
Après avoir battu des humains dans des jeux de réflexion (échecs, GO), une nouvelle intelligence artificielle, Libratus, a battu 4 des meilleurs joueurs de Poker au monde !
Si on pouvait penser que les algorithmes n’ont pas leur place dans ce genre de compétition où le bluff et l’expérience l’emportent sur le calcul « pur et simple » de probabilité, l’IA a su s’adapter et gagner.
Une IA dédiée au poker
A l’inverse des jeux traditionnels, les plus grandes difficultés au poker sont :
- la dissimulation d’informations (on ne voit pas les cartes de l’adversaire)
- la falsification d’informations (on bluffe en faisant croire qu’on a certaines cartes en main)
Pour travailler dans ce type d’environnement, il fallait donc une intelligence artificielle dédiée, dont l’algorithme évolutif permettrait d’exploiter le peu d’informations dont elle dispose…

Libratus, du latin « équilibré », a ainsi pris 15 millions d’heures-coeur de calcul d’un supercalculateur aux Etats-Unis pour s’entraîner. La stratégie, comme pour n’importe quelle IA basée sur de l’apprentissage (en particulier le renforcement), n’est pas déterminée à l’avance. Ici, c’est la méthode de minimisation du regret hypothétique (alias CFR, pour Counterfactual Regret Minimization) qui a été retenue. CFR peut être expliquée en quelques points clés :
- C’est un algorithme d’entraînement avec soi-même : l’IA apprend en jouant contre elle-même
- On appelle regret ce qu’on aurait gagné à jouer telle action fixée à tel moment pour toutes les parties précédentes, par rapport à ce qu’on a fait là.
Par exemple, au jeu de Pierre-Papier-Ciseaux, si on joue pierre et que notre adversaire joue feuille, on perd. On regrettera donc de ne pas avoir joué ciseaux. Le regret sera « si dans toutes mes parties précédentes, est-ce qu’en jouant ciseaux directement, j’aurais plus gagné qu’en suivant ma stratégie actuelle ? ». Si on n’a fait qu’une partie, la réponse est directement oui. Mais si notre adversaire jouait souvent pierre lui aussi, alors la réponse pourrait être non et la stratégie serait peut-être de ne plus jouer feuille…
- Au départ, la stratégie est aléatoire, mais après chaque partie toutes les décisions prises sont revues grâce aux regrets :
- Si le regret est positif, il faudra changer plus souvent l’action pour celle calculée
- S’il est négatif, alors on a fait la meilleure chose possible et il faut continuer ainsi
- Notre stratégie est ainsi revue pour qu’elle tienne compte des regrets positifs (la probabilité de faire une action dépend donc de son intérêt pour nous faire gagner globalement)
Autrement dit, on ne cherche pas à gagner une partie mais le maximum de parties.
L’algorithme ne converge pas toujours, sauf dans le cas du poker où il est possible d’atteindre ce qu’on appelle « l’équilibre de Nash« , qui est une stratégie gagnante si elle est parfaitement respectée puisque, sur un grand nombre de parties, on obtient qu’en moyenne :
- si l’adversaire suit une stratégie de Nash, on finira à égalité
- s’il joue une stratégie parfaite qui contre Nash, on finira aussi à égalité
- et sinon, à la moindre erreur, je gagnerai
On ne gagne donc que par la meilleure défense qui soit (en exploitant les erreurs de l’adversaire pour marquer des points).
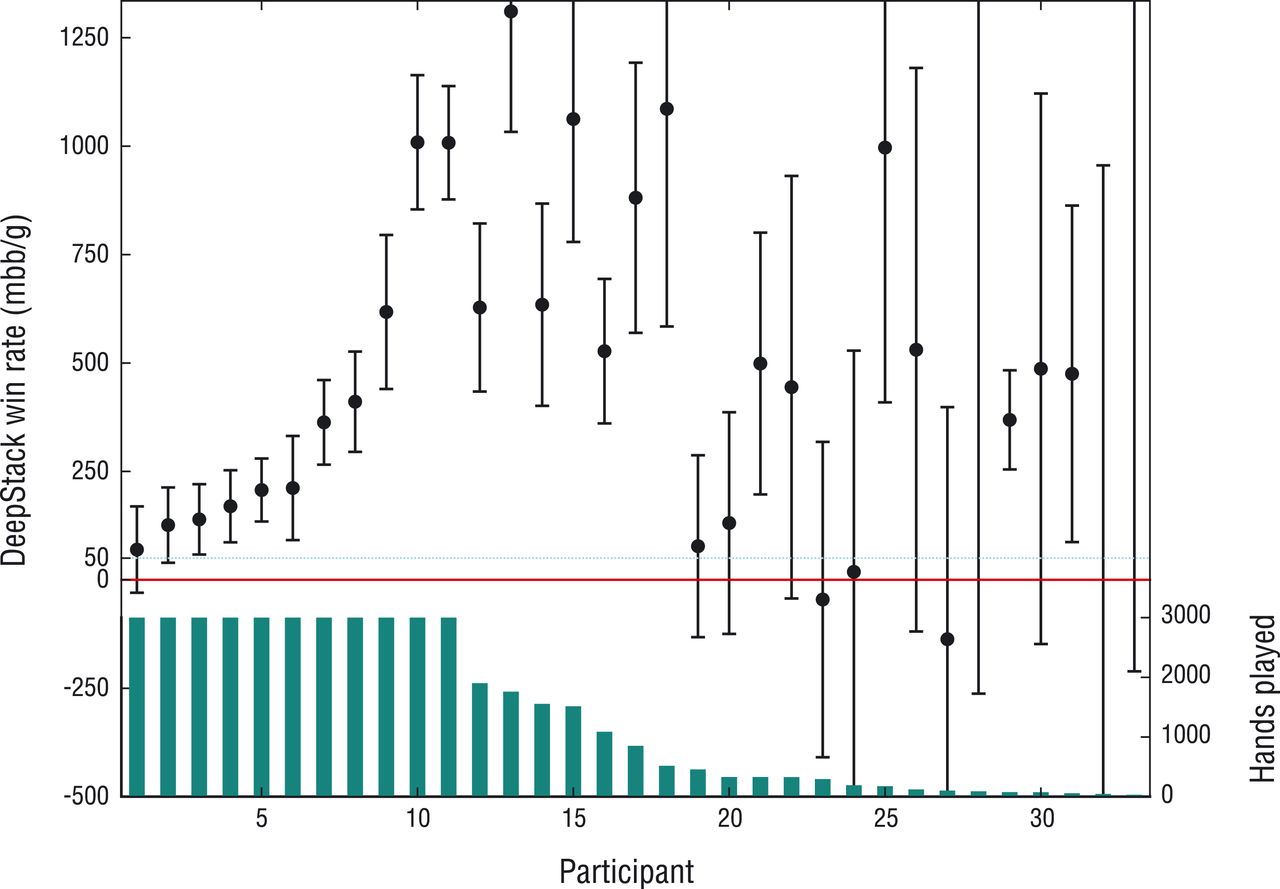
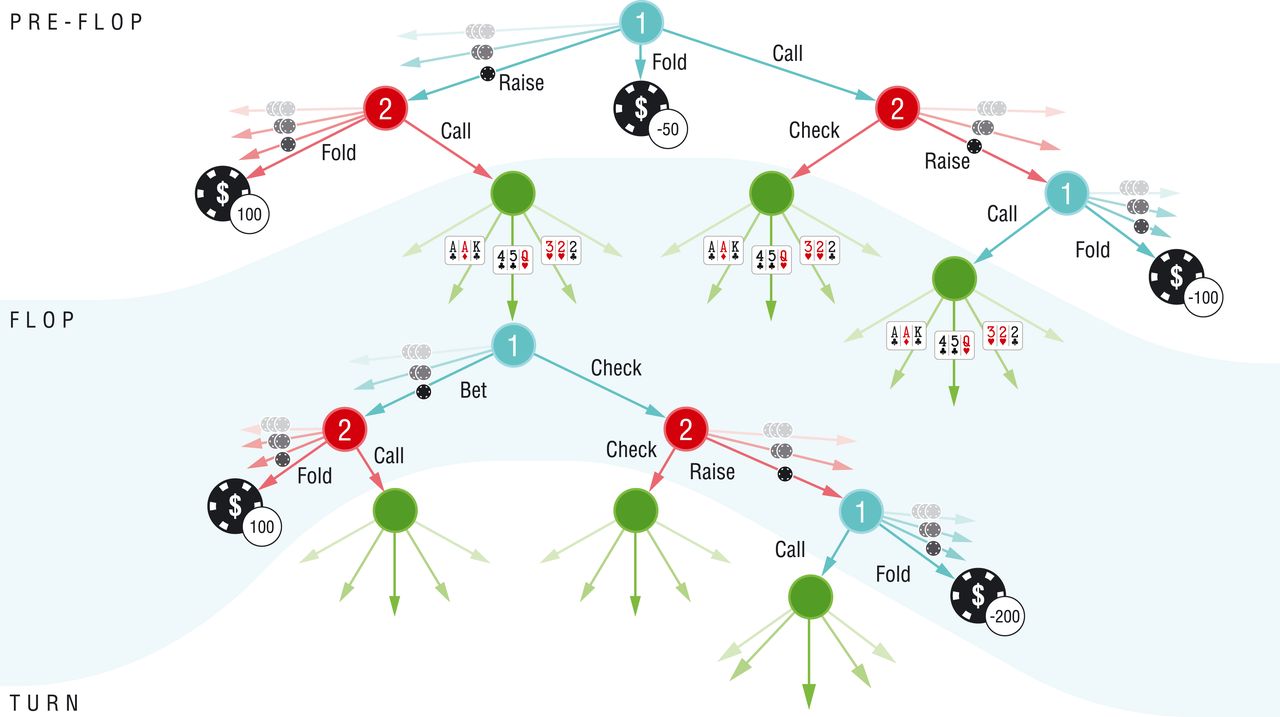
Une autre intelligence artificielle, nommée DeepStack (qui sera le sujet d’un autre article) et également dédiée au poker a ainsi pu réaliser le palmarès suivant lors de parties contre des vrais joueurs. On y découvre en particulier qu’elle est toujours positive tandis que tous les humains perdent de l’argent.
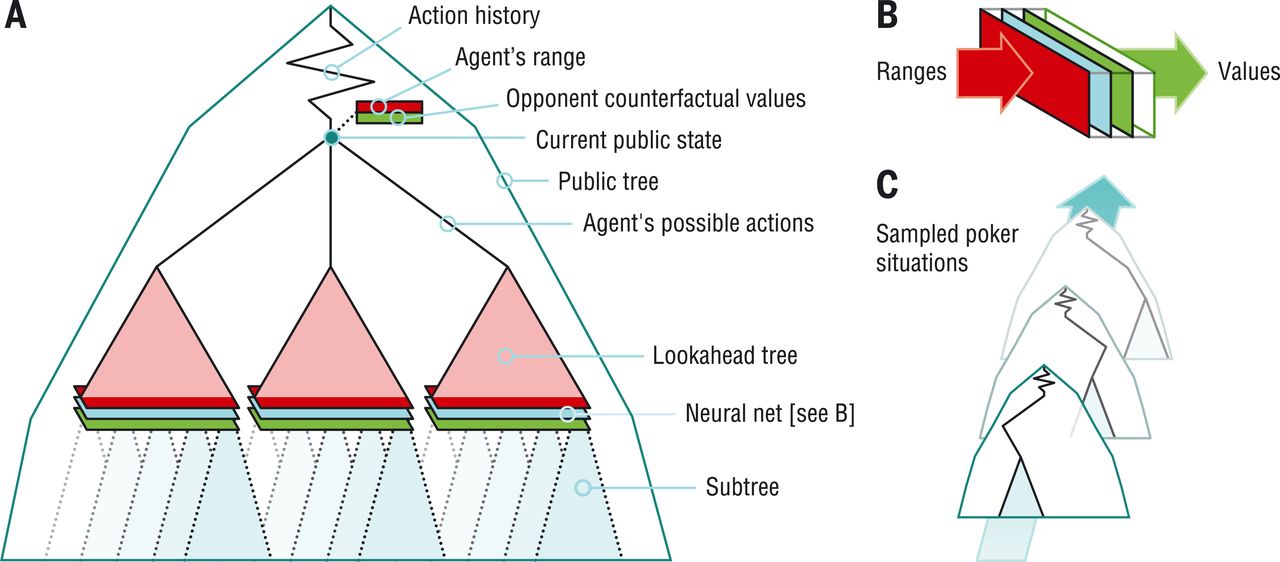
A titre d’information, on donne l’architecture de l’IA.

Le tournoi de 2017 qui combine IA, poker et humains
Du 11 au 31 janvier 2017, Libratus a affronté quatre des meilleurs joueurs de poker professionnels : Jimmy Chou, Dong Kim, Jason Les et Daniel McAulay, au Texas Hold’em No-Limit à deux joueurs.

Les règles étaient simples, et l’objectif était d’évaluer les progrès en intelligence artificielle dans le domaine du poker, grâce à l’événement Brains VS Artificial Intelligence. Le No-Limit, i.e. partie dont les mises et relances sont libres, est fréquent à haut niveau, mais on restreint rarement le nombre de participants à deux.
Ici, pour limiter le temps de calcul et d’entraînement de Libratus (dont toute la stratégie apprise repose sur du 1 contre 1), les organisateurs ont proposé un tournoi. A noter également que cette restriction n’était pas suffisante pour qu’un supercalculateur puisse entraîner Libratus, et donc qu’une variante de CFR, nommée CFR+ a dû être implémentée (mise au point par l’équipe qui a développé Libratus).
En plus de tout cet entraînement préalable et très spécifique, l’IA continuait de s’améliorer la nuit, apprenant des résultats de la veille, pour mieux tenir compte de ses adversaires et de ses propres failles.
Au final, les résultats sont sans équivoque : l’IA a empoché 1.7 million de dollars, au détriment de ses adversaires.
Reste maintenant à voir ce que vaut Libratus contre DeepStack !
Crédit de l’image de couverture : Gerd Leonhard – CC BY-SA 2.0



, une nouvelle intelligence artificielle, Libratus, a battu 4 des meilleurs joueurs de Poker au monde ! IA, poker et humains, pendant 20 jours, ont été réunis dans la même salle, jusqu'au sacre de l'IA...){kind=link}
{kind=link}