
Ce besoin revient souvent, en particulier lorsqu’on débute en Machine Learning, qu’on est étudiant… ou qu’on préfère consacrer son temps à du fine-tuning.
En effet, le nombre d’algorithmes est faramineux (il suffit de regarder la carte de KnowMap pour s’en convaincre), et les résultats potentiels de chacun sont variables (on peut avoir 20% de prédictions correctes comme 99% avec la même IA, simplement en changeant certains paramètres) !
Dans cet article nous allons voir deux grandes familles de problèmes traités par l’IA, à savoir les régressions et les classifications, puis un outil très pratique pour tester en un clin d’oeil des dizaines d’algorithmes (avant de choisir celui qui fonctionne le mieux).
Les deux types principaux de problèmes résolus avec l’IA supervisée
On parle de modèle d’intelligence artificielle supervisé lorsque celle-ci apprend par le biais de données d’exemple. Typiquement : « voici les caractéristiques mesurées (superficie d’un logement et nombre de pièces), et voici ce qu’il faut prédire pour ces caractéristiques (le prix du logement) ». Cette méthode d’apprentissage s’oppose au non-supervisé qui désigne des intelligences artificielles pour lesquelles on fournit des données uniquement, la tâche étant de les ranger/grouper de manière « logique » (ex : on veut regrouper des fleurs par ressemblance sans avoir de résultat particulier attendu).
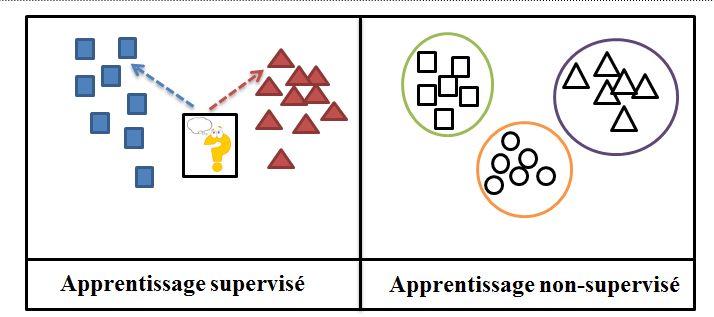
Dans cet article, nous allons nous intéresser à deux grands types de problèmes endémiques de l’IA supervisée : la régression et la classification.
Comprendre la régression en IA
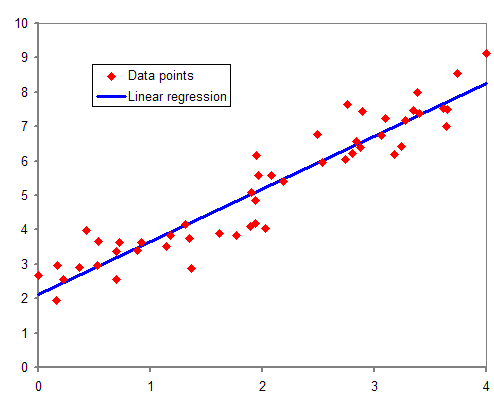
Littéralement en mathématiques, la régression est le fait d’approcher une variable (le prix d’un appartement) à partir d’autres qui lui sont liées (la superficie et le nombre de pièces).
Pour atteindre cet objectif, plusieurs modèles d’approches sont possibles : approcher les données par une droite (cf exemple ci-contre) = régression linéaire, par un polynôme = régression polynômiale, par une fonction logarithmique, etc…
Par extension, on appelle régression en intelligence artificielle tout problème qui consiste à prédire une variable qualitative (i.e. un nombre) ! La prédiction de l’IA sera donc généralement une valeur comprise entre -1 et 1.
Les domaines d’application sont nombreux, des finances (prédiction du cours de la Bourse…) au commerce (stocks futurs à prévoir…) en passant par la maintenance prédictive (anticiper une panne).
Comprendre la classification en IA
La classification, comme le nom l’indique, repose sur des classes : ce sont les problèmes pour lesquels l’objectif est de prédire une classe parmi un ensemble fini. On a notamment :
- Déterminer si l’animal présent dans l’image est un chat, un chien ou un lapin »
- Evaluer la gravité d’un cancer (bénin ou malin, l’équivalent en régression serait de prédire le risque de décès en pourcentage) »…
- Ainsi que de très nombreux autres exemples
La classification présentée ainsi ressemble à un problème lié à de l’apprentissage non-supervisé, mais ce n’est pas le cas. La différence est qu’en non-supervisé les classes ne sont pas connues et sont déterminées à la volée, tandis qu’ici la prédiction de l’IA est une classe parmi un ensemble de classe définies (et pour lesquelles l’IA a des exemples, idéalement en même quantité).

Un outil simple et rapide pour tester des modèles : LazyPredict
LazyPredict est une librairie Python développée par Shankar Rao Pandala (sur Github) afin d’aider à entraîner rapidement de nombreux modèles de machine learning quasiment sans aucun code, pour ensuite mieux cibler les modèles à utiliser !
Est-ce qu’un tel outil est vraiment nécessaire en machine learning ?
Je vous propose de partir d’un cas concret pour bien visualiser l’utilité des outils exploratoires en Machine Learning :
L’IA School est une école privée présente sur Paris et Lyon délivrant des formations certifiées (avec crédits ECTS et semestre à l’étranger) de niveau Bachelor et Mastère, en plus de la version e-learning de son offre. Ses élèves y étudient évidemment l’Intelligence Artificielle (Machine Learning / Deep Learning) mais acquièrent aussi d’autres compétences plus transverses tels le management, le big data (bases NoSQL, …), la data analyse, le scrapping… qu’ils démarrent l’année scolaire en septembre ou en janvier.
Comme dans n’importe quelle formation, le temps alloué aux Travaux Pratiques ou à d’éventuels projets liés aux partenaires de l’IA School (Publicis Groupe, L’Oréal, Fnac Darty, Louis Vuitton…) est contrôlé, et pouvoir implémenter un algorithme d’Intelligence Artificielle « qui fonctionne du premier coup » est crucial, à la fois pour comprendre rapidement comment fonctionne l’IA mais aussi pour pouvoir expérimenter des alternatives à cet algorithmes.
Grâce à des TP bien préparés par l’enseignant et/ou à un outil comme LazyPredict, les étudiants savent immédiatement dans quelle direction partir pour aborder le problème ! Bien entendu, en Industrie cet enjeu de pouvoir rapidement tester et valider des pistes de modèles répondant à un problème donné est déterminant.
Comment installer LazyPredict
Pour pouvoir utiliser la librairie LazyPredict nous allons avoir besoin d’installer plusieurs autres modules car ils ne sont pas téléchargés automatiquement.
Tout d’abord il faut télécharger et installer Python 3, pour ma part dans sa version 3.8.7.
Attention : ne pas oublier, à la fin de l’installation de Python, de cliquer sur le bouton pour désactiver la limite de 260 caractères de Windows (sinon il y aura des problèmes avec sklearn par la suite).
Une fois que c’est fait, ouvrir une invite de commande ou une console PowerShell puis lancer les commandes suivantes qui permettent d’installer les modules utiles pour LazyPredict :
pip install lazypredict
pip install scikit-learn==0.23.1
pip install tqdm
pip install xgboost
pip install lightgbm
pip install xgboost
pip install pandas
pip install pytestBug possible #1 : votre commande « pip » utilise python 2 au lieu de python 3 –> remplacer « pip » par « pip3 » dans les commandes ci-dessus
Dans votre fichier Python ou dans votre Jupyter Notebook, exécutez le code suivant :
from lazypredict.Supervised import LazyClassifier,LazyRegressorBug possible #2 : ModuleNotFoundError: No module named ‘sklearn.utils.testing’ –> la version installée de scikit-learn est « trop à jour » par rapport à ce que lazypredict accepte : la méthode « all_estimators » a été déplacée dans la nouvelle version de sklearn !
Il faut donc désinstaller la version actuelle de scikit-learn et réinstaller la version 0.23.1 (ou plus récente en fonction des mises à jour de LazyPredict)
pip uninstall scikit-learn
pip install scikit-learn==0.23.1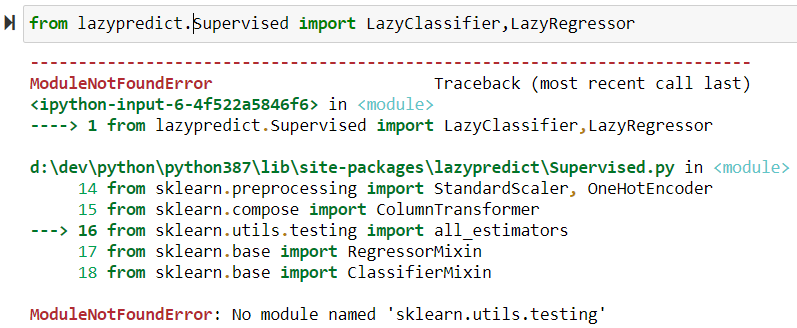
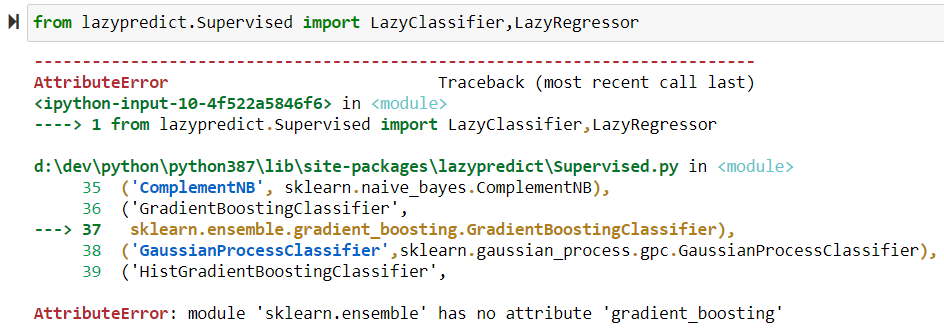
Bug possible #3 : AttributeError: module ‘sklearn.ensemble’ has no attribute ‘gradient_boosting’
OU AttributeError: module ‘sklearn.gaussian_process’ has no attribute ‘gpc’
OU d’autres erreurs de ce type
–> idem que le bug #2
La régression : une histoire de logement et d’immobilier
Afin de mettre à l’épreuve la puissance de LazyPredict, nous allons considérer deux problèmes distincts liés à l’immobilier
- Prédire le prix d’une maison à Boston (aux USA) à partir de 13 caractéristiques connues (informations sur le quartier ou la ville : crime, commerces, routes, proportion d’enseignants, de logements anciens, etc…) sur 506 logements, cf l’article d’analyse exploratoire d’Animesh Agarwal
- Prédire le prix d’une maison en Californie à l’aide de 9 indicateurs directement liés au logement (coordonnées géographiques, nombre de chambres…) grâce à 20 640 exemples !
Commençons par importer ces deux datasets grâce à sklearn qui les a dans son module « datasets » (où vous trouverez d’autres exemples typiques de machine learning) puis chargeons-les dans nos variables ds_boston et ds_california
from sklearn.datasets import load_boston
from sklearn.datasets import fetch_california_housing
ds_boston = load_boston()
ds_california = fetch_california_housing()Nos deux datasets sont des dictionnaires avec :
- un attribut « data » qui contient la liste des données connues sur les logements (mais pas le prix !)
- un attribut « target » qui contient la liste des prix de chaque logement
Maintenant que les données sont chargées, nous allons devoir diviser nos exemples en deux groupes :
- les données d’entraînement = des exemples de logements avec le prix associé pour que les IA apprennent la relation entre ces deux informations
- les données de test pour comparer le prix prédit par l’IA avec le vrai prix (dont elle n’aura jamais eu connaissance)
- généralement, elles représentent de 10% à 20% des données totales, dont elles sont extraites
La méthode « train_test_split » permet justement de diviser nos deux listes data et target chacune en deux groupes « train » et « test » en spécifiant que l’on veut 10% de données de test par rapport aux données d’entraînement (via « test_size=0.1 »).
A noter que train_test_split divise aléatoirement les données, donc afin d’obtenir les mêmes résultats nous allons fixé cet aléatoire grâce à « random_state=1 ») :
from sklearn.model_selection import train_test_split
Xb_train, Xb_test, yb_train, yb_test = train_test_split(ds_boston["data"],ds_boston["target"],test_size=0.1,random_state=1)
Xc_train, Xc_test, yc_train, yc_test = train_test_split(ds_california["data"],ds_california["target"],test_size=0.1,random_state=1)Ainsi, Xb_train désigne des exemples de caractéristiques de logement à Boston (les prix correspondants sont dans yb_train), tandis que Xc_test contient des exemples de caractéristiques de logement en Californie. yc_train sera fournit aux modèles d’intelligences artificielles pour comprendre la relation entre caractéristique du logement et prix, tandis que yc_test sera gardé secret et on le comparera aux prédictions des IA !
Il ne nous reste plus qu’à lancer LazyPredict dans sa version « Regressor » pour qu’il fournisse toutes ces données aux différents modèles d’IA qu’il évalue pour obtenir les résultats de l’entraînement de chaque algorithme de machine learning, par exemple Random Forest, ElasticNet, Arbre de Décision, Gradient Boosting, etc…
NB : l’entraînement sur les données de Californie est plus long (quelques minutes) car il y a beaucoup d’exemples à traiter.
reg = LazyRegressor()
models_boston,predictions_boston = reg.fit(Xb_train, Xb_test, yb_train, yb_test)
models_california,predictions_california = reg.fit(Xc_train, Xc_test, yc_train, yc_test)
print(models_boston)
print(models_california)Ce qui donne les résultats suivants
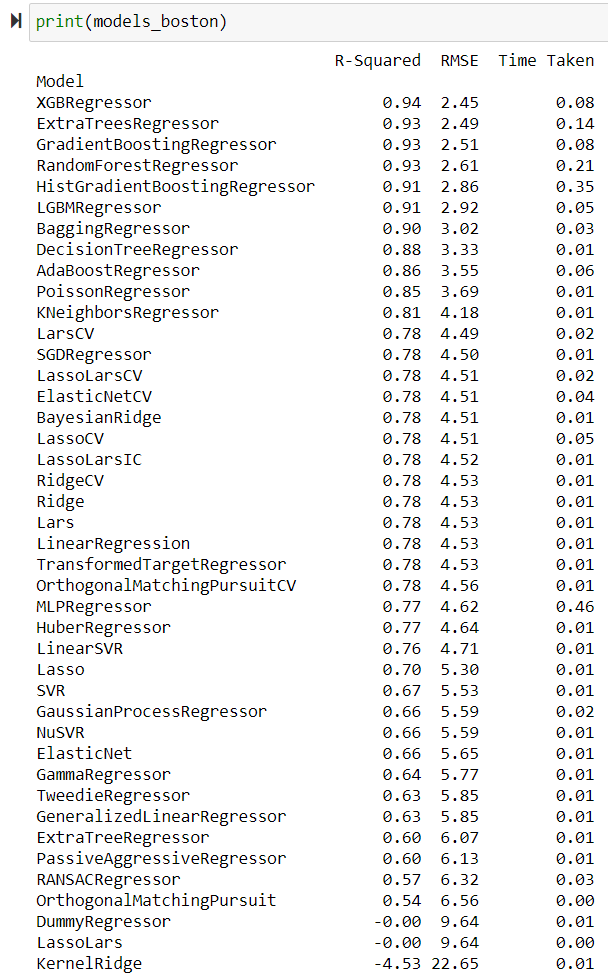

En quelques secondes on peut donc voir que pour nos deux problèmes, l’utilisations de l’algorithme XGBoost (noté XGBRegressor ici) a donné les meilleurs résultats avec 94% de prédictions correctes pour Boston et 84% pour la Californie !
Bonus : dans la variable predictions_boston vous retrouverez les prédictions de chaque modèle pour les différentes données
La classification : un soucis
Dans ce paragraphe nous allons aller plus vite que pour la régression, car toutes les explications sont identiques. N’hésitez pas à consulter le paragraphe précédent si besoin !
Intéressons-nous aux deux problèmes suivants :
- Prédire la gravité (bénin ou malicieux) du cancer du sein grâce aux 569 exemples issus d’une étude de l’Université du Wisconsin portant sur 32 paramètres liés aux noyaux des cellules prélevées (taille, texture, etc…)
- Déterminer l’espèce d’une fleur d’Iris grâce aux 4 attributs (longueur/largeur) de 150 fleurs d’Iris
Remarque : en « classification » il est important de garder en tête la répartition d’exemples dans chaque classe : s’il y a un déséquilibre (par exemple 90% des exemples concernent un cancer bénin, alors l’IA aura fortement tendance à prédire systématiquement un cancer bénin, puisqu’elle aura juste dans 90% des cas…). L’objectif est donc d’avoir le même nombre d’exemples dans chaque classe, ce qui est le cas ici.
Pour aller plus loin : certains algorithmes de machine learning sont très performants dans le cas de données déséquilibrées, par exemple pour de la détection de fraude bancaire !
Passons à présent au code :
On charge nos datasets
from sklearn.datasets import load_breast_cancer
from sklearn.datasets import load_iris
ds_breast_cancer = load_breast_cancer()
ds_iris = load_iris()
from sklearn.model_selection import train_test_split
Xbc_train, Xbc_test, ybc_train, ybc_test = train_test_split(ds_breast_cancer["data"],ds_breast_cancer["target"],test_size=0.1,random_state=1)
Xi_train, Xi_test, yi_train, yi_test = train_test_split(ds_iris["data"],ds_iris["target"],test_size=0.1,random_state=1)Puis on demande à LazyPredict d’entraîner les IA de classification
reg = LazyClassifier()
models_breast_cancer,predictions_breast_cancer = reg.fit(Xbc_train, Xbc_test, ybc_train, ybc_test)
models_iris,predictions_iris = reg.fit(Xi_train, Xi_test, yi_train, yi_test)
print(models_breast_cancer)
print(models_iris)On obtient les résultats suivants :
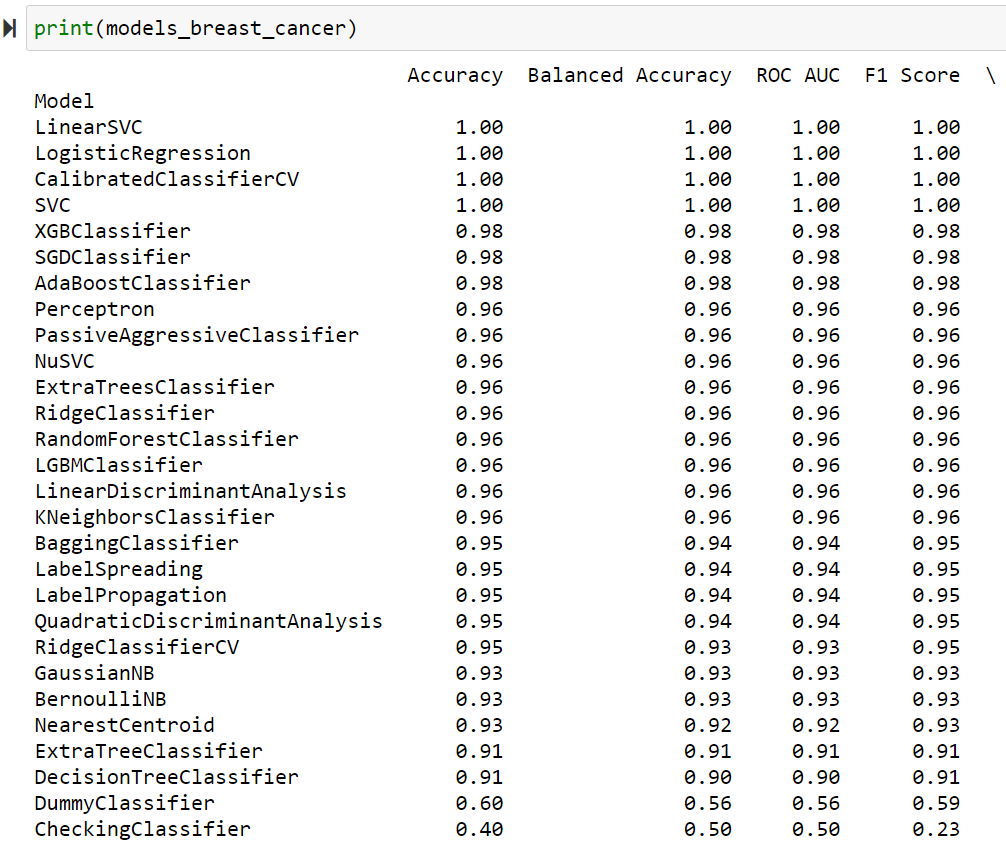
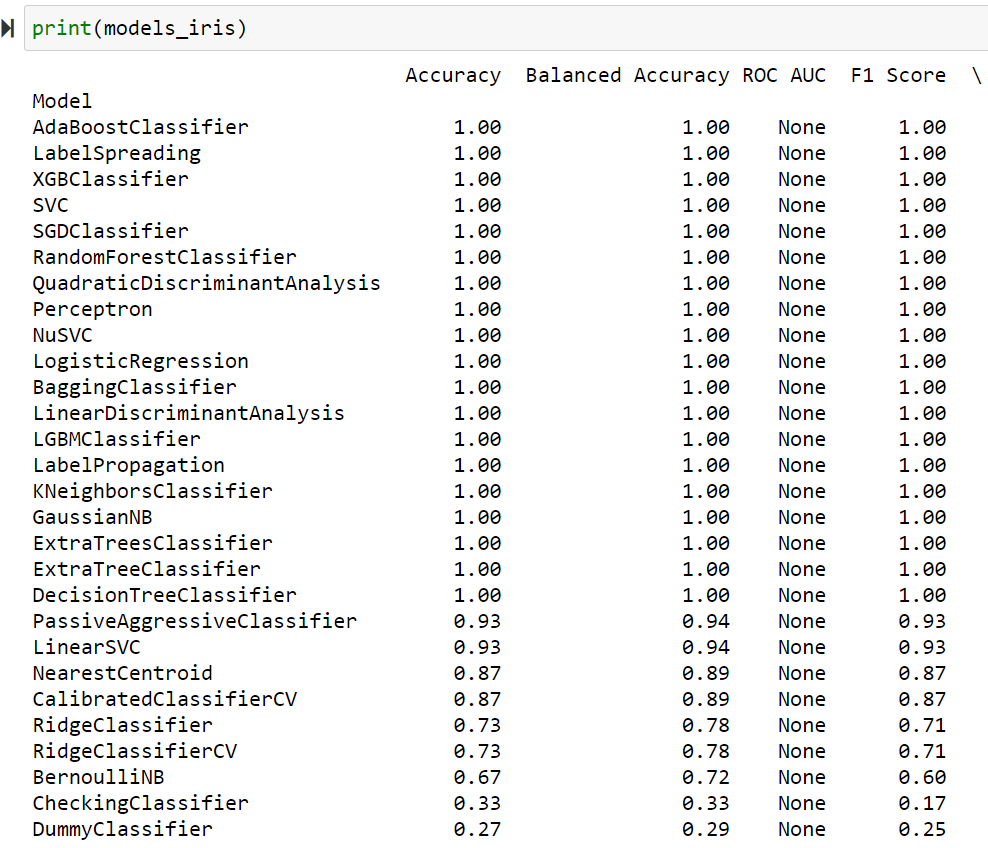
Conclusion : un bon outil de point de départ
Quand on débute en Machine Learning ou qu’on s’attaque à un projet étudiant, il est difficile de savoir quoi utiliser ou par où commencer. Que ce soit par manque d’expérience, ou par « flou » lié à toutes les connaissances que l’on est en train de consolider, LazyPredict est un bon outil pour avoir une idée globale :
- des algorithmes que l’on peut utiliser et sur lesquels il est intéressant de travailler davantage (en procédant à une phase de « fine-tuning » des « hyper-paramètres »)
- des résultats que l’on a, au minimum !
J’espère que cet article vous aura aidé, que vous suiviez actuellement le cursus Intelligence Artificielle à l’IA School ou que vous ayez simplement besoin d’inspiration pour démarrer un nouveau projet !
Crédit de l’image de couverture : Lambert Rosique – Tous droits réservés



{kind=link}
{kind=link}
{kind=link}