
Après avoir trouvé LA fonction d’activation (Mish) pour nos réseaux de neurones, je vous propose de découvrir (et comprendre) ensemble le meilleur optimizer, qui va encore améliorer les prédictions et la stabilité de vos Intelligences Artificielles.
Nous nous focaliserons ainsi sur les deux algorithmes qui composent Ranger (RAdam et LookAhead) avec force d’explications avant de passer à la pratique via FastAI !
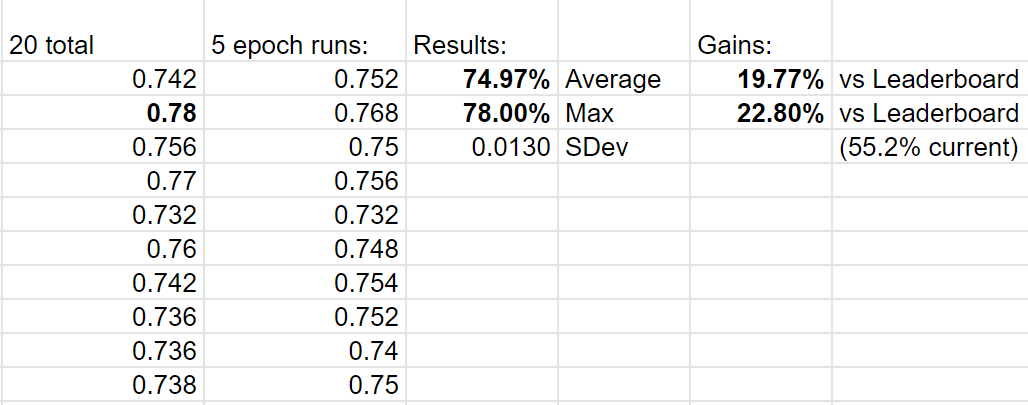
PS : Ranger, combiné à Mish, a permis d’améliorer certains records (sur FastAI) du jeu de données ImageWoof de 20% ! On est, par exemple, passés de 55.2% de précision à 78% sur 5 époques ! (et ce, pour 12 records différents)
A quoi sert un optimizer ?
Pour apprendre, une intelligence artificielle dispose de données d’exemple avec leurs prédictions attendues, à partir desquelles elle va devoir construire son modèle (on parle d’apprentissage supervisé, car on veut que l’IA s’inspire de ces exemples). Par exemple, on va indiquer à l’IA qu’un appartement T3 de 60m² coûte 100k€, qu’un appartement T2 de 70m² coûte 150k€, etc… et elle devra en extraire des « règles » permettant de déduire le prix d’un appartement T3 de 100m².
Pour s’améliorer, on va comparer les prédictions de l’IA aux valeurs attendues : c’est la fonction d’erreur commise par l’IA. Typiquement, si elle prédit qu’un T3 de 60m² coûte 120k€ (au lieu de 100k€), alors son erreur sera de 20k€. Un algorithme dit « optimizer » (optimiseur en français mais peu usité) joue alors le rôle de corriger l’algorithme de l’IA (par exemple les poids d’un perceptron) pour que, la fois suivante, elle prédise un nombre plus proche de 100k€ que 120k€ !
Remarque : la fonction de coût (ou d’erreur), appelée loss function en anglais, peut prendre différentes formes et ce n’est quasiment jamais « prédiction – valeur attendue ».
Remarque : une donnée d’apprentissage est présentée plusieurs fois à l’IA qui va se tromper de nombreuses fois ! En effet, le but de l’optimizer n’est PAS d’avoir une erreur nulle pour un exemple mais d’avoir l’erreur la plus faible possible (au « total ») sur tous les exemples (en particulier dans un apprentissage par batch).
Le rôle de l’optimizer est déterminant : il va définir comment évolue (apprend) une IA pour s’adapter aux données d’entraînement

A noter qu’à partir d’ici, lorsqu’on parlera d’optimizer on aura en tête, généralement, une application orientée deep learning (via des réseaux de neurones artificiels par exemple).
Quelques optimizers connus
Gardons en tête que l’objectif d’un optimizer est de nous faire avancer sur la courbe de la fonction de coût (en couleurs à gauche) pour aller vers le minima global (point le plus bas de la courbe).
Une analogie avec le fait de descendre des montagnes sera utilisée par la suite.
Voici une petite animation permettant de voir la convergence de quelques optimizers sur une courbe de coût pour un réseau de neurones :
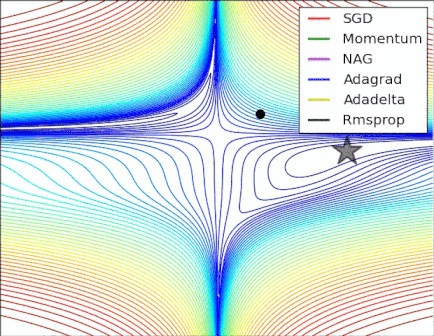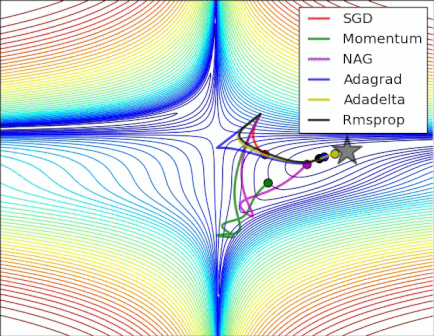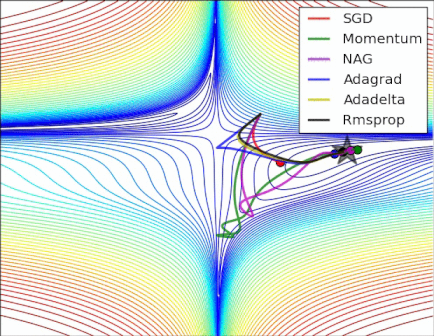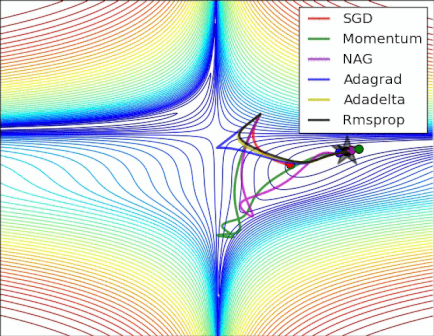
La descente de gradient (Gradient Descent en anglais)
Il s’agit de l’une des techniques d’optimisation commune de Machine Learning, que l’on découvre souvent en premier. Cette technique a été déclinée en de nombreux algorithmes avec leurs spécificités : descente de gradient par batch, stochastique (SGD), mini-batch, …
Dans la pratique, la descente du gradient consiste à calculer le gradient de la fonction de coût (la dérivée de « l’erreur » par rapport aux paramètres de l’IA que l’on peut mettre à jour) puis à mettre à jour les paramètres (par exemple les poids d’un réseau de neurones artificiels) dans la direction qui fera diminuer l’erreur.
Elle est rapide, efficace, robuste et surtout flexible en ce sens où on l’utilise dans de nombreux algorithmes, que ce soit pour du Deep Learning avec les réseaux de neurones au Machine Learning plus traditionnel.
Adam (Adaptative Momentum estimation)
Il s’agit de l’optimizer le plus utilisé (surtout pour les réseaux de neurones) en raison de son efficacité et de sa stabilité (même si, comme nous le verrons, elle n’est pas parfaite).
Pour le présenter, nous devons d’abord saisir la notion de momentum. Par exemple, jetez un rocher dans la pente d’une montagne : à mesure qu’il va rouler dans la même direction il va gagner en vitesse, mais s’il tourne, sa vitesse sera réinitialisée. Pour Adam, le principe est identique : tant que le gradient est dans la même direction que ceux précédents, on va accélérer la vitesse (dite d’apprentissage) à laquelle on descend la courbe (i.e. on met à jour les paramètres).
A noter qu’Adam combine les idées d’Adagrad et de RMSprop.
Adagrad (Adaptative Gradient)
On ne va pas trop rentrer dans les détails, car cet algorithme n’est plus vraiment utilisé depuis qu’Adam existe, sauf pour les jeux de données épars. Typiquement, si certaines données sont rares (avoir des exemples de prix d’appartements T5 par rapport à T2 ou T3), Adagrad sera adapté.
En effet, sa spécificité est de proposer une vitesse d’apprentissage différente pour chaque paramètre de l’IA ! Ainsi, on corrige plus rapidement les paramètres qui interviennent rarement sans perdre le tuning de ceux qui sont plus fréquents…
RMSprop (Resilient Momentums prop)
Cet algorithme RMSprop est une version alternative d’Adagrad et ressemble à de la descendre de gradient avec momentum (la différence se fait au niveau du calcul mathématique du gradient).
L’optimiseur RAdam : fini le stress du choix de la vitesse d’apprentissage
Maintenant que l’on connait un peu mieux les optimizers, intéressons-nous à RAdam, l’évolution d’Adam qui en corrige la faiblesse principale : sa forte dépendance en la vitesse d’apprentissage.
En effet, comme le montre le schéma (ci-dessous) des courbes d’apprentissage (précision de l’IA sur les données de test en première ligne), avec Adam nos résultats finaux dépendent fortement du choix de la vitesse d’apprentissage (learning rate) de notre algorithme !
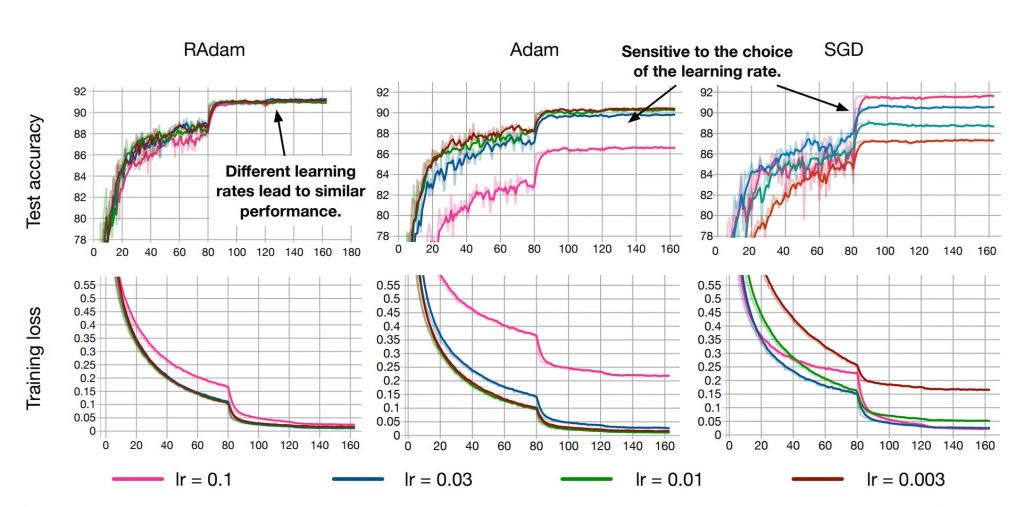
Ainsi, pour une vitesse d’apprentissage de 0.1, on atteint en un peu plus de 80 époques :
- 91% de précision en utilisant RAdam
- 86% de précision avec Adam
- 92% de précision avec SGD
MAIS on voit que si on avait choisit une autre vitesse, par exemple 0.003 alors les résultats auraient été très différents. Pour SGD, on aurait atteint 87% de précision.
La force de RAdam est de ne pas dépendre en cet hyper-paramètre du réseau de neurones : peu importe la vitesse d’apprentissage initiale, l’algorithme converge vers la même précision ! Il n’est alors plus nécessaire de réaliser ce qu’on appelle un « warm-up » (pré-entraînement avec une vitesse d’apprentissage très faible pour préparer l’IA au vrai entraînement).
Comment fonctionne et mettre en place l’optimiseur RAdam ?
RAdam, pour Rectified Adam, a été présenté par Liu, Jian, He et al dans le papier donné en source de l’image précédente. Il s’agit d’une variation de l’optimiseur Adam dont le principe était d’accélérer la vitesse d’apprentissage (on dit qu’elle est adaptative, car elle varie en fonction des gradients) tant qu’on va dans le même sens que les gradients précédents.
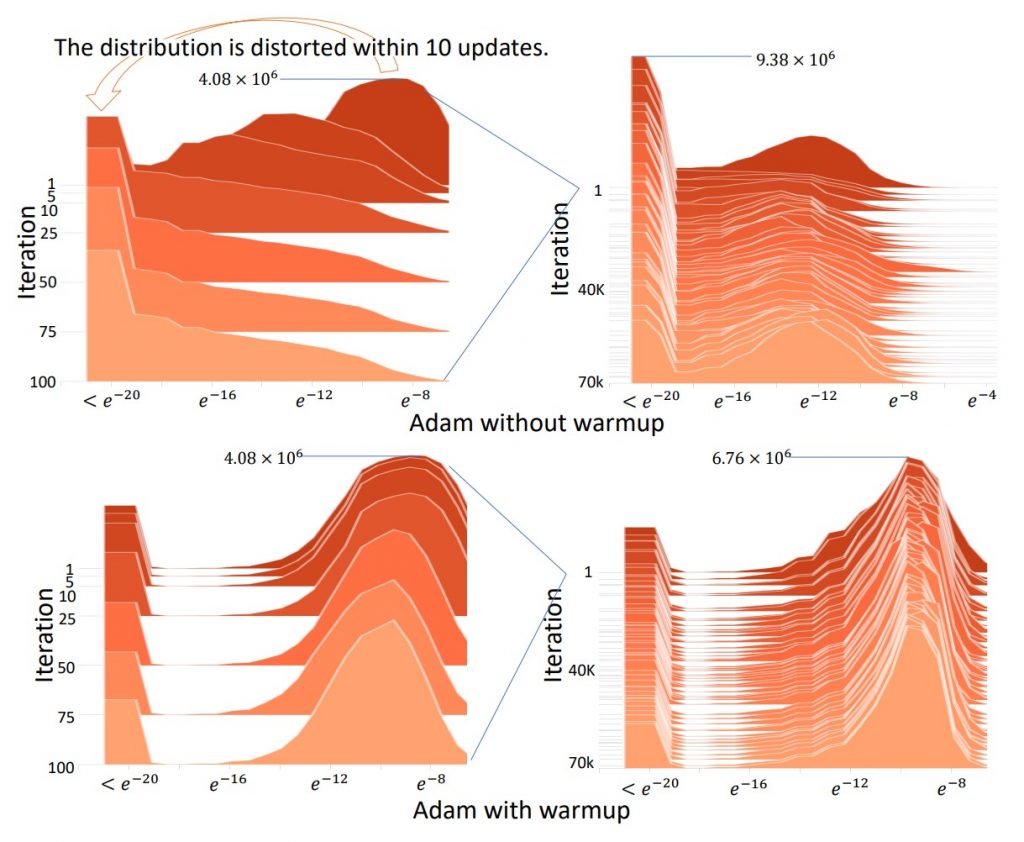
Ici, un terme spécial a été introduit pour rectifier la variance (au sens statistique) de la vitesse d’apprentissage adaptative qui avait tendance à accélérer trop vite dans la « mauvaise direction » (à cause de l’absence de warmup et de la valeur initiale de cette dernière).
Pour utiliser RAdam, on commence par installer le module keras-rectified-adam grâce à la commande suivante (à saisir dans la console) :
pip install keras-rectified-adamPuis il suffit dans notre code Python d’ajouter les quelques lignes suivantes :
# Import
from keras_radam import RAdam
# Définition de l'optimizer (avec quelques paramètres qu'il faudra adapter à ses besoins)
opt = RAdam(total_steps=5000, warmup_proportion=0.1, min_lr=1e-5)
# Utilisation de l'optimizer dans un model (déjà configuré avant)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])L’optimiseur LookAhead : l’exploration du futur
Comme le disent justement Zhang, Lucas, Hinton et Ba dans leur article introduisant l’algorithme LookAhead, les optimiseurs qui améliorent le traditionnel SGD (« stochastic gradient descent » en anglais ou descente de gradient stochastique) sont répartis en deux familles :
- Ceux qui reposent sur une vitesse d’apprentissage adaptative basée sur le momentum (c’est le cas d’Adam et de RAdam). Ils vont adapter le gradient aux paramètres de l’IA pour prendre en compte une absence d’exemples dans les données d’apprentissage. Ils vont augmenter ou diminuer la vitesse d’apprentissage en fonction des gradients précédents pour « nous faire accélérer dans les grandes lignes droites » (si on reprend l’analogie de la montagne que l’on descend)
- Et ceux qui s’appuient plutôt sur une notion d’accélération : par exemple, les algorithmes (Polyak) Heavy Ball et Nesterov Momentum qui travaillent sur la notion d’accélération au lieu de la vitesse pure (on a donc des dérivées secondes)
LookAhead, pour sa part, sort de ce carcan en proposant une approche innovante (basée sur un nouveau mécanisme d’exploration de l’espace). Le principe est le suivant : au lieu de travailler à l’amélioration directe des poids de notre réseau de neurones, LookAhead va chercher à optimiser deux lots de poids (qu’il va maintenir).
- Les poids dits rapides (fast weights) : ils sont mis à jour k fois (souvent k vaut 5) d’affilée en fonction des données d’apprentissage, avec un optimizer standard par exemple Adam. Ces poids rapides sont les poids qui vont regarder ce que réserve l’avenir (on dit « look ahead » en anglais) pour que les poids lents puissent partir « dans la bonne direction »
- Les poids lents (slow weights) : quand les poids rapides ont changés k fois, on regarde où se trouve la dernière version de ces derniers –> c’est dans cette direction que sont mis à jour les poids lents grâce à LookAhead !
Si l’on reprend notre analogie, un algorithme classique voulant descendre de la montagne se retrouvera parfois dans des vallées qu’il prendra du temps à quitter, tandis que LookAhead fournira un scout capable de partir explorer les vallées autour de vous avant de vous prévenir s’il vaut mieux les contourner pour gagner du temps…
Remarque : la mise à jour des poids rapides se fait grâce à un optimiseur classique, par exemple Adam ou SGD. Celle des poids lents, en revanche, est un mécanisme interne de LookAhead. Le calcul des nouveaux poids dépend donc d’une formule différente d’Adam ou SGD (ligne « Perform outer update… » de l’algorithme ci-dessous).
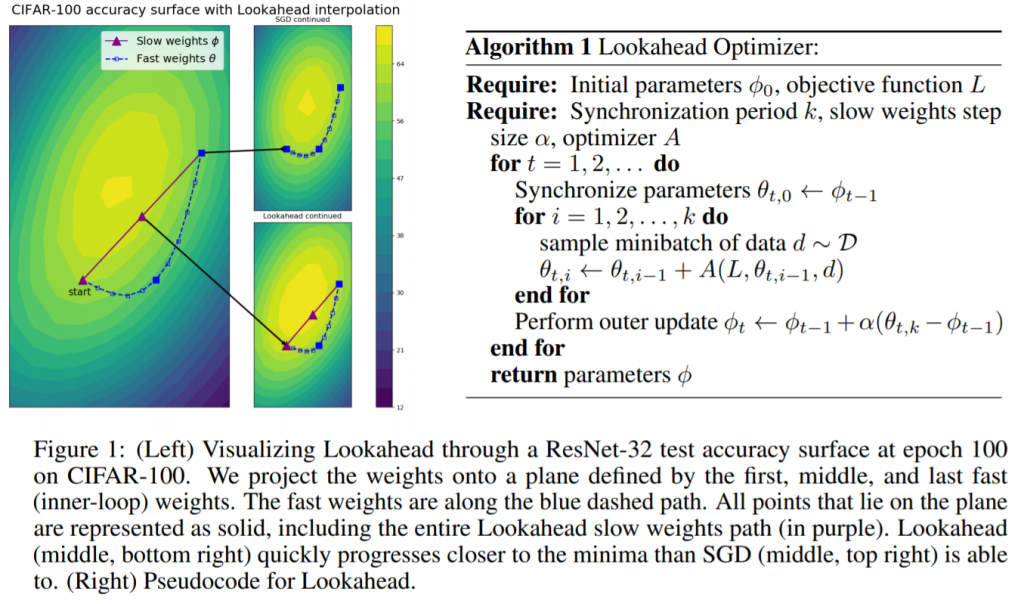
Voici, enfin, une petite animation du fonctionnement de LookAhead :
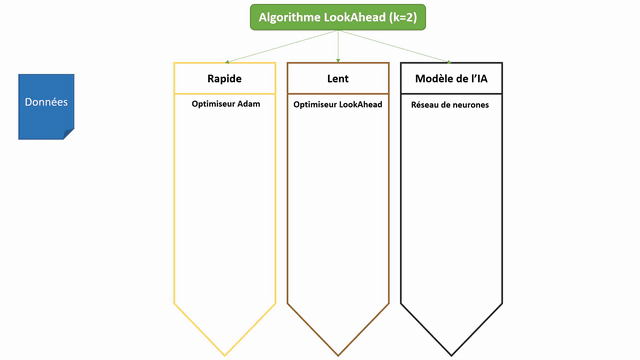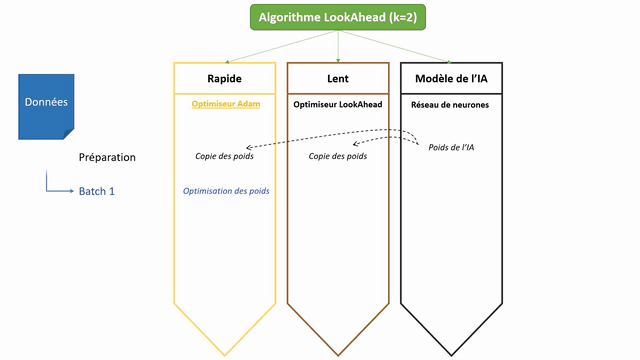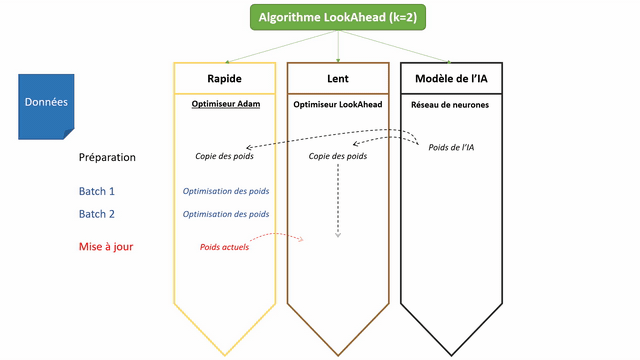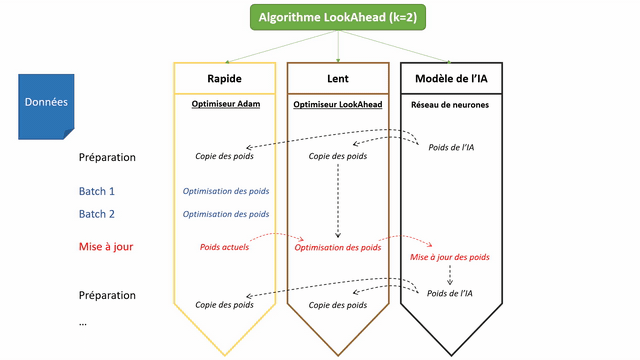
Comment utiliser LookAhead ?
### LookAhead peut être utilisé de manière très simple, comme RAdam
# Import de LookAhead
from optimizer import Lookahead
# Définition de l'optimiseur utilisé pour l'exploration avec les fast weights
# Ici, on charge l'optimiseur grâce à PyTorch mais on peut adapter la solution à d'autres frameworks
import torch.optim as optim
fast_opt = optim.Adam(model.parameters(), lr=0.001)
# Définition de l'optimiseur Lookahead avec le "base_optimizer" qui est l'algorithme utilisé par les fast weights
opt = Lookahead(base_optimizer=opt, k=5, alpha=0.5)Le meilleur optimizer : Ranger !
Vous l’aurez compris, LookAhead est un optimizer très puissant mais qui utilise Adam et présente donc les problèmes présentés au début de l’article (à savoir, la dépendance en un warmup). Heureusement, Less Wright spécialiste en IA, PyTorch et FastAI, a eu l’idée de proposer une version de LookAhead qui reposerait, cette fois, sur RAdam (algorithme inconnu des auteurs du papier original) !
Ainsi, Ranger est simplement l’algorithme « LookAhead » dont les poids rapides sont calculés à l’aide de l’optimizer RAdam (au lieu d’Adam).


Qu’est-ce que « FastAI » ? Comment utiliser Ranger ?
FastAI est une startup (issue d’un professeur, Rachel Thomas, et d’un chercheur, Jeremy Howard, de l’Université de San Francisco) dont l’objectif premier est d’accompagner les développeurs d’intelligences artificielles.
Pour ce faire, ils se sont basés sur le framework PyTorch et y ont inclus de nombreux algorithmes très populaires et ont simplifié la syntaxe, à l’image de ce qu’apportait Keras à TensorFlow. FastAI est donc, à son tour, un framework d’intelligence artificielle spécialisé dans le Deep Learning, et dispose de tutoriels assez simples comme nous allons le voir.
Installation de FastAI
1) Téléchargement de Python 3
Tout d’abord, il vous faut Python 3 dans son avant-dernière version. Pourquoi ne pas prendre la dernière, me direz-vous ? En général, la dernière n’est pas supportée par TensorFlow ainsi que par de nombreuses autres librairies, donc je conseille vivement de prendre celle qui précède. Par exemple, à l’heure où j’écris ces lignes : la dernière est la 3.8.0, l’avant-dernière la 3.7.5 !
2) Installation de Microsoft Visual C++ 14
Pour que FastAI puisse s’installer, nous allons avoir besoin de Microsoft Visual C++ 14.0, sans quoi nous aurons l’erreur « error: Microsoft Visual C++ 14.0 is required«
ATTENTION : l’installation de MVC++14 n’est pas du tout intuitive, car les noms ne correspondent pas à ce qu’on attend d’eux… Soyez donc vigilants :
- Il faut tout d’abord télécharger Visual Studio 2019 (qui est un installeur avec Build Tools) dans la version Community (gratuite) !
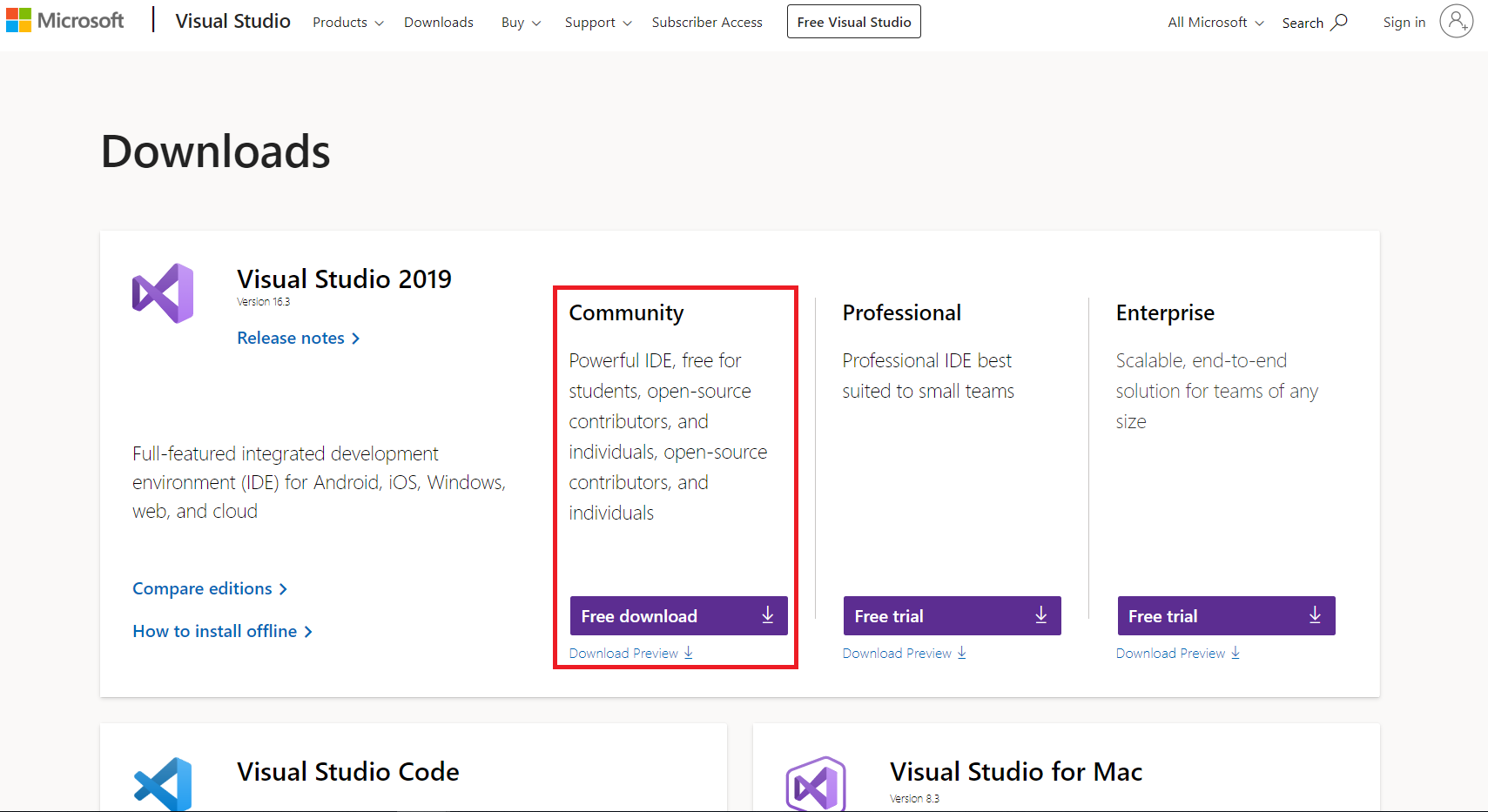
- Ensuite, nous allons installer Microsoft Visual C++ 14.0 (qui ne s’appelle pas exactement comme ça ici) : dans « Charges de travail », cochez « C++ Build Tools » puis dans « Facultatif » à droite ajoutez l’une des lignes suivantes
- MSVC v142… ou
- MSVC v141… ou
- MSVC v140…
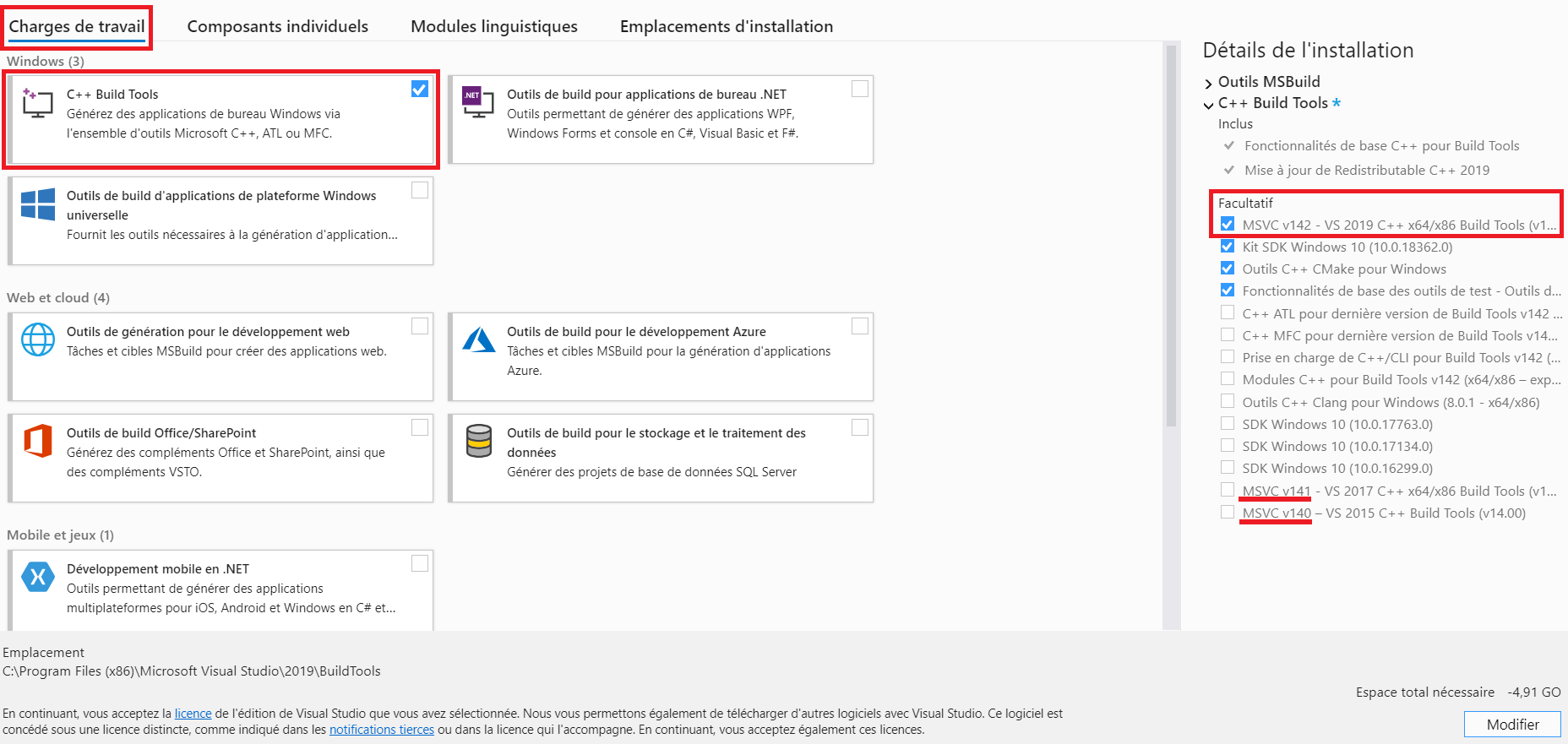
A noter que les trois versions semblent fonctionner avec FastAI, donc j’ai tendance à utiliser la dernière (MSVC v142…). Pensez à redémarrer votre ordinateur ensuite.
PS : pour revenir à cet écran (comme moi pour la screenshot, ce qui explique l’espace nécessaire négatif) si vous n’avez pas installé le bon package, il suffit de relancer l’installateur, d’aller dans « Installé » et pour Visual Studio Build Tools 2019 cliquer sur « Plus » puis « Modifier »
3) Installation de FastAI
Enfin, dans une invite de commande, saisissez tout simplement (attention, suivant votre configuration il faudra écrire pip3 au lieu de pip)
pip install fastaiUtilisation de Ranger sur un projet
Remarque : en réalisant ces projets, je me suis aperçu que Ranger a besoin de suffisamment d’époques pour battre systématiquement Adam (car Adam est sensible à la vitesse d’apprentissage, donc sur un « bon » paramétrage il reste très fort). Je vous encourage donc à réaliser vos propres tests, et, surtout, à ne jamais utiliser qu’une seule approche. Par exemple avec Mish, nous avions vu que la fonction d’activation était meilleure que ReLU dans 55 cas sur 75 (il ne faut donc pas utiliser Mish aveuglément).
Ici la proportion reste à déterminer, mais ce que l’on peut dire avec certitude c’est que Ranger+Mish a battu 12 records du jeu de données ImageWoof de 20% (on passe de 55% de précision à 78%) pour certaines configurations…
Téléchargement de Ranger
Si la fonction d’activation Mish que nous avions vu il y a quelques jours était disponible facilement avec un « pip install », ce n’est pas le cas de Ranger pour l’instant (mais il est probable que l’optimizer soit inclus dans des frameworks très bientôt).
Il faudra donc télécharger le fichier ranger.py sur ce github et le placer dans le répertoire de votre projet, avec votre fichier de code Python.
Remarque : le code est adapté à PyTorch uniquement. Pour tout autre framework, vous pouvez utiliser directement LookAhead en changeant la ligne d’Adam par RAdam.
Ensuite, il suffit d’importer dans votre code les librairies « fastai », « torch » puis d’appeler Ranger en tant qu’optimizer (et éventuellement Mish en fonction de coût, pour davantage d’amélioration).
Ranger avec FastAI et PyTorch
Maintenant que l’on a FastAI et Ranger de prêt, cela va aller très vite : on va coder un réseau de neurones artificiels pour répondre au jeu de données du MNIST (reconnaissance des chiffres écrits à la main par un humain via une IA) et utiliser Ranger plutôt que SGD ou Adam.
Le code peut paraître long car on donne ici beaucoup de code alternatif, mais il tient en seulement 9 lignes (dont 3 lignes d’import) ! De manière générale, avec FastAI on peut écrire et entraîner une IA en 4 à 10 lignes…
# Deactivate a warning message spamming the console :
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module="torch.nn.functional")
# Inspired from : https://towardsdatascience.com/multi-layer-perceptron-usingfastai-and-pytorch-9e401dd288b8
from fastai.basics import *
from fastai.vision import *
from ranger import Ranger
%matplotlib inline
''' Downloading the dataset '''
path = untar_data(URLs.MNIST)
## Bonus :
# See where the dataset is saved
#path.ls()
# Look inside the training folder
#(path/'training').ls()
##
''' Load the dataset '''
# Augment data
ds_tfms = get_transforms(do_flip=False, flip_vert=False, max_rotate= 15,max_zoom=1.1, max_lighting=0.2, max_warp=0.2)
# Load, transform and split data
data = (ImageList.from_folder(path, convert_mode='L')
.split_by_folder(train='training', valid='testing')
.label_from_folder()
.transform(tfms=ds_tfms, size=28)
.databunch(bs=128))
## Bonus :
# Simplest version of the loading of a dataset is :
#data = ImageDataBunch.from_folder(path)
# Display some examples from the dataset
#data.show_batch(rows=3, figsize=(10,6), hide_axis=False)
''' Define the model '''
class MNIST_NN(nn.Module):
def __init__(self):
super().__init__()
self.lin1 = nn.Linear(784, 512, bias=True)
self.lin2 = nn.Linear(512, 256, bias=True)
self.lin3 = nn.Linear(256, 10, bias=True)
def forward(self, xb):
x = xb.view(-1,784)
x = F.relu(self.lin1(x))
x = F.relu(self.lin2(x))
return self.lin3(x)
## Bonus :
# Other syntax :
#model = nn.Sequential(nn.Linear(784, 128),
# nn.ReLU(),
# nn.Linear(128, 64),
# nn.ReLU(),
# nn.Linear(64, 10),
# nn.LogSoftmax(dim=1))
''' Learner '''
mlp_learner = Learner(data=data, model=MNIST_NN(), loss_func=nn.CrossEntropyLoss(),metrics=accuracy,opt_func=Ranger)
## Bonus :
# Some models are already included in FastAI
#learner = cnn_learner(data, models.resnet18, metrics=accuracy)
# Find the best learning rate (USELESS WITH RADAM)
#learner.lr_find()
#learner.recorder.plot()
''' Train the network '''
mlp_learner.fit_one_cycle(5,1e-3)
## Bonus :
# Simplest version of it is
#learner.fit(1)(pour plus d’exemples, je vous recommande de jeter un oeil sur le code du github de Less Wright, que je remercie pour son aide et son travail sur Ranger)
Ranger avec PyTorch sans aucune autre librairie
Voici un exemple de code PyTorch utilisant Ranger pour le jeu de données du MNIST.
from ranger import Ranger
import torch
import torch.optim as optim
from torch import nn
from torchvision import datasets, transforms
# Transformer
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# Load dataset
## Train
trainset = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
## Test
testset = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=False, transform=transform)
testloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# Model
model = nn.Sequential(nn.Linear(784, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10),
nn.LogSoftmax(dim=1))
# Loss
criterion = nn.NLLLoss()
# Optimizers
optimizer = Ranger(model.parameters()) ### optim.SGD(model.parameters(), lr=0.003)
# Training and testing
epochs = 5
for e in range(epochs):
train_loss = 0
test_loss = 0
# Training the model
for images, labels in trainloader:
images = images.view(images.shape[0], -1)
optimizer.zero_grad()
prediction = model(images)
loss = criterion(prediction, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
# Testing the model
model.eval()
with torch.no_grad():
for images, labels in testloader:
images = images.view(images.shape[0], -1)
prediction = model(images)
test_loss += criterion(prediction, labels).item()
print(f"Training loss {train_loss/len(trainloader)} - "+f"Test loss: {test_loss/len(testloader)}")Crédit de l’image de couverture : article sur Arxiv



{kind=link}