
« Le langage est la peinture de nos idées. » disait Antoine de Rivarol. Avec l’avènement des interfaces Homme-machine (BCI), bon nombre d’appareils connectés tels que nos smartphones ou enceintes intelligentes communiquent avec nous via la parole. On peut citer en matière de synthèse vocale Siri de Apple, Cortana de Microsoft, Alexa d’Amazon ou encore Ok Google… Malheureusement un grand nombre de maux peuvent altérer voire supprimer notre capacité à « peindre nos idées » : affections directes des cordes vocales (cancer, accident), mais aussi neuropathies, déficits neurologiques (AVC) ou maladies neurodégénératives (SLA)… La perte de la parole engendre une coupure avec l’entourage, ce qui a des effets dévastateurs sur le plan psychologique. Des systèmes de synthèse vocale existent bien aujourd’hui, un des plus connus étant celui de Stephen Hawking. Cela dit, il ne lui permettait que de sélectionner des caractères sur un clavier grâce à un capteur au niveau d’un muscle de sa joue, et cela est long et demande de la concentration et de l’énergie à la personne.
Une synthèse vocale à partir de la pensée: comment procéder?

Et pourquoi ne pas directement accéder à nos pensées ? Pouvoir outrepasser la barrière mécanique du corps pour accéder sans détour à nos idées ! Pour la première fois, des neuroingénieurs de l’Université de Columbia, New York, ont créé un système qui interprète les idées en un langage intelligible. La reconstruction de stimulus auditif permet de reproduire le son proposé à partir de l’activité neuronale associée.
Lorsque l’on parle, que l’on écoute quelqu’un parler ou que l’on s’imagine en train de parler, des motifs d’activités neuronales bien distincts peuvent être mesurés. En enregistrant de telles données, on pourrait ainsi générer les mots qui sont imaginés.
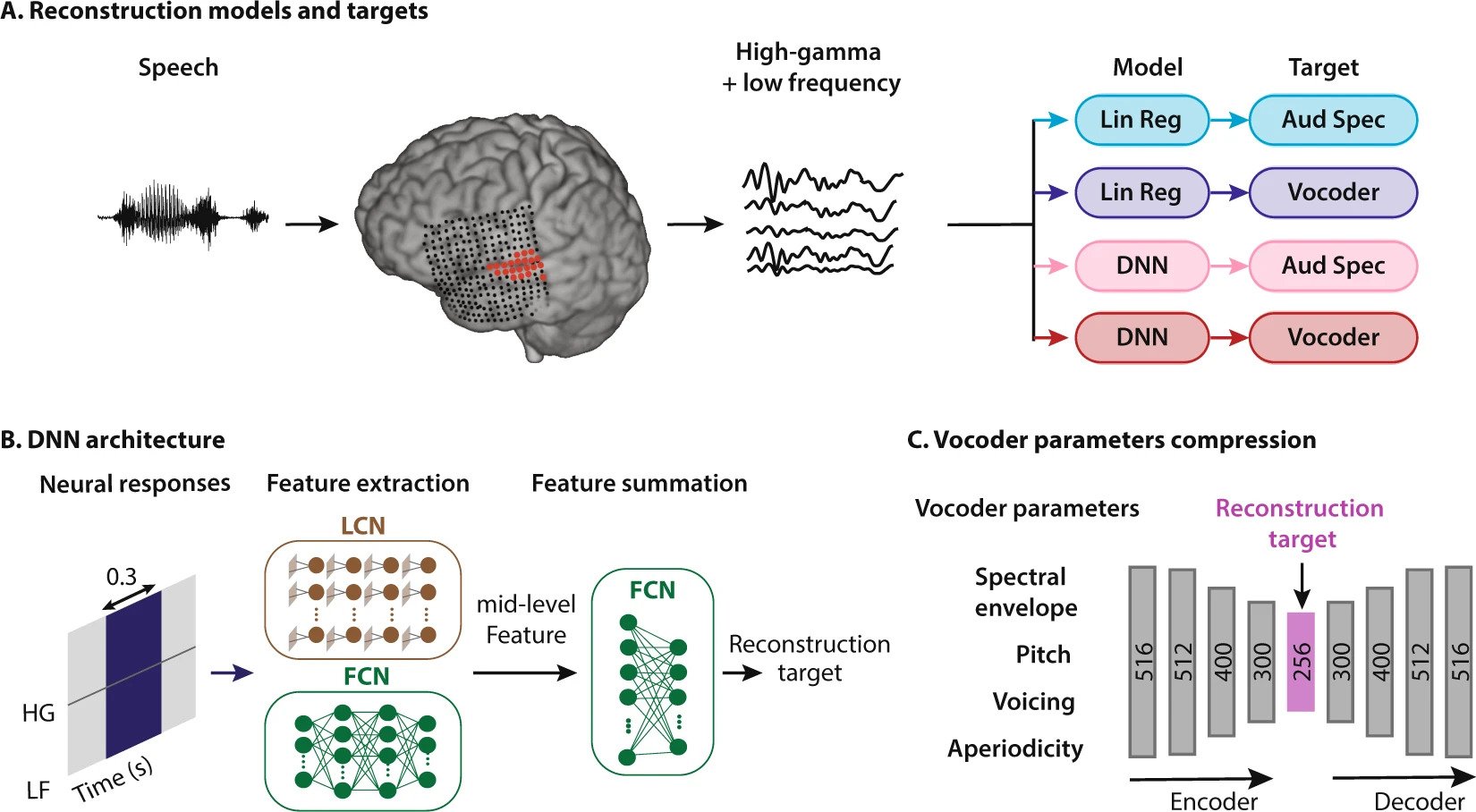
Pour reconstruire le stimulus auditif à partir des signaux neuronaux, le Dr. Mesgarani et son équipe se sont servi de deux modèles de régression : linéaire et non-linéaire (implémenté par du deep neural network DNN). Ils ont également utilisé deux types de représentations acoustiques pour recréer les sons : spectrogramme auditif et vocoder (un algorithme pouvant synthétiser la parole après avoir été entraîné par des enregistrements de personnes qui parlent). C’est d’ailleurs le vocoder qui est utilisé par Siri ou Alexa pour produire des réponses aux questions qu’on leur pose. On obtenait donc 4 combinaisons possibles : regression linéaire-spectrogramme, regression linéaire-vocoder, DNN-spectrogramme, DNN-vocoder.
Les chercheurs se sont associé au Dr. Mehta (neurochirurgien à Northwell Health Physician Partners Neuroscience Institute) pour utiliser l’électroencéphalographie intracrânienne (ECoG), une technique invasive qui enregistre l’activité cérébrale, au niveau des aires corticales du langage (Gyrus temporal supérieur et gyrus de Heschl) de patients traités pour épilepsie. Ces électrodes implantées pourraient s’apparenter à une neuroprothèse. Ils leur ont fait écouter des discours et des séries de chiffres pour obtenir des motifs d’activités cérébrales et entraîner les algorithmes à associer tel signal à tel mot ou son. Les algorithmes ont ainsi pu reproduire les mots avec une voix synthétisée.
Des résultats encore jamais atteints grâce au Deep Learning
L’équipe a ensuite effectué des tests de compréhension subjectifs et objectifs (score ESTOI) des sons reconstruits et dans les deux cas, l’association DNN-vocoder a montré les meilleurs scores. Dans 75% des cas, les patients pouvaient comprendre et répéter les sons produits ! En implantant un tel système chez des personnes ne pouvant pas parler, on pourrait leur permettre d’exprimer à nouveau leurs pensées. « Dans cette situation, si le patient pense ‘j’ai besoin d’un verre d’eau’, notre système pourrait utiliser les ondes cérébrales générées par cette pensée et les transformer en un discours synthétisé articulé » a déclaré Dr. Mesgarani.

Ainsi, les chercheurs ont comparé les capacités des modèles de régression linéaire et non-linéaire (DNN) à reconstruire des signaux du langage par spectrogramme auditif et vocoder. Il se trouve que l’utilisation d’un DNN pour régresser des paramètres de vocoder est le système le plus performant. Cette étude met en avant les bénéfices du deep learning dans la recherche sur les neuroprothèses du langage.
L’équipe vise par la suite à générer des phrases plus longues et plus complexes afin de créer les prochaines générations de BCI et faciliter la communication entre l’Homme et les machines, mais aussi d’aider les patients ayant perdu l’usage de la parole à pouvoir rester libres d’échanger avec leur environnement.
Crédit de l’image de couverture : geralt – Pixabay License



{kind=link}
{kind=link}