nb_directions = 16
self.nb_best_directions = 16
assert self.nb_best_directions <= self.nb_directions
self.noise = 0.03
self.seed = 1
self.env_name = 'HalfCheetahBulletEnv-v0'
Le normalizer
On l’a abordé dans la présentation de l’algorithme : le « normalizer » aura pour rôle de calculer à chaque itération la moyenne et l’écart-type pour pouvoir normaliser les états. N’hésitez pas à consulter le papier de l’ARS, à partir duquel toutes les idées du code peuvent être retrouvées.
# Normalizing the states
class Normalizer():
def __init__(self, nb_inputs):
self.n = np.zeros(nb_inputs)
self.mean = np.zeros(nb_inputs)
self.mean_diff = np.zeros(nb_inputs)
self.var = np.zeros(nb_inputs)
def observe(self, x):
self.n += 1.
last_mean = self.mean.copy()
self.mean += (x - self.mean) / self.n
self.mean_diff += (x - last_mean) * (x - self.mean)
self.var = (self.mean_diff / self.n).clip(min = 1e-2)
def normalize(self, inputs):
obs_mean = self.mean
obs_std = np.sqrt(self.var)
return (inputs - obs_mean) / obs_std
L’IA augmented random search
On construit à présent le coeur de l’IA, la partie dans laquelle une police est appliquée.
Par exemple, si on note « theta » la matrice des poids (liaisons entre les neurones), alors le produit de theta par « input » sera l’output de l’IA. On crée aussi les méthodes pour évaluer les poids perturbés dans une direction précise (positive ou négative) et celle générer des perturbations aléatoires. Enfin, on crée la méthode de mise à jour du réseau.
# Building the AI
class Policy():
def __init__(self, input_size, output_size):
self.theta = np.zeros((output_size, input_size))
def evaluate(self, input, delta = None, direction = None):
if direction is None:
return self.theta.dot(input)
elif direction == "positive":
return (self.theta + hp.noise*delta).dot(input)
else:
return (self.theta - hp.noise*delta).dot(input)
def sample_deltas(self):
return [np.random.randn(*self.theta.shape) for _ in range(hp.nb_directions)]
def update(self, rollouts, sigma_r):
step = np.zeros(self.theta.shape)
for r_pos, r_neg, d in rollouts:
step += (r_pos - r_neg) * d
self.theta += hp.learning_rate / (hp.nb_best_directions * sigma_r) * step
Entraînement de l’ARS
On crée dans cette partie la méthode qui aura en charge de tester les 16 ARS générés puis de déterminer les valeurs à appliquer pour mettre à jour les poids du réseau (dans la partie sur l’IA, juste avant).
# Training the AI
def train(env, policy, normalizer, hp):
for step in range(hp.nb_steps):
# Initializing the perturbations deltas and the positive/negative rewards
deltas = policy.sample_deltas()
positive_rewards = [0] * hp.nb_directions
negative_rewards = [0] * hp.nb_directions
# Getting the positive rewards in the positive directions
for k in range(hp.nb_directions):
positive_rewards[k] = explore(env, normalizer, policy, direction = "positive", delta = deltas[k])
# Getting the negative rewards in the negative/opposite directions
for k in range(hp.nb_directions):
negative_rewards[k] = explore(env, normalizer, policy, direction = "negative", delta = deltas[k])
# Gathering all the positive/negative rewards to compute the standard deviation of these rewards
all_rewards = np.array(positive_rewards + negative_rewards)
sigma_r = all_rewards.std()
# Sorting the rollouts by the max(r_pos, r_neg) and selecting the best directions
scores = {k:max(r_pos, r_neg) for k,(r_pos,r_neg) in enumerate(zip(positive_rewards, negative_rewards))}
order = sorted(scores.keys(), key = lambda x:scores[x], reverse = True)[:hp.nb_best_directions]
rollouts = [(positive_rewards[k], negative_rewards[k], deltas[k]) for k in order]
# Updating our policy
policy.update(rollouts, sigma_r)
# Printing the final reward of the policy after the update
reward_evaluation = explore(env, normalizer, policy)
print('Step:', step, 'Reward:', reward_evaluation)
Appel de toutes les classes et méthodes créées
Pour finir, on appelle tout le code écrit dans un enchaînement logique et simple. Comme vous allez le voir, gym/pybullet intègre directement les données des capteurs dans les input du réseau et est capable de générer l’environnement suivant à partir des outputs ! Aucune ligne de code n’a été à écrire, ce qui montre bien la puissance de ces librairies et leur utilité !
Dans le dossier monitor, vous trouverez des vidéos au fil des itérations : vous verrez que votre IA s’améliore, partant de « je tombe et ne me relève plus dès le départ » à « je gambade avec aisance ».
monitor_dir = 'monitor'
if not os.path.exists(monitor_dir ):
os.makedirs(monitor_dir )
hp = Hp()
np.random.seed(hp.seed)
env = gym.make(hp.env_name)
env = wrappers.Monitor(env, monitor_dir, force = True)
nb_inputs = env.observation_space.shape[0]
nb_outputs = env.action_space.shape[0]
policy = Policy(nb_inputs, nb_outputs)
normalizer = Normalizer(nb_inputs)
train(env, policy, normalizer, hp)
Bravo ! Avec ce dernier bout de code vous avez terminé l’implémentation de l’augmented random search. Ce n’est pas la version la plus optimisée qui soit, mais elle fonctionne très bien. N’hésitez pas à la tester maintenant avec d’autres environnements et à partager vos résultats.
Conclusion
L’augmented random search est vraiment un algorithme fascinant, de par sa simplicité et des questions philosophiques qu’il peut soulever.
Ceci étant, nous avons vu comment il marche (c’est un réseau de neurones artificiels classique, sans couche cachée, qui apprend en essayant au hasard d’autres configurations assez proches) puis nous l’avons mis en place pour faire courir notre half-cheetah sur notre ordinateur en quelques dizaines de minutes seulement !
Crédit de l’image de couverture : MuJoCo.org



{kind=link}