
Il y a deux ans nous découvrions ensemble le mobilenet-ssd au travers d’un TP basé sur Tensorflow.
Les retours ont été très nombreux et positifs, car pouvoir entraîner une intelligence artificielle en quelques minutes/heures à reconnaître nos propres objets (par exemple de la nourriture, des oiseaux spécifiques, des ouvriers, des portes…) est un enjeu majeur de l’IA !
Aujourd’hui nous allons en découvrir ensemble une version revue, corrigée, et étendue (remise au gout du jour) de ce TP, mais n’hésitez surtout pas à le consulter car on ne reviendra pas dans le détail sur tous les points. Bonne lecture 🙂
PS : le TP sur le mobilenet-ssd est, aujourd’hui, compliqué à faire fonctionner à cause des conflits entre les versions des modules. Il est donc fortement conseillé de se baser sur cette nouvelle version.
Le « transfer learning » ou comment gagner des mois de calculs
Très souvent en deep learning, on a de beaux projets, « traducteur automatique temps réel d’une langue à une autre », « reconnaissance faciale pour accéder en toute sécurité à un salon », « prédiction de panne d’avion », « génération d’oeuvres d’art », etc, mais ils nécessitent en réalité une quantité phénoménale de données d’entraînement pour que la machine… apprenne !
Avec mon ordinateur de maison équipé de sa carte graphique gaming dernier cri et du meilleur processeur en rapport qualité/prix, il faudrait à mon IA des semaines de calculs pour passer en revue 100 000 images et en tirer des enseignements. A l’inverse, pour une cinquantaine d’ordinateurs dernier cri optimisés pour le calcul, ou même un super calculateurs, cela ne prendra que quelques heures seulement !
Sauf que la probabilité pour qu’une personne disposant de ce setup partage son IA entraînée et qu’elle concerne exactement mon besoin est nulle… non ? Eh bien comme vous vous en doutez, oui c’est impossible, mais par contre on peut « facilement » prendre une IA entraînée à une tâche générique et lui apprendre une nouvelle tâche proche de ce qu’elle faisait à l’origine, en seulement quelques heures/jours avec mon ordinateur personnel ! Voici trois grands cas où le transfer learning est incroyablement puissant :
- Reconnaissance d’objets : prenez une IA entraînée à reconnaître des dizaines d’objets classiques (via le jeu de données Coco pour Common Object COntext), montrez lui quelques centaines/milliers de photos d’un objet nouveau, et elle saura le retrouver ensuite !
- Analyse du langage : prenez BERT, une IA entraînée par Google sur des millions d’extraits de textes pour comprendre le langage humain, montrez-lui un corpus de code Python, et l’IA parlera le (codera en) Python !
- Transfert de style : prenez une IA capable de différentier les éléments d’une image, utilisez cette capacité pour extraire d’une image le contenu (i.e. les objets qui sont dedans) et pour tirer d’une autre le style (par exemple d’un peintre), mixez les deux et vous pouvez transférer le style de Picasso sur vos photos !
Reconnaissance (classification) d’image ou détection d’objet ?
En intelligence artificielle, il existe de nombreuses manières de travailler sur des images.
Par exemple, on peut dire si une image contient un avion, on peut dire où est l’avion dans l’image s’il existe (l’encadrer), on peut le surligner, on peut détecter plusieurs objets en simultané, on peut travailler sur les images d’une vidéo, etc…
Ceci étant deux problématiques principales ressortent :
- La classification d’image : par exemple, dire si telle image correspond à un chien ou à un chat
- La détection d’objet : par exemple, dire si dans telle image il y a un chien (et où) et dire s’il y a un chat (et où)

La classification d’image dit si une image correspond à la classe demandée. Ici, ça n’a pas trop de sens 
On demande la classe de l’image et où est l’élément correspondant (ici on demande « chat ») 
La détection d’objets revient à demander pour chaque type d’objet s’il est dans l’image et où 
La segmentation est plus précise que la détection classique, car au lieu d’encadrer on obtient le contour
Source des images (modifiées) ci-dessus : TeeFarm – Pixabay License
Pour entraîner une IA sur de la reconnaissance d’image, la technique est de lui fournir de nombreuses images ayant pour « classe » ce qu’on veut lui faire apprendre tandis que pour la détection il faut, en plus, encadrer « à la main » les objets à apprendre : cette étape peut être longue et fastidieuse
Dans ce TP, nous allons nous intéresser à la détection d’objets et plus particulièrement à « trouver un plat de mac’n’cheese dans une image ».
Codons notre détection d’objet personnalisée !
Avant de se lancer tête baissée dans le code, voici un aperçu de ce qui nous attend :
- Etape 0 : disposer d’un certains nombre de programmes/modules, a minima protobuf, git, tensorflow, numpy, virtualenv et en bonus labelimg, matplotlib, pandas, pycocotools…
- Etape 1 : télécharger les projets et tout mettre en place sur son disque dur
- Etape 2 : (facultatif) configurer ses propres objets à détecter et générer les fichiers pour l’entraînement
- Etape 3 : configurer le modèle pour le transfer learning
- Etape 4 : entraîner l’IA à partir du modèle pré-entraîné !
0. Les pré-requis
Il s’agit de la partie la plus longue et la plus laborieuse, mais vous n’aurez pas à le regretter ensuite !
Le coeur, indispensable
Commençons par installer Python 3.7.5. Pour la réalisation de ce TP, nous allons nous appuyer sur Tensorflow 1.13.2 : on verra alors qu’il n’est compatible qu’avec, au maximum, la version 3.7.X de Python, ce qui implique qu’il faut vraiment que vous téléchargiez les versions indiquées et ne changiez pas (il y aura des bugs sinon).
Télécharger Python 3.7.5 : prenez bien, par exemple pour un système 64bits, Windows x86-64 executable installer
Pour l’installation, il y a 2 cas de figure :
- Si vous avez déjà une version de Python 3 installée :
- exécuter l’installeur MAIS utilisez l’installation personnalisée (cf screenshots)
- ne pas ajouter Python au PATH ni aux variables d’environnement
- exécuter l’installeur MAIS utilisez l’installation personnalisée (cf screenshots)
- Sinon, installez normalement cette version de Python en pensant bien à l’ajouter au PATH/variables d’environnement(cf l’ancien TP si besoin)
- Dans tous les cas, le chemin d’installation de Python ne doit contenir aucun espace ! Pour ma part, je range les différentes versions de Python dans J:/Python (ici, ce sera le dossier Python375)
Remarque : les screenshots suivantes sont avec Python 3.8.2 mais vous devez installer Python 3.7.5 !
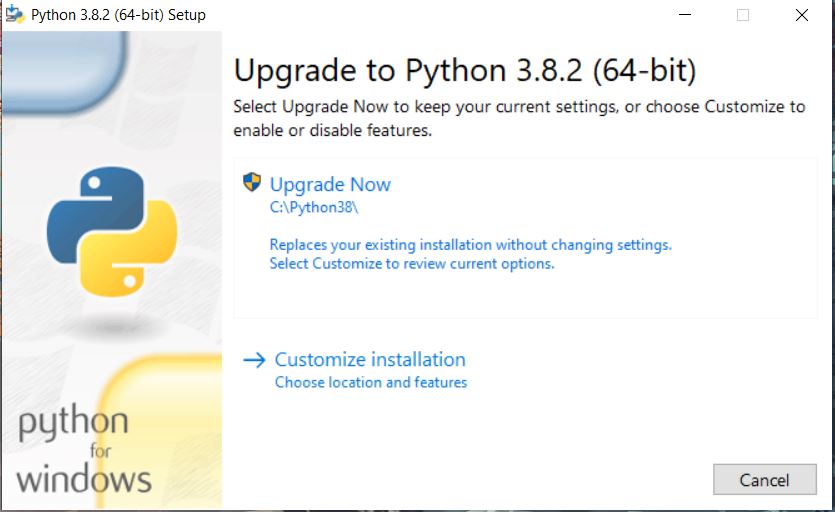
Cliquer sur « customize installation » pour choisir les options (enlever l’ajout au PATH si c’est demandé dans cet écran) (crédit : Lambert Rosique) 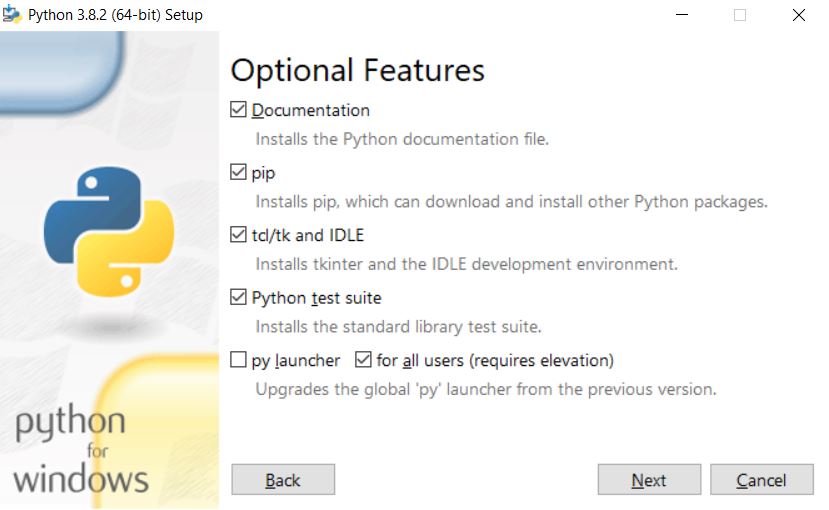
Laisser les options telles que proposées (sauf s’il y a l’ajout au PATH) (crédit : Lambert Rosique) 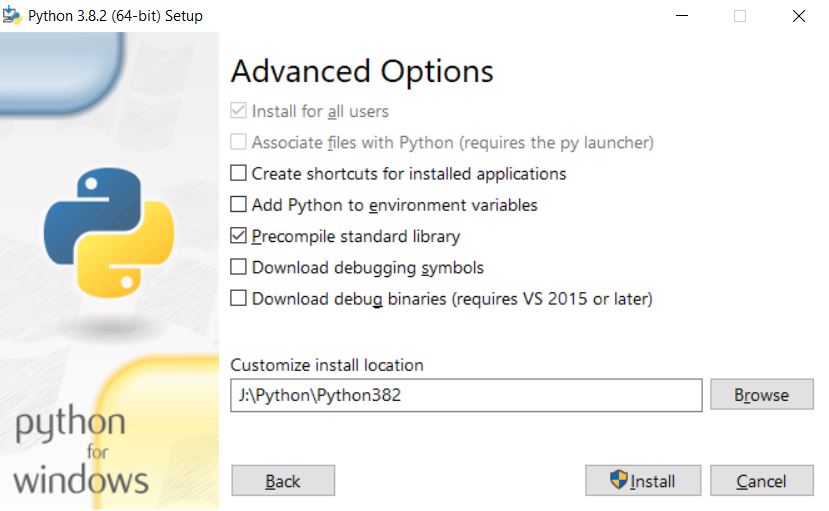
Désactiver l’ajout au PATH/variables d’environnement, et installer Python dans un chemin sans aucun espace (très important) (crédit : Lambert Rosique)
Utilisation de virtualenv
Suite au paragraphe précédent, dans tous les cas, vous avez une version de Python 3 fonctionnelle et ajoutée au Path sur votre ordinateur. Nous allons donc installer le module « virtualenv » qui va nous permettre de créer des environnements virtuels (on peut voir ça comme des sessions d’ordinateur différentes), chacun avec sa propre version de Python (celle que l’on souhaite mais qui doit être installée) et surtout avec ses propres modules !
De cette manière, si nos installations de modules (tensorflow par exemple) ne marchent plus, il suffira de recréer un environnement pour recommencer de zéro.
Dans une invite de commande, écrivez simplement :
pip install virtualenvImportant : notez qu’en fonction de votre installation active de Python il faudra écrire pip3 à la place de pip, et plus tard python3 au lieu de python
Ensuite rendez-vous grâce à la console dans le répertoire où vous voulez que votre environnement virtuel soit sauvegardé : pour changer de disque (par exemple passer de C à J) écrivez juste « J: » et pour naviguer faites « cd Python\envs ».
Pour ma part, je le range dans J:/Python/envs (pour rappel, mes versions de Python sont installées dans J:/Pyhon/PythonXYZ (ex pour ce TP : X=3, Y=7, Z=5)
Voici à présent la commande permettant de créer un environnement virtuel. Il est conseillé d’utiliser des noms d’environnements clairs pour savoir sur quel Python ils s’appuient et quelles sont leurs spécificités, ici ce sera tf-object-detection_py375_tf-1-13-2
A noter également que par défaut l’environnement utilisera la version de Python par défaut. Pour en utiliser une autre, il faut ajouter le paramètre -p suivi du chemin menant au Python voulu (le répertoire contenant python.exe)
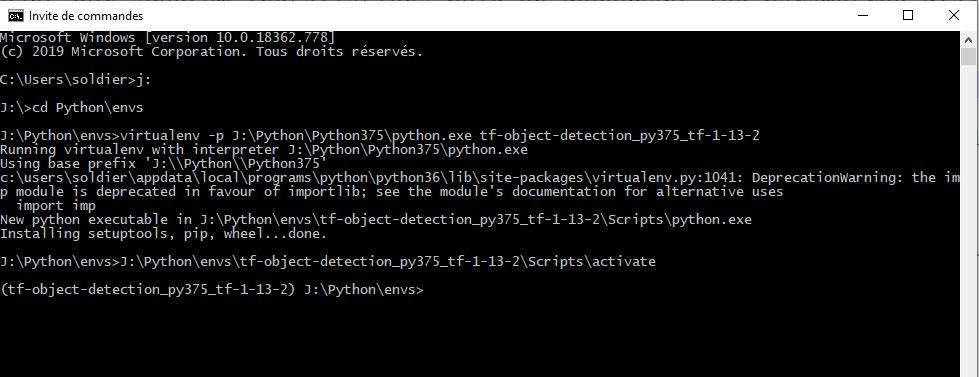
virtualenv -p J:\Python\Python375\python.exe tf-object-detection_py375_tf-1-13-2Enfin, pour se connecter à cet environnement vierge contenant uniquement Python 3.7.5 il suffit d’être dans le répertoire J:/Python/envs et de faire :
J:\Python\envs\tf-object-detection_py375_tf-1-13-2\Scripts\activateLa ligne suivante de la console doit alors commencer par le nom de votre environnement, indiquant que tout ce que vous exécuterez désormais le sera dans cet espace « virtuel ». La console doit maintenant rester ouverte et l’environnement activé : ce sera elle qu’on utilisera, sauf indication contraire.
Installation de Tensorflow, Numpy…
Pour que le TP fonctionne, nous allons avoir besoin d’une version très précise de Tensorflow et de Numpy, sans quoi il y aura des erreurs.
- tensorflow 1.13.2
- numpy 1.16
Les vieilles versions de tensorflow doivent être téléchargées « à la main », par exemple en notant l’URL pour télécharger la version voulue depuis le site https://pypi.org/project/tensorflow/
En allant donc sur cette adresse de tensorflow 1.13.2 on peut voir que plusieurs versions existent, chacune en fonction de notre ordinateur. Pour ma part ce sera :
- une version avec « cp37 » qui signifie Python 3.7
- une version avec en plus « win » pour Windows
- une version avec en plus « amd64 » car mon système est en 64bits
- ce qui m’amène au final à tensorflow-1.13.2-cp37-cp37m-win_amd64.whl (63.1 MB)
Faites clic droit sur le lien, copier l’adresse du lien, ce qui vous donne https://files.pythonhosted.org/packages/ee/89/5b4f6d1dc1d40307feff9068a03484e81d2441099d24a400c95127188783/tensorflow-1.13.2-cp37-cp37m-win_amd64.whl : nous allons pouvoir télécharger tensorflow dans la console grâce à la commande
pip install --ignore-installed --upgrade https://files.pythonhosted.org/packages/ee/89/5b4f6d1dc1d40307feff9068a03484e81d2441099d24a400c95127188783/tensorflow-1.13.2-cp37-cp37m-win_amd64.whl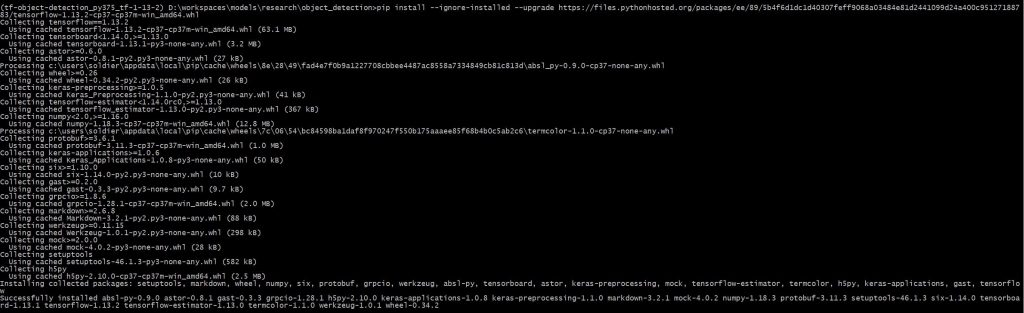
Maintenant, ce tensorflow vient avec la version 1.8 de Numpy (sinon ça peut être matplotlib ou pandas qui l’amènent). Si dans la pratique ces deux versions sont compatibles, pour notre projet (développé par Google) il s’avère qu’on va avoir une erreur bloquante… Pour la résoudre, lançons les commandes suivantes :
pip uninstall numpy
pip install numpy==1.16En bonus, si vous avez l’intention d’adapter cette IA à votre propre besoin, vous voudrez générer plus tard des fichiers csv et tf-records (comme expliqué dans l’ancien TP), donc il vous faudra :
pip install matplotlib
pip install pandasExemple d’erreurs avec les mauvaises versions de Tensorflow ou Numpy (ces erreurs sont visibles lors de l’entraînement, vous ne les aurez pas) :

Erreur liée à Tensorflow 1.14.0 (crédit : Lambert Rosique) 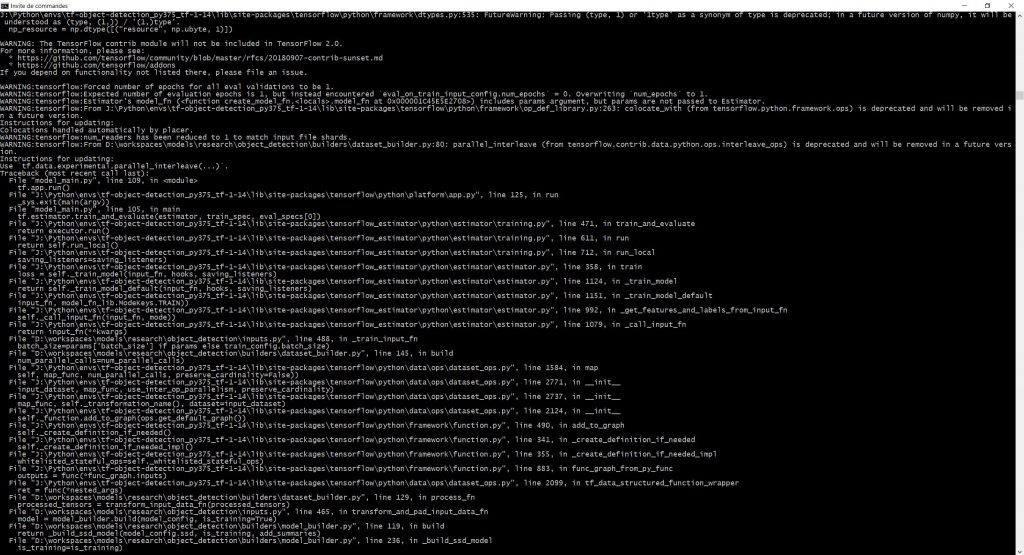
Erreur liée à Numpy 1.18 (crédit : Lambert Rosique) 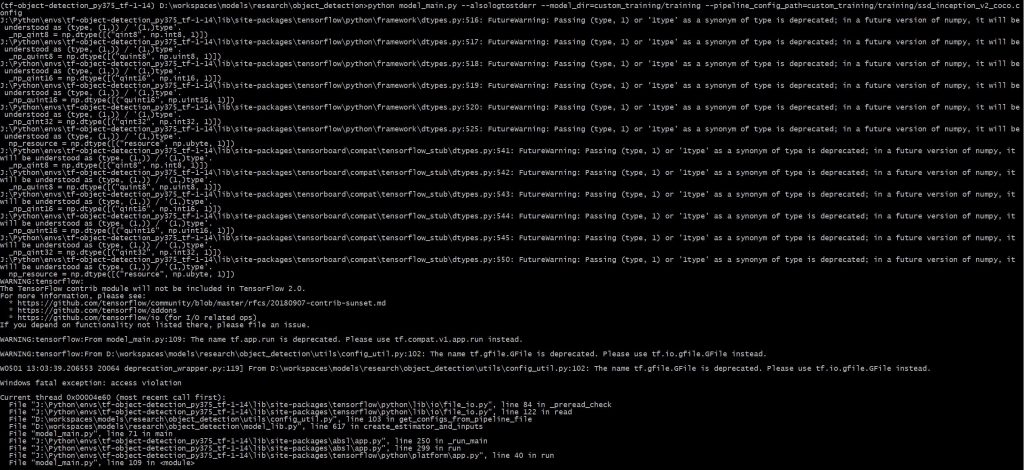
Erreur liée à la configuration du modèle (crédit : Lambert Rosique)
Installation de protobuf et labelimg
Vous n’en aurez besoin que si vous voulez entraîner l’IA avec vos propres images, car il faudra alors générer certains fichiers clés. Pour leur installation, je vous renvoie aux paragraphes correspondants dans mon ancien TP car ils fonctionnent toujours et cela permet d’alléger ce qui est dit ici pour se concentrer sur le « nouveau ».
Installation de PyCocoTools
Coco est un jeu de données annoté contenant des milliers d’images (330 000) avec des millions d’objets différents (80 possibilités). Beaucoup d’IA que nous allons pouvoir utiliser s’appuient dessus, donc il va nous falloir ce petit module pour que l’entraînement avec nos propres images fonctionnent.
PyCocoTools est « difficile » à installer sur Windows, voici la marche à suivre :
- Installer Visual C++ 2015 Build Tools disponible à cette adresse https://go.microsoft.com/fwlink/?LinkId=691126
- l’alternative est d’installer Visual Studio 2019 Community Edition, d’aller dans le gestionnaire de modules et de chercher Visual C++ 2015 Build Tools, ce qui est plus compliqué et long
- Aller dans le répertoire d’installation, normalement « C:\Program Files (x86)\Microsoft Visual C++ Build Tools » et lancer vcbuildtools_msbuild.bat (si possible en tant qu’administrateur) : une console doit s’ouvrir et se fermer rapidement (il se peut que ce soit tellement rapide qu’on ne le voit pas). Pour en voir le contenu, vous pouvez aussi lancer le .bat depuis une autre invite de commande (mais PAS depuis notre environnement virtuel)
- Installer également le programme Git qui permet notamment de gérer et télécharger des projets GitHub (PyCocoTools est dessus)
- Enfin lancer la commande suivante :
- l’alternative est de télécharger le projet soi-même et de l’installer depuis le répertoire de téléchargement mais c’est plus complexe et Git sert toujours !
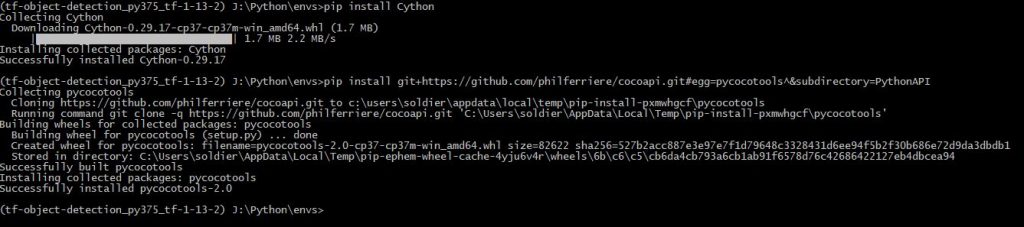
Remarque : PyCocoTools a besoin de Cython pour s’installer, d’où la ligne supplémentaire
pip install Cythonpip install git+https://github.com/philferriere/cocoapi.git#egg=pycocotools^&subdirectory=PythonAPI
1. Téléchargement du projet développé par Google Tensorflow
Passons à l’étape suivante : Google via Tensorflow propose de très nombreux projets de démonstration ou de recherche. L’un d’entre eux s’appelle « object_detection » ou détection d’objets et contient exactement ce que l’on veut : la possibilité de charger une IA déjà entraînée à reconnaître avec précision des dizaines d’objets et un script permettant de lui en enseigner un nouveau !
Voici quelques exemples de projets donnés :
- Deep_speech : une IA de reconnaissance du dialogue (comme dans l’assistant de Google)
- Inception : un modèle d’IA performant dans la vision par ordinateur
- Lstm_object_detection : de la reconnaissance d’objet dans des vidéos pour téléphone portable
- Sentiment_analyse : pour de la détection des sentiments liés à un texte
- …
Ce TP en particulier se base sur « Tensorflow detection model zoo » qui est dans le projet de recherche object_detection.
Pour continuer, nous allons devoir télécharger tout le dossier « models » de Tensorflow dans sa version 1.13. Il faut donc se rendre dans les archives ou télécharger directement le fichier de ce lien : https://github.com/tensorflow/models/archive/v1.13.0.zip (environ 430Mo).
Ensuite, il faut le dézipper dans un dossier, par exemple D:\workspaces, puis aller dans « D:\workspaces\models\research\object_detection »
- Créez-y le répertoire « custom_training »
- Ouvrez ce dossier custom_training
- Créez-y le dossier « images »
- Créez-y le dossier « pre-trained-model »
- Créez-y le dossier « records »
- Créez-y le dossier « training »
On est prêts pour la suite !
A noter que je vais parler dorénavant du « nouvel objet à détecter », mais en réalité vous pouvez apprendre à l’IA plusieurs nouveaux objets d’un coup.
2. Préparer les données : celles de ce TP ou les siennes
Pour la partie 3 nous allons avoir besoin de 2 choses :
- La présence des fichiers train.record et test.record dans le dossier records, ainsi que label_map.pbtxt
- ces fichiers contiendront la liste de toutes les images personnalisées avec l’emplacement de l’objet à détecter
- La présence des dossiers train et test dans le dossier images, avec les images et les fichiers xml d’annotation correspondants
Important : peu importe ce que vous voulez faire, téléchargez impérativement le projet donné au début du Cas 1 !!!
Cas 1 : télécharger les données du TP
Commençons par télécharger le projet GitHub de Pensée Artificielle avec les images et les fichiers clés pour la suite (même si on aura l’occasion de les télécharger séparément pour que vous voyiez comment faire).
Lien vers le projet GitHub de Pensée Artificielle
Remplacez votre dossier « images » par celui du projet téléchargé (dont on pourrait renommer le dossier principal en custom_training) pour avoir toutes les images. Si vous ne comptez pas re-générer les fichiers « .record », vous pouvez supprimer tout ce qui n’est pas dans les sous-répertoires train et test.
Dans le dossier « records », placez les trois fichiers train.record, test.record et label_map.pbtxt
Nous sommes prêts pour la partie suivante !
Cas 2 : générer ses propres images
Pour cette partie nous allons fortement nous appuyer sur l’ancien TP dédié au mobilenet-ssd. En voici les grandes lignes (qui ne seront pas détaillées du coup) pour aboutir à la fin du Cas 1 :
- A l’aide du logiciel LabelImg, on encadre dans chacune de nos images personnalisées l’endroit où se trouve le nouvel objet à détecter (et on indique de quel objet il s’agit) et ce, pour toutes nos images
- LabelImg génère des fichiers xml pour chaque image avec les informations renseignées (position du rectangle et classe de l’objet)
- Remarque : on peut découper aléatoirement les images pour les placer dans les répertoires train et test grâce à un script donné à cette adresse, dont s’inspire grandement l’ensemble de ce TP.
- Ensuite on va compiler toutes ces informations des XML dans deux fichiers CSV grâce à un script « xml_to_csv.py » pour regrouper au même endroit nos données
- Les CSV sont convertis alors en fichiers RECORD qui contiennent les mêmes informations mais de manière plus rapidement accessible pour Tensorflow, grâce à « generate_tfrecord.py »
- Les fichiers train.record et test.record sont générés
- Pour finir, on crée le fichier label_map.pbtxt dans le dossier records, qui doit contenir la description de nos classes. Voici celui du projet de Pensée Artificielle :
item {
id: 1
name: 'macncheese'
}Remarque : vous devrez exécuter une partie du code de la partie 4 pour pouvoir lancer ces scripts
3. Configuration du modèle
On en arrive au coeur de tout ce travail : le choix du modèle pré-entraîné que nous allons spécialiser pour répondre à notre besoin !
Dans l’ancien TP, nous avions utilisé « mobilenet-ssd ». Pour varier, on va s’appuyer cette fois sur inception-mobilenet, mais la liste des modèles potentiels est très large, chacun ayant ses propres forces et faiblesses. Je vous encourage donc à en tester d’autres…
Nous allons avoir besoin de deux éléments distincts (il faut bien sûr que les noms correspondent) :
- Le modèle pré-entraîné, qui se présentera sous la forme de plusieurs fichiers qui vont contenir les « poids » figés des « neuronnes » de l’IA : https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
- Le fichier de configuration de cette IA pour la ré-entraîner à reconnaître nos objets : https://github.com/tensorflow/models/tree/master/research/object_detection/samples/configs
A noter qu’il y a souvent le fichier de configuration inclus avec le modèle, mais il vaut mieux utiliser celui proposé par Tensorflow.
A noter également que pour le modèle ssd_inception_v2 présenté ici, le fichier de configuration générait une erreur (cf plus haut). Il ne faut pas hésiter à chercher sur Google l’origine des éventuels problèmes, ici résolus grâce à un autre fichier « à jour » : on ne va PAS utiliser le fichier donné par Tensorflow mais celui du projet GitHub de Pensée Artificielle…
Téléchargeons ssd_inception_v2_coco depuis le premier lien et dézippons-le dans le dossier « pre-trained-model » : on obtient le sous-dossier « ssd_inception_v2_coco_2018_01_28 »
Téléchargeons ensuite la configuration de ce modèle (à noter qu’on l’a déjà avec pipeline.config mais qu’il vaut mieux passer par celle de tensorflow) grâce au second lien à mettre dans un fichier que l’on nommera ssd_inception_v2_coco_2018_01_28.config dans le dossier training. Cette configuration m’ayant généré des erreurs, vous pouvez repartir du fichier du projet de ce TP.
Les lignes à modifier sont les suivantes :
- Ligne 9 : num_classes: 1 (pour indiquer le nombre de nouvelles classes à apprendre)
- Ligne 138 : batch_size: 12 (pour que les calculs soient plus rapides, mais la qualité finale sera moindre)
- Ligne 153 : fine_tune_checkpoint: « custom_training/pre-trained-model/ssd_inception_v2_coco_2018_01_28/model.ckpt »
- Lignes 171 à 174 :
label_map_path: « custom_training/records/label_map.pbtxt »
tf_record_input_reader {
input_path: « custom_training/records/train.record »
}
- Lignes 185 à 188 :
tf_record_input_reader {
input_path: « custom_training/records/test.record »
}
label_map_path: « custom_training/records/label_map.pbtxt »
Comment utiliser un autre modèle que ssd_inception_v2 ??
Très bonne question, car il n’est pas dit que ssd_inception_v2 vous corresponde parfaitement (ou peut-être voudrez-vous en tester d’autres, car chaque modèle peut remplir une tâche plus ou moins bien : je vous y encourage !). Pour changer, la marche à suivre est simplement de suivre le paragraphe précédent en changeant les liens utilisés ! Voici un exemple raccourci :
- Dans la liste du 1er lien précédent (detection_model_zoo.md), je repère le modèle « ssd_mobilenet_v2_coco » qui m’intéresse
- Je clique sur le nom en question, ce qui déclenche le téléchargement d’un dossier compressé
- Une fois le téléchargement terminé, je décompresse ce dossier directement dans mon dossier pre-trained-model : j’obtiens ainsi un dossier ssd_mobilenet_v2_coco_2018_03_29 (contenant le modèle de l’IA gelée)
- Pour la partie « modèle » je n’ai plus rien à faire, maintenant il me faut configurer le « pipeline d’entraînement » (autrement dit la manière dont on va utiliser le modèle pour apprendre)
- Dans la liste du 2e lien précédent (samples/configs), je retrouve le même modèle : « ssd_mobilenet_v2_coco«
- Je clique dessus, ce qui m’ouvre un fichier de 194 lignes : je copie les 194 lignes et je les colle dans un fichier « ssd_mobilenet_v2_coco_2018_03_29.config » (le nom est le même que le dossier du modèle, pour trouver rapidement quel pipeline configure quel modèle) que je crée dans mon dossier training
- Ensuite, j’ouvre mon fichier ssd_mobilenet_v2_coco_2018_03_29.config et je modifie les lignes comme indiqué dans la partie précédente en adaptant si besoin (les paramètres peuvent changer d’un modèle à l’autre, il faut donc bien tout lire, et attention à la ligne fine_tune_checkpoint à bien changer pour le chemin du modèle du ssd_mobilenet !
- Pour terminer, dans ma commande d’entraînement de l’IA (donnée en partie 4), je devrai changer le chemin donné dans ce paramètre : pipeline_config_path
4. Entraînement (ou plutôt spécification) de l’IA
Pour terminer, nous allons exécuter un ensemble de commandes qui vont tout d’abord préparer notre environnement puis déclencher l’apprentissage du modèle pré-entraîné.
Préparation du projet
Dans la console avec l’environnement virtuel, commençons par construire le projet Research de Tensorflow et lançons protobuf :
D:
cd workspaces\models\research
protoc object_detection/protos/*.proto --python_out=.
set PYTHONPATH=D:\workspaces\models\research;D:\workspaces\models\research\slim
python setup.py install
protoc object_detection/protos/*.proto --python_out=.
Ensuite voici les commandes de la partie 2 pour rappel (si vous venez de la partie 2, vous pouvez y retourner l’environnement et les scripts vont fonctionner), à ne PAS exécuter dans cette partie !
cd object_detection
python xml_to_csv.py
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.recordPour finir, voici la commande qui va déclencher l’entraînement. Notez bien les différents paramètres et leurs valeurs pour les adapter à vos dossiers et, surtout, au modèle d’IA que vous utilisez !
python model_main.py --alsologtostderr --model_dir=custom_training/training --pipeline_config_path=custom_training/training/ssd_inception_v2_coco_2018_01_28.configSi tout se passe bien vous devriez obtenir une console de ce type :
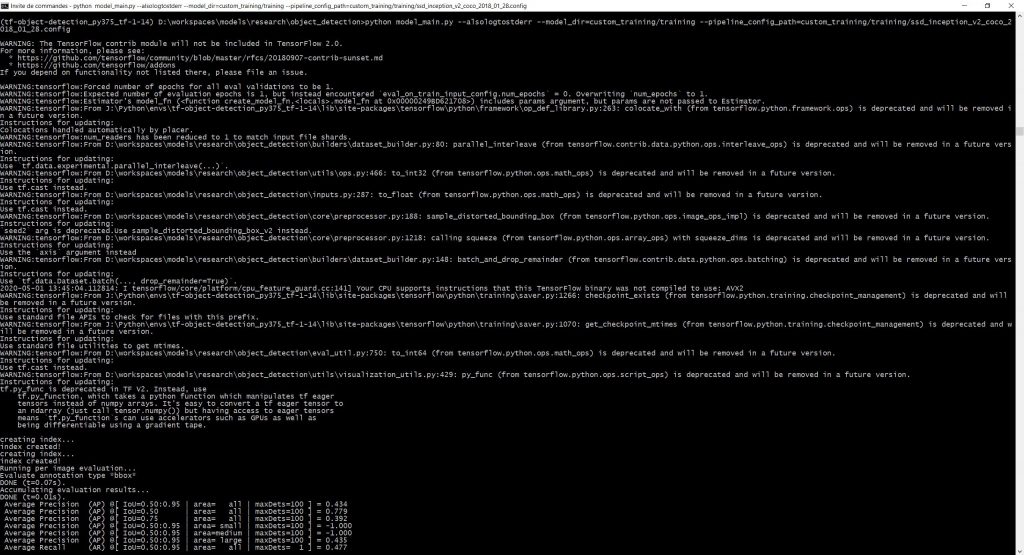
montrant ainsi que l’apprentissage démarre. Notez les deux éléments suivants pour évaluer le temps total que cela va prendre :
- Si vous avez demandé « 1 epoch » d’apprentissage, cela signifie que le script va passer en revue toutes vos images (disons 1000) une fois
- Ce qui compte alors c’est de savoir la taille du batch (batch_size), que j’ai changé à 12 (au lieu de 24)
- Ainsi, dans mon cas, l’IA va réaliser 1000/12 = 84 apprentissages
- Un apprentissage correspondant à un groupe de lignes en bas de la console, cela signifie que j’en ai pour quelques heures…
- Mais si vous avez configuré votre Tensorflow pour utiliser votre carte graphique (avec tensorflow-gpu), le temps devrait être divisé par environ 10 par rapport aux screenshots de cet article !
Quelques exemples d’erreurs que vous pourrez rencontrer (en plus de celles données précédemment)
Exemple d’erreur dans le cas où il nous manquerait une dépendance :

On voit ci-dessus qu’une dépendance, absl, n’a pas été installée. Je tente immédiatement un « pip install absl », mais malheureusement ce n’est pas le nom du module dans le répertoire qui gère tous les modules Python ! Suite à une recherche sur Google (en écrivant pip install absl), je découvre que le module s’appelle absl-py et peut donc l’installer.
Exemple d’erreur dans le cas où vos images ne sont pas « adaptées » à l’IA :
Toutes les images fournies au ssd-inception doivent être au format .jpg, peu importe leur taille ou leur résolution. En revanche, elles doivent toutes avoir 3 canaux qui sont R, G et B. Les images en niveaux de gris ou avec un canal alpha (transparence comme les png) feront planter le script ! Voici l’erreur obtenue si vos images sont incorrectes (il en suffit d’une seule) :
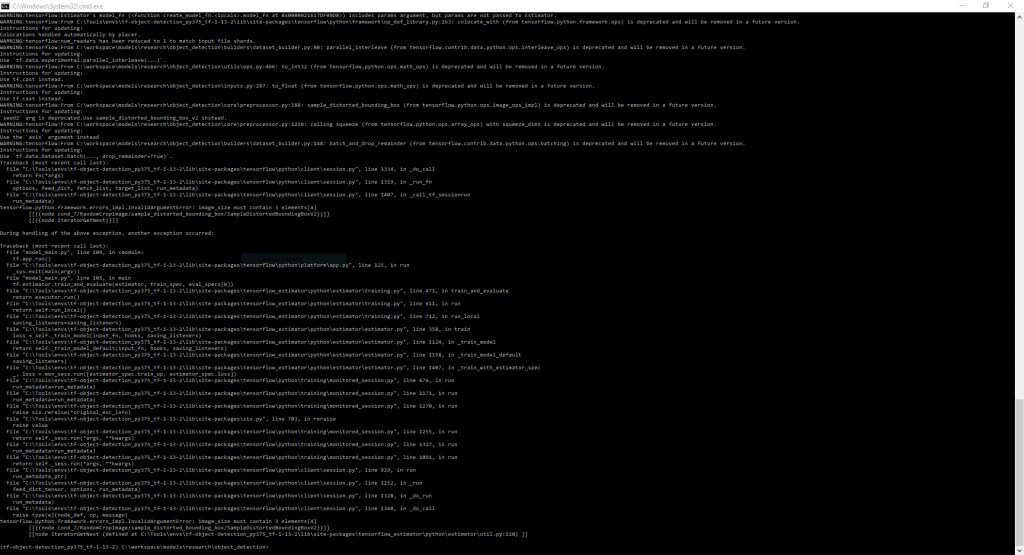
Pour retrouver les images en cause, voici un petit script Python qui vous aidera bien (il vous faut le module pillow via pip install pillow) :
from PIL import Image
import os
path="D:/workspaces/models/research/object_detection/custom_training/images"
for file in os.listdir(path):
extension = file.split('.')[-1]
if extension == 'jpg':
fileLoc = path+"/"+file
img = Image.open(fileLoc)
if img.mode != 'RGB':
print(file+', '+img.mode)Si des images sont incorrectes, vous obtiendrez une liste dans votre console (je vous conseille alors de supprimer ces images) avec la cause de l’erreur (tout doit être en RGB pour que ça marche, et non P ou RGBA ou autre) :
000.jpg, P
011.jpg, RGBA
016.jpg, RGBA
019.jpg, RGBA
029.jpg, P
071.jpg, P
105.jpg, P
108.jpg, RGBA
922.jpg, P
Et maintenant ? Comment enregistrer ou utiliser mon IA ?
Je ne vais pas rentrer dans les détails ici, car le problème a été traité dans l’ancien tutoriel. Je vous renvoie donc sur le tutoriel du mobilenet-ssd pour :
- enregistrer votre modèle (et éviter qu’il soit perdu)
- charger votre modèle entraîné par vos soins
- utiliser votre modèle dans un cas concret
Conclusion
Dans ce TP nous avons pu aller plus loin qu’avec le MobileNet-SSD : le code est plus récent, contient des dizaines de modèles utilisables et est plus rapide si vous utilisez votre carte graphique pour les calculs.
On a ainsi pu prendre une intelligence artificielle pré-entraînée sur d’énormes machines pendant des jours (ce qui prendrait, sur mon ordinateur, des années) capable de reconnaître, maintenant, 80 objets quasiment instantanément, et on lui a fait découvrir un nouvel objet inconnu (des plats de mac’n’cheese) en quelques minutes/heures !
Le transfer learning est probablement l’application la plus pratique et générale de l’intelligence artificielle en entreprise, j’espère que vous avez apprécié ce TP et que vous le réutiliserez 🙂
Crédit de l’image de couverture : montage réalisé à partir des images de Coco – CCA 4.0 License



{kind=link}