
Il n’y a pas si longtemps, on parlait des MobileNet, de la reconnaissance d’image en temps réel. Véritable enjeux de notre société, son application la plus connue à l’heure actuelle est l’identification de « boxing« , i.e. trouver dans une image tous les objets et toutes les personnes pour les encadrer et les mettre en évidence.
Dans ce focus dédié aux MobileNet-SSD, nous allons voir comment l’algorithme de classification MobileNet a été combiné à l’incroyable framework Single Shot multibox Detector (SSD) pour donner les MobileNet-SSD !
Ce dernier pourra être facilement transformé en une application Android et être embarqué dans n’importe quel smartphone (qu’il soit récent ou non), voire à une Raspberry Pi, pour fournir un outil extrêmement puissant d’analyse d’image en temps réel (avec plus de 20 FPS).
Le focus est découpé en deux parties :
- Partie théorique, qui va rappeler très brièvement ce qu’on a vu auparavant
- Partie TP, où nous allons entraîner notre MobileNet SSD sur un cas précis et en faire une application utilisable partout (on verra dans un autre focus pour l’intégrer à Android).
Bonne lecture !
I. Théorie : Qu’est-ce qu’un MobileNet-SSD
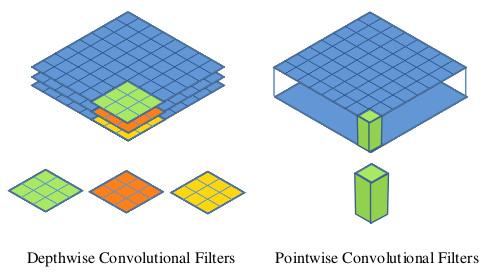
Dans un focus précédent, nous avons vu ce qu’était l’algorithme MobileNet.
Si on devait le résumer simplement, on dirait que c’est un réseau de neurones convolutionnel (CNN), qui a divisé sa phase de convolution en deux opérations plus simples (et rapides).
On va également bientôt voir ce qu’est le framework Single Shot Multibox Detector (SSD) et ce qui le rend aussi puissant, donc on ne va pas s’attarder dessus. Ce qu’il est important de retenir, c’est que le SSD permet, en scannant l’image, d’identifier toutes les zones qui présentent un élément à classifier.
En combinant les deux algorithmes, on a SSD qui place des boîtes sur toute l’image puis on a MobileNet qui les classifie, ce qui rend l’algorithme très performant et utile !
II. Pratique : Mise en place d’un MobileNet-SSD
Maintenant que vous êtes au point sur la partie théorique, on va voir comment mettre en place l’algorithme et l’utiliser sur le cas concret de l’identification des Macaroni au fromage, un plat dont j’avais déjà le jeu de données (mais que vous pourrez facilement adapté à vos usages !).
On va également profiter de ce tutoriel pour introduire plusieurs concepts fondamentaux, donc n’hésitez pas à lire le texte entre les commandes 🙂
1) Préparation de l’environnement
Pour pouvoir aller au bout de nos objectifs, on va avoir besoin de télécharger un certain nombre de dépendances Python 3 (que vous devriez avoir déjà installé), ainsi que des logiciels tierces et des projets Github.
a. Python 3 :
La différence entre Python 2 et 3, pour la data science et l’usage qu’on va en avoir n’est pas critique. Néanmoins, j’ai opté pour la 3 par habitude et par soucis d’encourager à utiliser la dernière version, porteuse d’avenir, plutôt que de continuer à s’enliser dans la 2 et à multiplier le travail de compatibilité.
b. Dépendances Python :
On va en utiliser plusieurs, qui seront téléchargées par le biais de pip (installé en même temps que Python). Saisissez les commandes suivantes dans la console Windows pour tout récupérer :
pip install pillow pip install lxml pip install jupyter pip install matplotlib pip install opencv-python pip install tensorflow
Détaillons ensemble ce qui va être installé :
- Pillow est une librairie de manipulation d’images, permettant de travailler efficacement dessus
- Lxml permet de travailler sur du xml et du html
- Jupyter est une application permettant d’exécuter du code Python (on s’en servira à peine pour un exemple)
- Matplotlib permet de tracer des graphes et est utilisé par beaucoup d’autres librairies
- OpenCV est l’une des librairies d’analyse d’image les plus utilisées. Très puissante et robuste, elle implémente beaucoup d’algorithmes récents
- Tensorflow est la librairie de deep-learning de Google
c. Protocol Buffer
Utilisant les projets de Google, nous allons avoir besoin de travailler avec des protocol buffers. C’est un mécanisme qui ne repose sur aucun langage ni aucune plateforme pour sauvegarder (sérialiser) des données structurées.
Par exemple, grâce à un protocol buffer, vous pouvez créer un modèle et le partager avec n’importe quel langage très facilement : un fichier .proto (générique) peut être converti en version « python » ou en version « swift » à la volée.
Pour ce tutoriel, j’ai utilisé la version protoc-3.4.0-win32.zip car les versions plus récentes ne semblent pas fonctionner (les fichiers ne sont pas construits)
Une fois le fichier téléchargé, il suffit de le dézipper où vous voulez (par exemple, D:\Tools\protoc-3.4.0). Attention à bien adapter vos commandes aux arborescences que vous utiliserez ensuite !
Remarque : vous pouvez ajouter le dossier de protobuf au path de Windows pour ne pas avoir à saisir tous les chemins, en mettant simplement D:\Tools\protoc-3.4.0\bin dans les variables système (c’est ce que j’ai fait).
d. Github
- Tout d’abord, on va télécharger les Models de TensorFlow, même si on ne va en utiliser qu’une infime partie. Pour en dire deux mots, c’est l’ensemble des algorithmes phares implémentés par TensorFlow et regroupés sur ce Github. On y trouve notamment des algorithmes innovants (dans research), dont les MobileNet.
EDIT IMPORTANT : la dernière version du projet Models de Tensorflow ne marche pas (il y a une erreur d’int reçus au lieu de float), donc je vous conseille de simplement utiliser la version qui m’a servie à faire ce tutoriel : la 1.4.0, qui marchera bien comme on le veut !
EDIT 2 ENCORE PLUS IMPORTANT : le dossier « research » n’est pas sauvegardé dans les anciennes versions de models… Par conséquent, j’ai mis sur Github mon dossier models avec uniquement la partie « research/object detection ». Récupérez ce dossier à la place de celui de tensorflow (car ça ne marchera pas sinon). A noter qu’il y a déjà tous les fichiers et dossiers du projet mobilenet-ssd, mais mieux vaudra les écraser à chaque fois que vous copierez des fichiers depuis ce tutoriel !
Télécharger le projet Models depuis le github de Pensée Artificielle
A noter que vous pouvez également utiliser les commandes Git pour récupérer les projets, mais attention car on va modifier certains fichiers !
J’ai renommé models-master en model et l’ait placé ici : D:\workspaces\models
- Ensuite, il va nous falloir un certain nombre de fichiers créés ou modifiés pour ce tutoriel. Ils sont tous regroupés sur le Github suivant, que je vous invite à télécharger et à extraire directement dans D:\workspaces\models\research\object_detection (afin de simplifier les explications suivantes) :
Télécharger les fichiers d’exemple pour MobileNet-SSD par Pensée Artificielle
Remarque : certains fichiers ne seront pas placés directement dans les bons répertoires d’object-detection, et c’est voulu. Par exemple, les deux fichiers CSV devraient être dans object-detection/data, mais je les fournis en dehors pour vous permettre de les générer (et les voir apparaître).
De plus, concernant la version du MobileNet-SSD que l’on utilise, certains scripts la re-téléchargent automatiquement. Je vous invite néanmoins, lorsqu’indiqué, à remplacer les fichiers téléchargés par ceux du projet Github qui ont été testés.
e. Label Image et jeux de données
Pour pouvoir construire nos jeux de données (JDD), on va devoir télécharger des images et les annoter correctement. Si vous avez déjà un JDD au format TFRecord avec les images et les box labellisées, vous n’avez pas besoin de télécharger le logiciel suivant : labelimg (j’utilise la version 1.5.2 pour le focus).
Si vous voulez télécharger directement le JDD des macaronis au fromage, voici également le lien (sinon, vous devrez les annoter vous-même !).
f. Installation de Object-detection de TensorFlow
Pour pouvoir utiliser les scripts fournis par TensorFlow et les algorithmes du projet object-detection, il faut réaliser plusieurs étapes indispensables à la suite de ce tutoriel.
ATTENTION : les commandes sont à saisir dans une invite de commande et non dans PowerShell (car ça ne marchera pas sinon) !
En premier lieu, depuis D:\workspaces\models\research, lancez la commande suivante afin de builder les .proto :
protoc object_detection/protos/*.proto --python_out=.
Puis définissons l’environnement de travail de Python :
set PYTHONPATH=D:\workspaces\models\research;D:\workspaces\models\research\slim
Enfin, lançons l’installation complète du projet de recherche de TensorFlow :
python setup.py install
Si tout se passe bien, vous ne devriez avoir aucune erreur, et en dernière ligne « Finished processing dependencies for object-detection==0.1 »
Vous pouvez alors passer à la suite, le plus « difficile » est fait !
g. Source de ce tutoriel
Enfin, j’aimerai partager ici le cours (en anglais) sur lequel je me suis appuyé pour réaliser ce tutoriel. Le travail en amont de PythonProgramming était vraiment bien fait, merci !
2) Vérification de l’installation
Je vous propose un petit test simple pour vérifier que les models de TensorFlow compilent bien sur votre ordinateur et que vous pourrez les utiliser : on va lancer le Notebook de démo de TensorFlow pour la partie « détection d’objets ».
Plaçons-nous dans le répertoire via l’invite de commande Windows D:\workspaces\models\research et construisons les protos de object_detection (pour Python) (la console sera à garder pour exécuter toutes les autres commandes, qui nécessitent souvent ces protos buildés !) :
protoc object_detection/protos/*.proto --python_out=.
Ensuite, aller dans object_detection et lancer Jupyter Notebook :
cd ./object_detection jupyter notebook
Enfin, cliquez sur « object_detection_tutorial.ipynb » et dans le menu faites Cell -> Run all.
La totalité de l’exemple est ainsi lancée et vous pouvez, après quelques secondes, voir en bas de la page ce qu’a donnée la détection sur les images d’exemples du projet !
3) Test avec une caméra
Pour tester si notre caméra est bien fonctionnelle et détectée par Python, il suffit de lancer le fichier camera-test.py (que vous avez mis dans D:\workspaces\models\research\object_detection) via une commande windows :
python camera-test.py
Le code en est très simple :
video_capture = cv2.VideoCapture(0)
permet d’utiliser OpenCV pour lancer l’enregistrement de la vidéo (canal 0, à remplacer par 1 si vous avez plusieurs caméras, ou par le chemin d’une vidéo sur votre ordinateur par exemple…)
cv2.imshow('Video', frame)
tandis que cette ligne permet de montrer l’image qui a été capturée dans OpenCV (fait pour chaque image, donc ça nous donne une vidéo en sortie aussi).
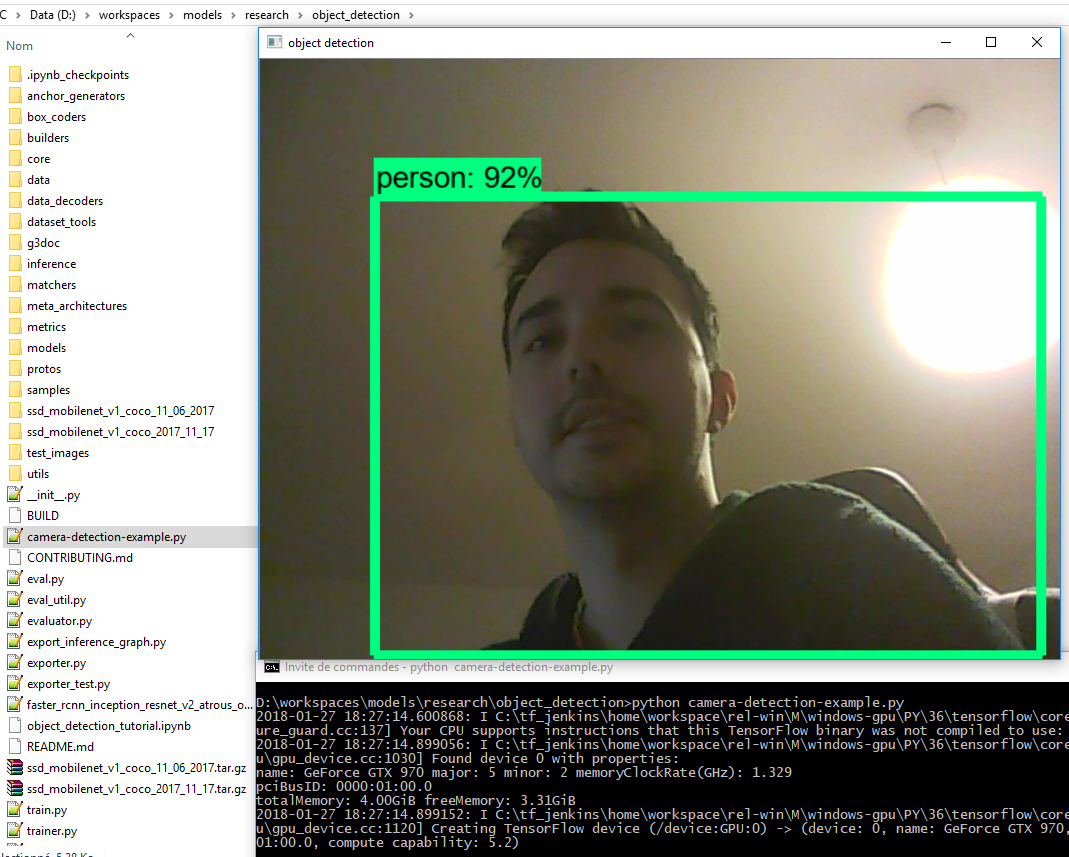
Si vous voulez maintenant faire du boxing dessus, en temps réel, comme pour la photo des deux chiens ou de la plage (partie précédente), il vous suffit de lancer dans la commande Windows :
python camera-detection-example.py
On ne reviendra pas sur le code pour l’instant, l’objectif étant simplement de tester directement ce qu’on va construire bientôt.
4) Construction des jeux de données
Tout est prêt, on peut attaquer notre vrai projet !
On va commencer par construire nos jeux de données pour pouvoir entraîner ensuite les algorithmes…
a. Annotation des images
Pour annoter les images, il y a deux manières de faire.
- Soit vous utilisez un algorithme pré-entraîné sur vos jeux de données, pour qu’il vous donne à chaque image la boite de détection. Ensuite, vous contrôlez toutes les images dont la boîte est fiable à moins de X% (par exemple, à moins de 70%) et vous les corrigez à la main. Cette technique nécessite d’avoir un assez bon algorithme en entrée, ce qui n’est vraiment pas impossible avec celui qu’on va utiliser !
- Soit vous annotez directement toutes vos images. Le procédé est long et fastidieux mais semble indispensable pour obtenir de bons résultats…
Ici, on va partir sur la seconde méthode, et pour chacune de nos images on va, dans le logiciel LabelImg que vous avez installé, dessiner des boîtes autour des macaronis au fromage !
Lancez le programme en double-cliquant dessus, puis ouvrez vos images et faites CreateRectBox. Le label à lui donner est celui que nous utiliserons partout par la suite, et qui désignera le type d’information à reconnaître (vous pouvez en faire plusieurs d’un coup).
Le bouton Save vous permettra de générer un fichier xml portant le nom de l’image et décrivant (pour l’algorithme) où devrait se trouver la boîte de détection, avec le label à utiliser pour la reconnaissance.
Une fois la totalité du dataset créé à partir des images, on va placer tous ces .jpg et .xml en dans D:\workspaces\models\research\object_detection\images, que l’on va découper en deux : train et test (si le dossier images n’existe pas, pensez à le créer et attention à l’orthographe).
b. Découpage en sous-dossiers
C’est une pratique très fréquente et indispensable : on crée deux dossiers (voire trois si vous avez assez d’images) :
- Train = contient environ 80% des images (un peu moins si vous avez le dossier validation). Ce dossier sert pour l’entraînement de l’algorithme, qui devra apprendre de ce JDD
- Test = contient environ 20% des images. Il ne sert qu’à tester les performances de notre algorithme mais pas à l’entraîner ! Ce sera donc notre référence fréquente pour voir s’il s’améliore.
- Validation = contient en général 10% des images. Celui-ci n’est confronté à l’algorithme qu’en fin de processus et ne doit en aucun cas servir à modifier l’algorithme : c’est le JDD étalon, qui simulera pour nous des cas réel postérieur à l’entraînement de l’algorithme.
Dans /images on retrouvera donc deux dossiers, /train et /test, qui contiendront les .jpg et .xml des images de macaronis au fromage.
Remarque : les images qui ne sont ni dans train, ni dans test, sont en réalité les images d’origine. Elles sont données pour vous permettre de procéder à un autre découpage.
c. Conversion des XML en CSV
Pourquoi, vous demanderez-vous immédiatement en lisant le titre. La réponse est simple : pour pouvoir entraîner notre algorithme MobileNet-SSD avec les outils de TensorFlow, nous devons obligatoirement l’alimenter avec des TFRecords.
Or, le script qu’on utilise pour convertir une base d’images en une base de TFRecords prend en entrée… des csv !
On va donc lancer la commande Windows suivante pour convertir tout notre dossier images en deux csv, qui seront enregistrés dans le dossier data (pensez à modifier le script si vous suivez une autre arborescence et à créer le répertoire data !) :
ATTENTION : il faut changer la console de répertoire avant d’exécuter cette commande, car le fichier se trouve dans object_detection et utilise des chemins relatifs.
python xml_to_csv.py
Les deux fichiers csv générés sont fournis avec notre projet Github au cas où vous bloqueriez sur cette étape, donc n’hésitez pas à les utiliser au besoin (ils seront alors à placer dans le dossier D:\workspaces\models\research\object_detection\data).
Si on détaille un petit peu le code, on voit la ligne suivante :
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
Le travail du script est très simple : pour chaque image qu’il va trouver, il va en extraire toutes les informations indiquées dans les colonnes ci-dessus à partir du .jpg et du .xml.
De cette manière, dans notre csv, on aura toutes les informations sur les images et sur les détections associées !
d. Conversion des CSV en TFRecord
On y est, enfin ! Mais qu’est-ce qu’un TFRecords ?
Il faut savoir que l’ouverture et la lecture d’un fichier image par un script est très lente, comparé à la lecture d’un énorme fichier binaire qui contient toutes les informations (images) « à la suite ». TFRecord est donc la concaténation de plein d’images… en un seul gros fichier binaire, pour nous permettre d’accroître considérablement le temps d’entraînement de l’algorithme.
Si vous avez bien suivi les pré-requis, votre models/research devrait être installé et vous permettre de lancer les scripts de conversion de TensorFlow.
Placez-vous dans D:\workspaces\models\research\object_detection et lancez la commande suivante :
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record
(en changeant bien évidemment les chemins et les noms si besoin et en créant le dossier data s’il n’existe pas)
Vous vous retrouverez ainsi avec deux fichiers .record, qui serviront à alimenter le MobileNet-SSD. Pour rappel, le fichier generate_tfrecord.py aura été mis dans le dossier /object-detection à partir du Github téléchargé de Pensée Artificielle (le script d’origine vient d’ici).
Remarque : si vous utilisez une autre catégorie d’images que « macncheese », pensez à modifier le fichier ! Idem si vous utilisez plusieurs nouvelles catégories, il faudra modifier le if :
def class_text_to_int(row_label):
if row_label == 'macncheese':
return 1
else:
None
Une fois encore, les fichiers à générer sont donnés dans notre projet Github pour éviter tout désagrément en cas d’échec (même s’il n’y a pas de raison), et devront être déplacés dans D:\workspaces\models\research\object_detection\data.
5) Entraînement du MobileNet-SSD !
On va partir d’un modèle pré-entraîné de MobileNet-SSD auquel on va ajouter notre classe « macncheese ».
a. Télécharger le modèle pré-entraîné
Pour ce focus, on utilise le checkpoint du 11.06.2017.
Télécharger le checkpoint du MobileNet-SSD
L’archive est à dézipper dans D:\workspaces\models\research\object_detection (vous aurez donc un nouveau dossier dedans : ssd_mobilenet_v1_coco_11_06_2017). Si le dossier existe déjà, écrasez-le avec nos modèles (les scripts de test du début ont une ligne pour télécharger le MobileNet-SSD mais ici on va utiliser un checkpoint précis).
b. Configurer l’entraînement
C’est le coeur de notre travail. Pour simplifier, je vous propose de partir d’un fichier de configuration déjà écrit, que l’on va adapter à notre arborescence.
Via le Github de Pensée Artificielle, vous devriez déjà avoir le dossier training dans /object-detection, avec dedans : ssd_mobilenet_v1_custom.config.
ATTENTION : pensez à bien le modifier si vous avez changé l’arborescence des projets !
De la même manière, vous devriez avoir object-detection.pbtxt au même endroit. Pensez à le corriger si besoin.
c. Lancer l’entraînement
Vous y voici, l’entraînement de votre MobileNet-SSD sur la classe que vous avez définie.
Si tout à été suivi jusqu’ici, vous devriez avoir d’une part vos TFRecord dans /data et, d’autre part, vos fichiers de configuration dans /training.
Avec votre console bien configurée (protoc a été lancé, le PYTHONPATH est setté…), lancez la commande suivante :
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_custom.config
Après quelques secondes, vous devriez voir apparaître les résultats des entraînements successifs ! Félicitations !
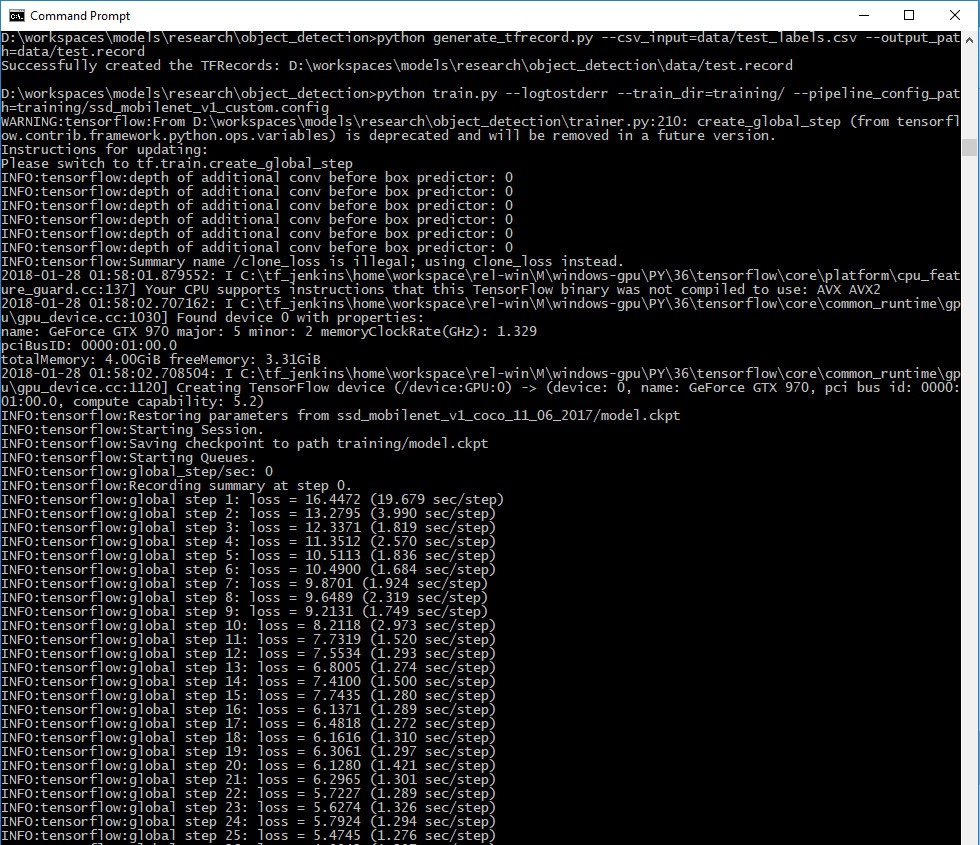
d. Bonus : voir la courbe de progression
Un petit bonus avant de passer à la suite : TensorFlow vous permet de voir les courbes d’entraînement de votre algorithme. Pour ce faire, lancez simplement la commande depuis D:\workspaces\models\research\object_detection\training (là où sont les logs de notre script précédent)
tensorboard --logdir=.
Une URL vous est donnée par la console pour accéder au TensorBoard, sorte de site web (local) depuis lequel vous avez accès à beaucoup d’informations.
On va pouvoir passer à la dernière partie qui bouclera la boucle : celle de la sauvegarde de notre modèle entraîné.
6) Sauvegarde du modèle MobileNet-SSD personnalisé
Ceci est la dernière partie de ce focus, celle où on va apprendre à sauvegarder le modèle ci-dessus. Une fois enregistré, on verra comment l’utiliser dans nos flux vidéos (mais normalement vous avez déjà vu comment le faire dans la partie II.3).
a. Corriger exporter.py
Le script fournit par TensorFlow pour exporter notre algorithme comporte une « erreur » (techniquement, c’est simplement que le modèle de MobileNet-SSD a évolué et que le script dans sa dernière version n’est plus accordé).
Ouvrez exporter.py (dans le dossier object-detection) avec un éditeur de texte et en ligne 72 remplacez la ligne par :
optimize_tensor_layout=rewriter_config_pb2.RewriterConfig.ON) #Anciennement layout_optimizer=rewriter_config_pb2.RewriterConfig.ON)
En effet, la balise « layout_optimizer » n’existe pas dans notre MobileNet-SSD (au niveau du graph le représentant), ce qui provoque une erreur. L’ancien nom était « optimize_tensor_layout » d’où le changement que je vous demande.
b. Sauvegardez le modèle
Lancez la commande suivante depuis votre console habituelle dans /object-detection :
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training/ssd_mobilenet_v1_custom.config --trained_checkpoint_prefix training/model.ckpt-25 --output_directory mac_n_cheese_inference_graph
ATTENTION : Pensez à bien changer le model.ckpt en fonction du numéro de checkpoint que vous voulez utiliser ! Ici, j’ai pris le numéro 25 pour être en accord avec la screenshot précédente…
Si tout se passe bien, vous devriez voir écrit en avant dernière ligne « Converted 199 variables to const ops. Un nouveau dossier nommé mac_n_cheese_inference_graph aura été créé, avec le frozen_inference_graph.pb dedans !
c. Réutilisez le modèle
Vous devriez avoir les deux fichiers suivants dans /object-detection, à partir du Github de Pensée Artificielle :
- test-video-example.py, le script que l’on va exécuter pour tester notre algorithme entraîné
- le dossier test_video avec la vidéo de mac’n’cheese : mac_n_cheese_test_video.mp4
Lancez simplement la commande
python test-video-example.py
Si votre algorithme a été suffisamment entraîné, il devrait reconnaître les macaronis au fromage lorsqu’ils apparaîtront à l’écran !
Les seules parties du script qui ont été modifiées sont :
- La source de l’image
import cv2
cap = cv2.VideoCapture('D:/workspaces/models/research/object_detection/test_video/mac_n_cheese_test_video.mp4')
- Le chemin du graph (on a commenté toute la récupération du graph)
#PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb' PATH_TO_CKPT = 'D:/workspaces/models/research/object_detection/mac_n_cheese_inference_graph/frozen_inference_graph.pb'
Remarque : vous pouvez aussi utiliser le graph avec le projet Jupyter Notebook vu au début !
7) Erreurs courantes
Il n’y en a pas beaucoup à signaler, les principaux problèmes viennent de l’une des situations suivantes :
- Il vous manque des librairies Python
- Votre protoc n’a pas été lancé (il manque donc des informations pour les build)
- Le projet research n’a pas été installé (et n’est donc pas utilisable)
- Notre PYTHONPATH n’est pas bien configuré
- La commande que vous lancez n’est pas au niveau du bon dossier
Pour toute question, remarque ou problème, n’hésitez pas à nous contacter dans les commentaires, on répondra rapidement et efficacement !
III. Conclusion
On a vu ensemble beaucoup de notions et de fonctionnalités de TensorFlow.
Tout d’abord, on a appris à générer une base de donnée TFRecord pour pouvoir entraîner n’importe quel algorithme de TensorFlow. Le process était un petit peu fastidieux car nos scripts associaient JPG + XML en CSV, puis aggloméraient les CSV en TFRecord.
Ensuite, on a appris ensemble à entraîner un modèle MobileNet-SSD pour qu’il détecte un nouveau type de donnée. Via le script « train.py », c’était simple (il fallait surtout configurer notre projet).
Enfin, on a vu comment sauvegarder notre modèle personnalisé, afin de pouvoir l’utiliser dans des situations réelles.
On espère que ce focus vous aura plu, n’hésitez pas à nous le faire savoir dans les commentaires ou sur notre page Facebook / Twitter !
Crédit de l’image de couverture : modification de l’image de StockSnap – Pixabay License



{kind=link}
Bonjour Lambert,
Merci pour ce superbe tuto sur ce sujet fort passionnant :-).
Un petit détail pour le §1. a), avec le dernier Python à ce jour – 3.6.4 – il n’est pas possible d’installer tensorflow directement via ‘pip install tensorflow’. En revanche avec Python 3.6.3 cela fonctionne.
Je n’en suis encore qu’au 4. c), mais je poursuis.
A bientôt.
[…] le flux en permanence au travail), n’hésitez pas à vous appuyer sur notre focus du MobileNet-SSD (mais attention à la chute de performances) […]
[…] est sur de la détection et la classification d’images. Que ce soit avec ou sans MobileNet-SSD, il faut que l’algorithme soit efficace mais surtout hyper rapide (on peut ajouter du […]
[…] Tensorflow Lite, ou se limiter à du Machine Learning ou à des algorithmes adaptés comme YOLO ou MobileNet SSD (pour la détection […]
[…] sur une image directe (sans avoir à en ajouter plein à la fin) ! C’est le principe du MobileNet-SSD ! La version depthwise separable convolution ressemble à la version classique, à ceci près que […]
[…] Il y a deux ans nous découvrions ensemble le mobilenet-ssd au travers d’un TP basé sur Tensorflow. […]