
En tant que développeur, j’ai horreur de penser aux tests automatisés… même s’ils sont cruciaux lorsqu’il s’agit de vérifier la validité d’un code suite à un développement !
Conscient du fait que l’IA révolutionne tous les secteurs – en particulier les métiers du développement informatique – je me suis tourné en 2h vers Ponicode et l’un de ses fondateurs, Patrick Joubert, pour voir comment est-ce que je pourrai exploiter sans scrupule l’intelligence artificielle pour écrire des tests pertinents à ma place.
PS : J’en ai également profité pour en apprendre plus sur comment s’organise un projet de data science dans une start-up innovante.
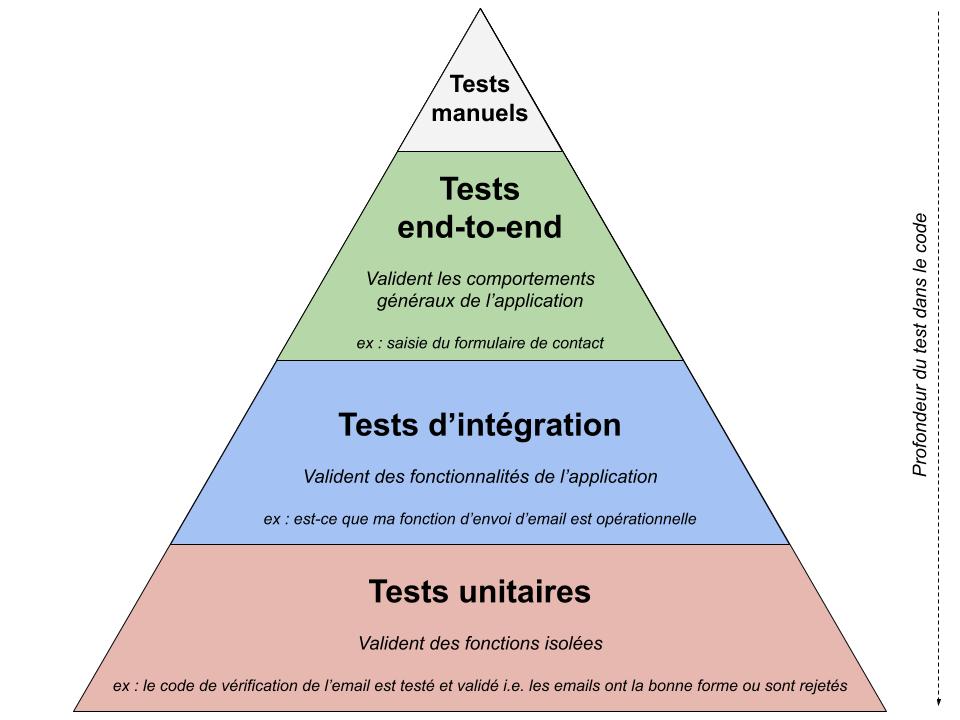
Les tests unitaires, à quoi ça sert ?
Commencer cet article par une définition n’est pas facile, car les tests unitaires ne sont pas simples à résumer : comme pour les mots « intelligence artificielle », il y a plusieurs manières de les considérer mais la plus fréquente reste « un code spécifique (on parle également de procédure) qui permet de vérifier si, à partir de certaines données en entrée, le code considéré renvoie la bonne sortie/réalise la bonne action ou encore de vérifier le bon fonctionnement d’une partie précise d’un programme ».
Généralement, pour limiter au maximum les risques d’injecter des erreurs indépendantes à la partie testée, on mock i.e. on remplace le reste du programme par des comportements très restreints. Imaginons que j’ai le pseudo-code suivant :
- Une fonction « envoyer_email », appelée à chaque fois qu’on clique sur le bouton « Envoyer » de mon formulaire
- Une fonction « verifier_destinataire », appelée au début de « envoyer_email » qui regarde si le destinataire est bien un email valide
fonction verifier_destinaire (string destinataire):
SI "@" DANS destinataire:
RENVOYER "email valide"
SINON:
RENVOYER "faux email"
fonction envoyer_email (objet email):
SI verifier_destinaire(email.destinataire) EST "email valide":
expedier email
SINON:
afficher message erreur destinataire invalideOn pourrait alors écrire deux tests unitaires (notés TU) :
- un premier qui va vérifier si la fonction « verifier_destinataire » fonctionne bien. On va lui envoyer plein d’emails et de faux emails, et regarder ce qu’elle nous répond. En l’état par exemple, « l’email » 0258iouetgé' »é_-« &é +=&@_ »è(ç »‘-kjl passera alors qu’il n’a aucun sens (il faudrait vérifier les caractères spéciaux, la présence d’un .fr par exemple, etc… pour valider correctement un email)
- un second qui va mocker la fonction verifier_destinataire en renvoyant systématiquement email valide ou faux email, pour éviter qu’un bug dans verifier_destinataire vienne perturber notre TU
PS : dans la pratique, le but d’un TU n’est pas de tester chaque fonction mais de couvrir les aspects critiques de l’application. Il n’y aura pas forcément besoin d’écrire un TU dédié à « verifier_destinataire » et on sera souvent un peu plus larges, mais cet exemple permet de réduire au maximum l’explication des TU (n’hésitez pas à consulter des sites de référence pour en apprendre davantage) !
Dans la logique d’un TU, si on ne code pas tout, le développeur doit constamment s’interroger sur le code qu’il écrit et sur les failles potentielles. Sa mission sera évidemment d’éviter un maximum de bugs par le biais de son code, mais aussi en réalisant parfois des TU ciblés sur des cas dits « limites ». On pourrait par exemple se demander :
- que se passe-t-il s’il n’y a pas de @ dans l’adresse ? S’il y en a deux ?
- que se passe-t-il s’il y a des caractères spéciaux, des espaces ?
- que se passe-t-il si l’email est très très long ?
- que se passe-t-il si l’email est vide ? s’il est null ?
- que se passe-t-il si on reçoit autre chose qu’une chaîne de caractères ?
- que se passe-t-il s’il ne termine pas par .fr ?
- etc…
Ecrire le test d’une fonction, ça peut donc impliquer d’écrire au moins 2 à 10 fonctions testant des sous-cas particuliers ! On imagine bien qu’un outil permettant d’augmenter la « couverture » (i.e. le nombre de situations testées par nos tests) est très attrayant.
Pour l’exemple précédent, cela donnerait :
fonction tester_deux_@_dans_destinataire():
string destinataire = "prenom@domaine@test.fr"
appeler verifier_destinaire(destinataire) -> retour doit être "faux email"
fonction tester_destinataire_trop_long():
string destinataire = "abcdefghijklm@test.fr"
appeler verifier_destinaire(destinataire) -> retour doit être "faux email"
fonction tester_destinataire_normal():
string destinataire = "prenom@test.fr"
appeler verifier_destinaire(destinataire) -> retour doit être "email valide"A noter qu’on a parlé ici de tests unitaires (en restant volontairement assez vagues), mais qu’il existe également les tests d’intégration (TI) qui sont au niveau supérieur et testent des utilisations du programme plutôt que des fonctions/fonctionnalités seules. Par exemple, on pourrait écrire un TI qui demande l’envoi d’un email et vérifie si l’email est bien parti ensuite, sans se soucier du chemin emprunté dans le logiciel. Un tel TI, suivant comment il serait tourné, pourrait d’ailleurs être en réalité… un TU !
Au plus au niveau, on retrouve les tests « end-to-end » (de bout en bout) qui viennent valider le comportement global, par exemple le clic sur le bouton « Envoyer mon email » dans l’interface web et son expédition (si l’email que je saisis est réel).
Faut-il faire des tests unitaires en intelligence artificielle ?
Oui, oui et oui ! Comme dans tout projet informatique, il est important de valider le bon fonctionnement d’un programme quel qu’il soit. Cependant, l’enjeu des tests sera différent en fonction du niveau considéré :
- Sur la préparation des données, il est important de valider que nos fonctions manipulent les données comme prévu et gèrent les cas « aux bords »
- Sur les données en elles-mêmes, il faut aussi penser à avoir un regard humain, car les capacités d’une IA dépendent de ce qu’elle aura vu avant
- Sur l’algorithme d’entraînement, l’enjeu est de surveiller si toutes les briques sont bien agencées
- Sur l’IA en elle-même, on sera vigilants sur la réaction de l’IA à des cas préparés à l’avance et connus, pour s’assurer de son bon fonctionnement en tant que service
- Et bien entendu, il y a toute la partie « projet classique » autour de l’IA, avec l’interface du service, le déploiement serveur, etc… qui devront être testés !
Comment fonctionne une start-up en intelligence artificielle, quels sont ses enjeux et ses attentes
En général, un programme informatique compte quelques milliers (pour un micro-service) à plusieurs millions de lignes de code (une navette spatiale en compte 400 000, Google Chrome 8 million, Windows Vista 50 million) ! Et le nombre de fonctions oscille entre quelques centaines à plusieurs dizaines de milliers.
Sachant que tester une seule fonction demande plusieurs secondes, je me suis tourné vers Ponicode pour m’aider dans cette tâche ingrate mais essentielle…
Présentons Ponicode que l’on a rencontré en 2h
Ponicode est la troisième entreprise de son co-fondateur Patrick Joubert (connu notamment pour sa vente de recastAI à SAP à il y a deux ans dédiée à la compréhension du langage). Agée de seulement un an, son objectif est très clair : générer du code semblable à celui qu’aurait écrit un humain !
Supportant le Javascript (node.js) en attendant d’intégrer complètement le Python, le Typescript, le Java ou encore le C#, Ponicode reste avant tout une entreprise parisienne de 10 personnes qui a connu trois itérations avant d’arriver à un résultat « viable et intéressant » (selon Patrick Joubert).
Une start-up dans le monde de l’IA
Quels métiers retrouve-t-on chez Ponicode ?
Pour faire de l’IA, il faut des data scientists (ou tout métier connexe, cf notre article sur les métiers en IA). Chez ponicode, il y a donc :
- 1 CEO/responsable marketing
- … et 2 data scientists dédiés + 7 développeurs-data scientists (notamment pour l’intégration à VSC)
Les profils « transverses » sont-ils pertinents dans une start-up en IA ?
Patrick nous donne un conseil, que je trouve très vrai (étant moi-même à fond dans le deep learning mais avec de l’expérience professionnelle et personnelle en développement web) :
« Il faut vraiment éviter la data science qui réalise des super prototypes mais qui n’est pas capable de construire le pipeline complet d’IA ensuite car il n’y a pas de développeur. Un projet est toujours plus large que l’acquisition des données, la préparation de celles-ci et l’entraînement de l’IA, il faut s’y préparer en recrutant des métiers transverses car une start-up ne peut se permettre de trop recruter ».
Quelles études faire pour avoir ses chances d’être recruté ?
Quels sont les profils de ces 2+7 data scientists ? Sont-ils des développeurs formés au métier de DS ou des DS ayant découvert la réalité des projets d’IA dans leur ensemble ? C’est ce que j’ai pu creuser avec Patrick, qui m’explique la politique de recrutement de Ponicode : « tous nos profils sont de formation data scientist : un cursus généraliste chargé en Mathématiques et avec une spécialisation en Data Science. Nous avons l’occasion de travailler avec beaucoup d’écoles, mais nos principales restent l’école Centrale, le master IA de l’EPFL et l’école 42″.
Suite à la levée de fonds de 3M d’€ annoncée début juillet, nous souhaitons agrandir l’équipe et nous sommes actuellement à la recherche de 2 développeurs pour continuer d’améliorer le produit.
La start-up participe-t-elle à la vie du monde de l’IA en dehors de son activité principale ?
La société a également gravé dans son ADN l’animation de meet-up et de conférences autour de l’IA pour ouvrir l’esprit des gens, la participation à des challenges Kaggle et a lancé l’initiative (sur apda.org) de simulation d’épidémiologie Covid ! Sans parler du bot capable de générer des paroles de RAP pour remporter l’AI RAP BATTLE (sur github en open source)…
Les jeux de données de l’IA
Il y a deux sources de données principales :
- Des projets de Github, sélectionnés en fonction de leur note (même si, pour la diversité, de moins bons « repos » ont été retenus) : cela représente quelques dizaines de millions de lignes de code, beaucoup étant écartées
- Le partage des tests réalisés dans le cadre de l’alpha et de la beta de Ponicode (de manière totalement anonymisée bien entendu) : quelques milliers de personnes ont alimenté par la pratique l’IA, qui s’améliore chaque jour, lors de ces phases préliminaires à la version publique
Le matériel pour entraîner une IA
Confronté à cette problématique chez Touch Sensity, j’ai naturellement questionné Patrick sur les ordinateurs qu’ils utilisaient pour traiter ces milliers de fichiers de code. Comme prévu, ils utilisent :
- des ordinateurs portables de gamer type ROG (republic of gamers), avec au moins 32 Go de RAM (pour pouvoir entraîner l’IA avec des batchs plus gros), une carte graphique Nvidia RTX 2080 (pour la rapidité de l’entraînement), un disque SSD (pour accélérer l’accès de l’IA aux jeux de données) et un excellent processeur (car les entraînements se font également grâce au CPU, surtout en traitement du langage naturel), ou type Alienware (cf les liens sous les images pour voir les caractéristiques en question).


- des abonnements cloud à Microsoft Azure et Amazon AWS
Le principal étant… d’avoir un maximum de RAM !
Quel pipeline d’IA ? D’où viennent les algorithmes utilisés par l’IA de Ponicode ? Machine learning ou deep learning ?
Sans avoir le droit de trop rentrer dans les détails pour des raisons évidentes de confidentialité et de concurrence, Patrick a bien voulu nous dire quelques mots sur les algorithmes qu’ils utilisent en interne.
Tout d’abord, leurs IA, car comme pour la reconnaissance faciale il n’y a pas qu’un seul algorithme, sont principalement issues du Machine Learning mais peu du Deep Learning. Les data scientists qui ont le rôle d’ingénieurs Machine Learning ont savamment mixé des idées récentes (au niveau de l’état de l’art) d’apprentissage par renforcement, de notion de réseaux à mémoire (un bi-LSTM par exemple) et d’algorithmes plus simples (peut-être SVM ou Random Forest ?) pour créer l’IA capable, à partir d’une fonction et de son code, de générer tout un fichier de test couvrant la quasi-totalité des cas possibles.
A noter que l’IA est aussi capable de mocker (détection et proposition de valeurs) des objets complexes très facilement.
Le petit détail qui rend Ponicode réaliste dans ses propositions de TU
Pour finir, je souhaitais partager une petite anecdote sur le développement de Ponicode.
Imaginons que l’on veuille tester une fonction qui convertit un nombre à virgule (= un « float ») en un entier en prenant la partie entière de celui-ci. Par exemple :
- 3.5 devient 3
- -2 devient -2
- 7.2669 devient 7
- -4.89 devient -4
Maintenant, si on devait écrire un programme qui génère ces entrées/sorties que se passerait-il ? En prenant des nombres aléatoires, il nous proposerait :
- 486035.54674101 devient 486035
- -1306.156884201254152 devient -1306
L’enjeu pour Ponicode est de proposer aux développeurs une IA qui crée des tests comme un humain le ferait. Hors de question d’avoir des 8548.8489478741 en suggestion… mais comment ?
La réponse nous vient des réseaux génératifs antagonistes (GAN) et des deep fakes par extension, qui apprennent à générer automatiquement des images, du texte, des voix, des vidéos, des données, à partir d’exemples ! Typiquement, montrez à un GAN des chiffres écrits à la main par des humains, et il saura ensuite écrire des chiffres indiscernables de ceux écrits par les humains.
Ou dans le cas de Ponicode, montrez des tests unitaires codés à la main, et vous obtiendrez une IA dont les tests sont parlants et réalistes, proposant en test par exemple 3.14 plutôt que 8548.8489478741
Nos premiers tests automatisés par une IA
Ponicode est aujourd’hui accessible en beta publique à tous les développeurs désireux de tester cette IA de génération automatisée des tests unitaires.
Pour cela, il suffit de s’inscrire sur le site en indiquant son compte Github (qui sert d’identifiant) et en téléchargeant le plugin dédié dans l’éditeur de code Visual Studio Code (v1.47.1 minimum).
Ensuite, automatiquement, un logo de la société apparaît devant le code à tester…
On appuie alors sur CTRL + T en étant dans la fonction à tester ou on clique sur le logo pour ouvrir l’onglet suivant (à droite du code dans l’éditeur) ou on fait clic droit puis « ponicode > test » que nous allons détailler ensemble :
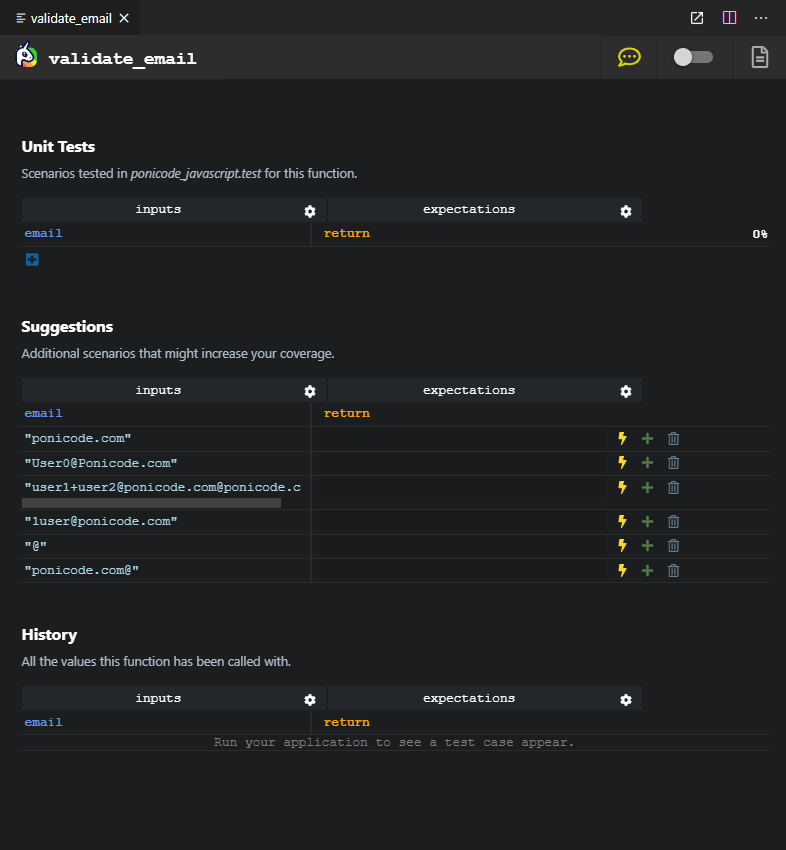
La partie « Unit Tests » regroupe mes variables d’entrées (ici il n’y a qu’email) et les valeurs attendues. Pour l’instant, je n’ai rien rempli, mais chaque ligne représentera un test unitaire de valeurs possibles.
La partie « Suggestions » est automatiquement remplie par l’IA de Ponicode. Celle-ci a lu des milliers de codes et de tests écrits par des humains, notamment ceux de l’alpha du programme, et propose des valeurs d’entrées triées en fonction de leur impact sur la couverture globale des tests !
Ainsi, on n’aura pas deux suggestions consécutives du type lambert@touchsensity.com, charles@touchsensity.com car cela n’apporte rien de plus la deuxième fois. Par contre, on pourra avoir lambert@touchsensity.com et lambert.rosique@touchsensity.com car il y a un caractère spécial dans l’email maintenant.
Il suffit de cliquer sur les « + » pour ajouter les suggestions aux tests et voir sa couverture augmenter
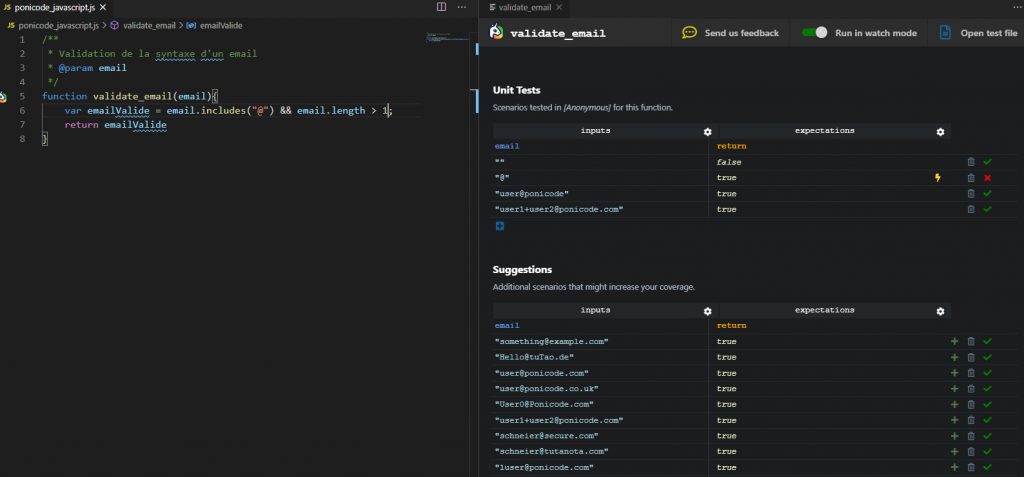
Relançons le « validate_email » de Ponicode en fermant l’onglet et en le rouvrant (quelques jours plus tard) et poursuivons notre découverte de l’outil :
- les suggestions sont différentes !
- Et si on active le « Run in watch mode » (en haut à droite), les expectations sont également bien remplies, de quoi nous faire gagner énormément de temps.
- De plus, si on change le code à gauche, Ponicode détecte automatiquement que les tests ne fonctionnent plus et il nous prévient (cf la ligne avec « @ »).
Remarque importante : pour que Ponicode fonctionne, il faut impérativement (dans la version 0.21.0) avoir un fichier package.json
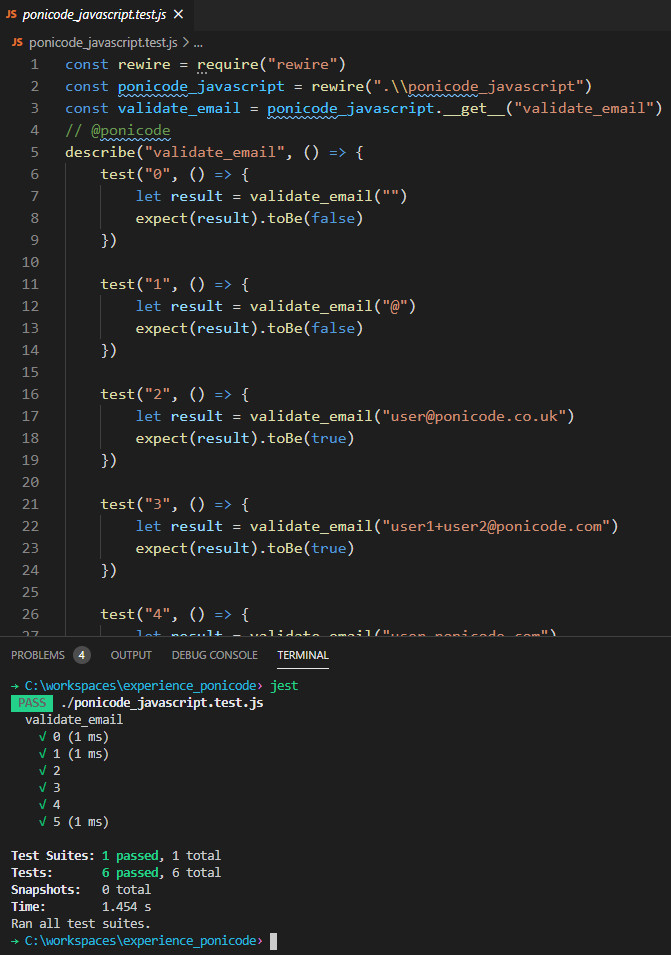
Pour finir, on peut observer le fichier généré ponicode_javascript.test.js : celui-ci utilise la syntaxe de « Jest » (ainsi que rewire pour exécuter le code), donc pour l’exécuter par vous-même il faudra d’abord lancer une fois les commandes suivantes :
- npm install jest –global
- npm install rewire
puis écrivez simplement jest pour exécuter tout le fichier
Pour aller plus loin dans la découverte de Ponicode
Afin de limiter la longueur de cet article, je n’ai pas mis énormément de screenshots ou de tests de Ponicode : je voulais donc vous partager ici un article écrit par Sylvain Leroy sur son site, que je vous invite à consulter si vous voulez creuser un peu l’utilisation de Ponicode (en plus de la documentation officielle).
Mon avis sur l’utilisation de Ponicode
Ce n’est pas parce que je réalise une interview, que je suis obligé d’aimer et de vanter les qualités d’un produit. Alors j’espère que vous me croirez lorsque je dirai que j’adore l’IA qu’ils ont développé ! Je trouve que l’équipe a réalisé un travail formidable sur de nombreux plans :
- l’IA fonctionne bien
- le choix d’intégrer la solution à VSC me semble pertinent et bien pratique
- la simplicité d’utilisation est évidemment à retenir, car je n’aime pas faire les tests, et j’aime encore moins chercher/apprendre comment ne plus avoir à les faire
- l’équipe est très réactive, on m’a énormément aidé à trouver l’origine d’un minuscule bug que j’avais : l’absence de ce fichier package.json ^^ Merci Baptiste Bouffaut et Simon Guilliams !
Bien entendu, il y a encore du chemin à parcourir et j’attends impatiemment les fonctionnalités suivantes (pas nécessairement annoncées, mais que j’espère voir un jour) :
- support complet du langage Python
- mise en oeuvre de tests plus complexes (on peut déjà mocker des appels)
- analyse du code pour prévenir qu’il n’est pas « test-friendly »
N’oublions pas que la beta vient à peine de démarrer ! Le modèle économique suivra pour sa part le classique « gratuit pour les particuliers, payant pour les entreprises », donc si vous voulez le tester pour votre équipe n’hésitez pas à profiter de la phase de beta.
Bonus : le code utilisé dans l’expérience
ponicode_javascript.js
/**
* Validation de la syntaxe d'un email
* @param email
*/
function validate_email(email){
var emailValide = email.includes("@") && email.length > 1;
return emailValide
}package.json (pour avoir ce fichier, écrivez simplement dans la console npm init en validant à toutes les questions)
{
"name": "experience_ponicode",
"version": "1.0.0",
"description": "Réalisé par Lambert Rosique pour PenseeArtificielle.fr",
"main": "ponicode_javascript.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}Conclusion : l’IA atypique d’une start-up « classique » ?
Grâce à Patrick Joubert nous avons pu découvrir ensemble les dessous d’une start-up en intelligence artificielle. Si la solution de générer des tests unitaires réalistes automatisés est originale et bienvenue, le fonctionnement de la société est classique et on retrouve la définition même d’une start-up en intelligence artificielle dans leur ADN :
- la présence (en proportion) d’un grand nombre de data scientists
- leur double casquette de développeur
- l’utilisation d’ordinateurs portables ultra-performants ou du cloud directement
- l’utilisation de gros volumes de données et la mise en place d’un pipeline custom répondant précisément à leur besoin
Je remercie chaleureusement Patrick pour son temps et ses réponses honnêtes et éclairées, ainsi qu’Amandine Bonnefis pour cette opportunité.
Si vous souhaitez présenter votre solution d’intelligence artificielle sur le site, n’hésitez pas à contacter Pensée Artificielle par email à contact@penseeartificielle.fr pour organiser une interview en 2h… mais notez bien que l’objectif de ces articles n’est pas la promotion personnelle mais plutôt la mise en lumière de process ou de technologies qui bénéficieront aux lectrices et aux lecteurs 🙂
Crédit de l’image de couverture : Ponicode – Tous droits réservés



{kind=link}