
Du fait de la complexité des traitements en data science, que ce soit pour l’agrégation ou la préparation des données, le choix et l’entraînement des algorithmes, les comptes-rendus, les analyses, etc…, de très nombreuses librairies ont vu le jour, chacune ayant son objectif propre qu’elle réalise du mieux possible.
Néanmoins, s’y retrouver dans cette jungle de plusieurs milliers de possibilités n’est vraiment pas évident. Dans cet article, on va vous présenter une vingtaine de librairies exceptionnellement efficaces et populaires, que vous vous devez de connaître en 2018 (et d’utiliser !). Ensuite, on vous donnera le lien et quelques précisions sur le curateur le plus populaire de Github pour la Data Science, qui recense plus de 1000 librairies de data science en Python, Java, C++, C#… et autres langages !
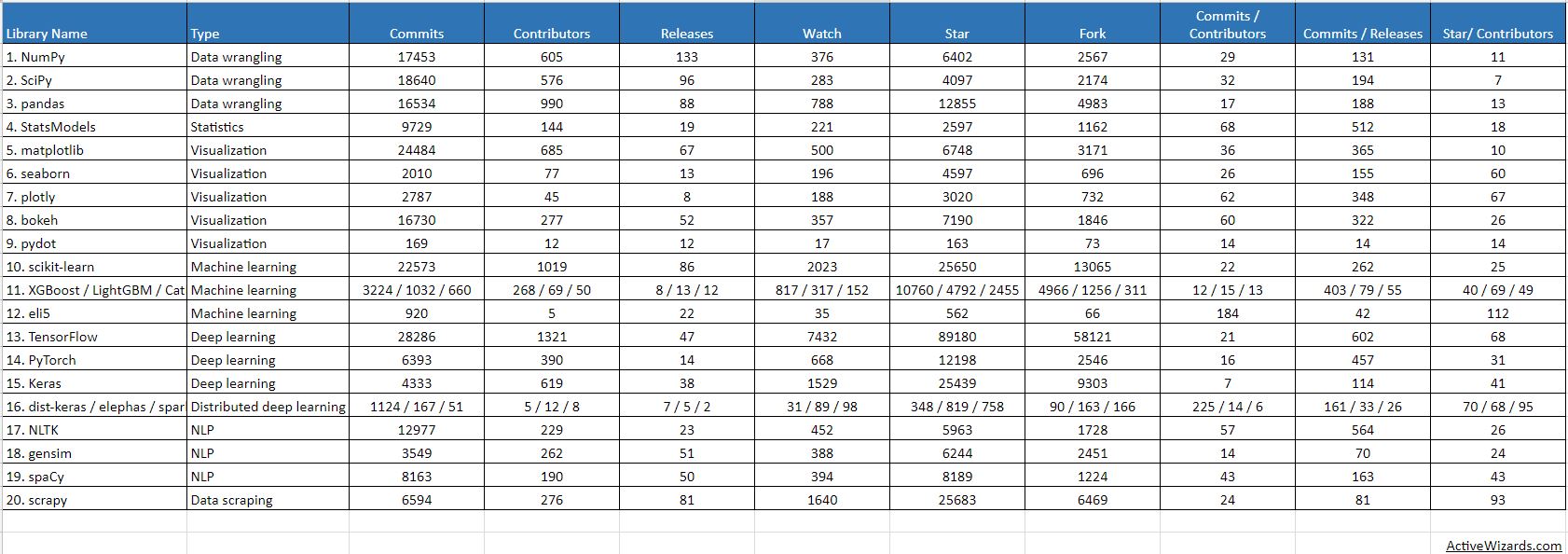
Remarque : cet article se base sur le tableau comparatif d’ActiveWizards et de github pour les stats sur les librairies.
Boîte à outils
Numpy (17 484 commits, 606 contributeurs)
C’est la librairie la plus fondamentale, celle qui est importée dans la quasi-totalité des projets de data science, machine learning ou deep learning. Sa principale utilité est les opérations qu’elle propose sur les vecteurs et les matrices, qui permettent de traiter facilement avec d’autres librairies et de donner forme aux données.
In [1]: import numpy as np
In [2]: a = np.arange(15).reshape(3, 5)
In [3]: a
Out[3]: array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
In [4]: a.shape
Out[4]: (3, 5)
In [5]: a.ndim
Out[5]: 2
In [6]: a.dtype.name
Out[6]: 'int64'
In [7]: a.itemsize
Out[7]: 8
In [8]: a.size
Out[8]: 15
In [9]: type(a)
Out[9]: <type 'numpy.ndarray'>
In [10]: b = np.array([6, 7, 8])
In [11]: b
Out[11]: array([6, 7, 8])
In [12]: type(b)
Out[12]: <type 'numpy.ndarray'>
SciPy (18 671 commits, 578 contributeurs)
SciPy est une version plus évoluée de Numpy, avec davantage de fonctionnalités et de complexité. Par exemple, vous disposez d’outils d’algèbre linéaire, de statistiques, d’optimisation, le tout divisé en modules. A utiliser dans les projets plus poussés.
In [1]: from scipy import special, optimize
In [2]: f = lambda x: -special.jv(3, x)
In [3]: sol = optimize.minimize(f, 1.0)
In [4]: x = linspace(0, 10, 5000)
In [5]: x
Out[5]:array([ 0.00000000e+00, 2.00040008e-03, 4.00080016e-03, ...,
9.99599920e+00, 9.99799960e+00, 1.00000000e+01])
Données
Scrapy (6 599 commits, 278 contributeurs)
Cette librairie sert essentiellement à crawler le web pour récupérer des images ou des données directement sur les sites, et constituer ainsi une base d’apprentissage pour les algorithmes.
Parcourir le web et en extraire des informations n’est pas toujours évident, aussi l’utilisation de Scrapy permet de gagner beaucoup de temps.
import scrapy
class AuthorSpider(scrapy.Spider):
name = 'author'
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
# follow links to author pages
for href in response.css('.author + a::attr(href)'):
yield response.follow(href, self.parse_author)
# follow pagination links
for href in response.css('li.next a::attr(href)'):
yield response.follow(href, self.parse)
def parse_author(self, response):
def extract_with_css(query):
return response.css(query).extract_first().strip()
yield {
'name': extract_with_css('h3.author-title::text'),
'birthdate': extract_with_css('.author-born-date::text'),
'bio': extract_with_css('.author-description::text'),
}
Statsmodel (9 731 commits, 145 contributeurs)
Sans surprise, Statsmodel vous permet de réaliser plein de tests sur les données afin d’en extraire des informations cruciales pour l’entraînement de vos algorithmes. Par exemple, vous pourrez vous apercevoir qu’il y a une relation « quadratique » entre vos données, suggérant qu’il faudrait ajouter en entrée de votre réseau de neurones la variable \(x^2\).
Pandas (16 562 commits, 994 contributeurs)
Manipulation, agrégation et visualisation des données n’ont jamais été aussi facile que depuis que j’utilise Pandas. La fonctionnalité la plus pratique est évidemment celle qui permet de récupérer un fichier csv et d’agir sur les données avant de le passer à l’algorithme de machine learning à entraîner !
import pandas as pd
pd.set_option('display.mpl_style', 'default')
df = pd.read_csv('../data/bikes.csv', sep=';', encoding='latin1', parse_dates=['Date'], dayfirst=True, index_col='Date')
df['Berri 1'].plot()
Visualisation
Matplotlib (24 575 commits, 687 contributeurs)
Le meilleur moyen de tracer des graphiques simples ou complexes, pour rendre compte de vos données (que ce soit celles d’entrées, de sorties, de statistiques d’entraînement, etc…).
Que ce soient des diagrammes, des camemberts, des spectrogrammes, des graphiques 2D ou 3D, rien n’échappe à MatPlotLib.
Bokeh (16 737 commits, 278 contributeurs)
LE concurrent de Matplotlib qu’on vient de voir, il se démarque par sa capacité à rendre ses visualisations interactives : vous pouvez passer la souris dessus et voir des zones du graphique se mettre en surbrillance, se déplacer, apparaître, le tout grâce au moteur Javascript D3 (d3.js). Voici un exemple qui met à la fois en avant l’aspect « modification des données/du rendu à la volée » et affichage d’informations complémentaires sous la souris.
pip install bokeh
Seaborn (2 010 commits, 77 contributeurs)
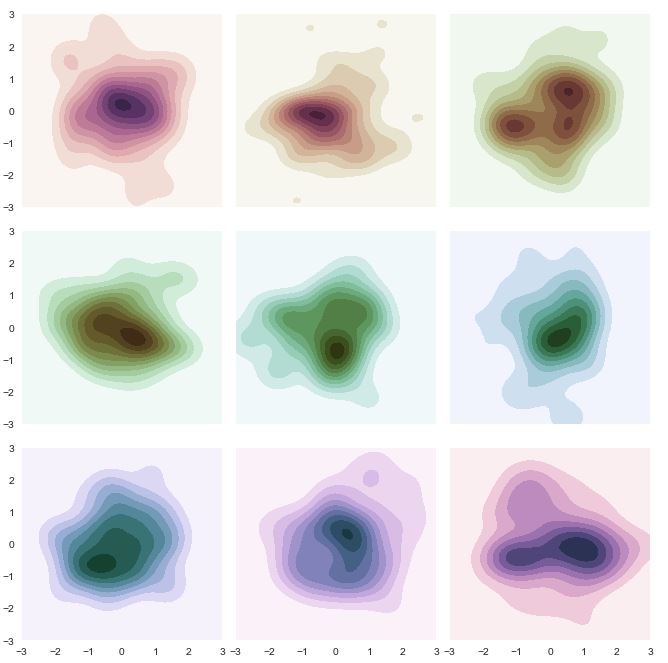
Extension de Matplotlib dédiée aux statistiques, Seaborn propose de nombreuses cartes de chaleur. La librairie est récente et « peu » démocratisée mais devrait rapidement gagner en visibilité !
Dans l’exemple ci-contre, on voit l’une de ces cartes générée assez facilement (voir le code tout en bas). On notera au passage que Matplotlib est utilisé ici pour ordonner les graphes, mais c’est bien Seaborn qui les génère.
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="dark")
rs = np.random.RandomState(50)
# Set up the matplotlib figure
f, axes = plt.subplots(3, 3, figsize=(9, 9), sharex=True, sharey=True)
# Rotate the starting point around the cubehelix hue circle
for ax, s in zip(axes.flat, np.linspace(0, 3, 10)):
# Create a cubehelix colormap to use with kdeplot
cmap = sns.cubehelix_palette(start=s, light=1, as_cmap=True)
# Generate and plot a random bivariate dataset
x, y = rs.randn(2, 50)
sns.kdeplot(x, y, cmap=cmap, shade=True, cut=5, ax=ax)
ax.set(xlim=(-3, 3), ylim=(-3, 3))
f.tight_layout()
Plotly (2 828 commits, 45 contributeurs)
Je ne l’ai jamais utilisé, mais il était listé par ActiveWizards dans leur comparatif des outils de visualization donc on le mentionne ici. Sa particularité est d’être basé sur le web, avec un système d’API et de clés permettant de l’inclure dans vos sites (plusieurs langages de programmation sont disponibles). Ainsi, les graphiques ne sont pas calculés par votre serveur ni les ordinateurs des clients, mais directement par Plotly qui vous envoie ensuite l’image. On retrouve ce type d’utilisation avec le Latex par exemple qui n’est pas forcément généré en interne.
pip install plotly
Machine Learning
SciKit-Learn (22 595 commits, 1 022 contributeurs)
La librairie absolue contenant la très grande majorité des algorithmes de Machine Learning, ainsi que de très nombreux outils dont de la manipulation de données (images ou texte). Par exemple, vous pouvez remplacer toutes les cellules absentes d’un fichier csv par la valeur moyenne de la colonne, supprimer la ligne, y mettre le maximum…
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
# Taking care of missing data
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0)
imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
# Encoding categorical data
# Encoding the Independent Variable
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
# Encoding the Dependent Variable
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
XGBoost / LightGBM / CatBoost (3 228 commits, 268 contributeurs)
Une librairie disponible dans beaucoup de langages qui permet de faire du « gradient boosting« , un algorithme de Machine Learning très utilisé pour son efficacité.
git clone --recursive https://github.com/dmlc/xgboost git submodule init git submodule update
Eli5 (920 commits, 5 contributeurs)
A la fois sa force et sa faiblesse, seulement 5 personnes travaillent à l’amélioration d’Eli5. Néanmoins, Eli5 a pour intérêt non pas les algorithmes qu’elle propose mais l’aspect « débug » et « interprétation » des prédictions des algorithmes de Machine Learning.
A l’aide (en partie) de reverse engineering, vous pourrez comprendre ce qui se cache derrière vos résultats, car ce qui intéresse le plus un client, ce n’est pas le résultat mais le comment/pourquoi (on le voit notamment avec les compétitions Kaggle, dont les algorithmes surpuissants sont inutilisables dans la pratique mais apprennent beaucoup de choses sur les jeux de données).
Attention : Eli5 ne fonctionne qu’avec SciKit Learn et XGBoost présentés ici (ce ne sont pas les seuls sinon).
Deep Learning
Keras (4 553 commits, 624 contributeurs)
La librairie phare du deep learning pour sa simplicité, elle n’est pas la plus utilisée ni la plus efficace mais remplit bien son rôle. Beaucoup d’algorithmes de base sont implémentés, dont les réseaux de neurones artificiels, ce qui en fait un bon point d’entrée dans les tutoriels et évite d’avoir à expliquer les notions de tenseurs à des « débutants ».
# Réseau de neurones artificiels
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGD
import numpy as np
X = np.array([[0,0],[0,1],[1,0],[1,1]])
y = np.array([[0],[1],[1],[0]])
model = Sequential()
model.add(Dense(2, input_dim=2, activation='tanh'))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
model.fit(X, y, batch_size=1, nb_epoch=500)
print(model.predict_proba(X))
for layer in model.layers:
weights = layer.get_weights()
print(weights)
model.save_weights("model.h5")
TensorFlow (28 814 commits, 1 338 contributeurs)
Développée par Google, TensorFlow est une librairie open source (comme les autres présentées ici) dédiée au deep learning, même si elle peut aussi faire du machine learning. Tous les derniers algorithmes hyper novateurs sont implémentés (dans la partie research des modèles), ce qui rend son utilisation incontournable. Notez au passage que d’autres « versions » de cette librairie existent, dont notamment tensorflow mobile et tensorflow slim qui boostent les performances des algorithmes pour pouvoir les embarquer dans des téléphones ou des Raspberry Pi.
# Exemple de couche de convolution
import tensorflow as tf
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
PyTorch (6 445 commits, 398 contributeurs)
 Petit dernier dans le monde du deep learning, PyTorch présente l’avantage d’avoir été inventé par NVIDIA ! A l’image d’IBM qui pouvait adapter ses algorithmes à ses machines, PyTorch est parfaitement optimisé pour utiliser la puissance des cartes graphiques dans les calculs difficiles et longs.
Petit dernier dans le monde du deep learning, PyTorch présente l’avantage d’avoir été inventé par NVIDIA ! A l’image d’IBM qui pouvait adapter ses algorithmes à ses machines, PyTorch est parfaitement optimisé pour utiliser la puissance des cartes graphiques dans les calculs difficiles et longs.
NVIDIA gagne d’ailleurs des parts de marché, en proposant régulièrement de nouveaux produits toujours plus poussés, que ce soient des ordinateurs, des clés usb, ou des puces dédiées à l’intelligence artificielle.
Theano (27 933 commits, 328 contributeurs)
A la base, Theano était développé par des chercheurs de l’Université de Montréal, au Canada. Mais comme bien souvent en intelligence artificielle, leurs recherches ont été reprises, améliorées et surtout adaptées au monde de l’entreprise.
La librairie remplit le même type de fonctionnalité que Numpy (vecteurs et matrices) en optimisant au maximum ses performances. On aurait pu la placer dans les boîtes à outils, mais Theano est vraiment dédiée au deep learning car elle propose, en plus, des tenseurs (comme TensorFlow !), ou encore des calculs de convolutions.
#Exemple de convolution en Theano :
import theano
output = theano.tensor.nnet.conv2d(
input, filters, input_shape=(b, c2, i1, i2), filter_shape=(c1, c2, k1, k2),
border_mode=(0, 0), subsample=(1, 1))
Reconnaissance d’image
OpenCV (23 386 commits, 855 contributeurs)
On en a beaucoup parlé sur ce site, notamment avec nos focus sur les MobileNet, qui permettent de détecter et de classifier des éléments d’images/vidéos. OpenCV est la librairie incontournable pour tout ce qui est reconnaissance d’images (même si TensorFlow a également de bons outils)
Analyse du langage
NLTK (12 979 commits, 228 contributeurs)
Natural Language ToolKit est la librairie de référence pour tout traitement en rapport avec du langage naturel. Que ce soit par écrit ou à l’oral, NLTK a tous les outils nécessaires à l’analyse des données, à leur traitement et en termes d’algorithmes d’apprentissage pour obtenir les meilleures prédictions possibles. Linguistique, sciences cognitives pour l’intelligence artificielle, analyse sémantique, rien n’échappe à l’expertise de la librairie, qui peut tagger, classifier, tokenifier, faire des corpus, travailler caractère par caractère, mot par mot, contexte par contexte…
Attention toutefois, car NLTK est surtout dédiée à la recherche et aux POC !
# Synonymes avec NLTK (dictionnaire accessible dans la librairie !)
from nltk.corpus import wordnet
synonyms = []
for syn in wordnet.synsets('Computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)
Gensim (3 558 commits, 265 contributeurs)
Gensim est une librairie un peu particulière, puisqu’elle se dédie à la manipulation de grands corpus de textes en mettant à profit ses capacité de streaming des données. Il faut donc l’utiliser lorsque vous travaillez par batch et par traitement de données via la RAM, car c’est là que la librairie brille le plus.
# Source : https://radimrehurek.com/gensim/tutorial.html
from gensim import corpora, models, similarities
corpus = [[(0, 1.0), (1, 1.0), (2, 1.0)],
[(2, 1.0), (3, 1.0), (4, 1.0), (5, 1.0), (6, 1.0), (8, 1.0)],
[(1, 1.0), (3, 1.0), (4, 1.0), (7, 1.0)],
[(0, 1.0), (4, 2.0), (7, 1.0)],
[(3, 1.0), (5, 1.0), (6, 1.0)],
[(9, 1.0)],
[(9, 1.0), (10, 1.0)],
[(9, 1.0), (10, 1.0), (11, 1.0)],
[(8, 1.0), (10, 1.0), (11, 1.0)]]
tfidf = models.TfidfModel(corpus)
vec = [(0, 1), (4, 1)]
print(tfidf[vec])
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=12)
sims = index[tfidf[vec]]
print(list(enumerate(sims)))
spaCy (8 238 commits, 191 contributeurs)
spaCy est la librairie d’analyse du langage la plus rapide au monde. Elle est le pendant « entreprise » de NLTK, avec ses nombreux langages supportés, toutes ses options disponibles et surtout sa rapidité d’exécution (traitement, apprentissage et restitution) !
# Source : https://spacy.io/usage/examples
from spacy.matcher import PhraseMatcher
import spacy
def get_matches(tokenizer, phrases, texts, max_length=6):
matcher = PhraseMatcher(tokenizer.vocab, max_length=max_length)
matcher.add('Phrase', None, *phrases)
for text in texts:
doc = tokenizer(text)
for w in doc:
_ = doc.vocab[w.text]
matches = matcher(doc)
for ent_id, start, end in matches:
yield (ent_id, doc[start:end].text)
Seq2Seq (880 commits, 16 contributeurs)
Projet annexe de TensorFlow (et donc de Google), Seq2Seq est une librairie assez récente dont le but est d’encoder et de décoder. L’architecture de son algorithme principal repose sur des réseaux de neurones récurrents, de type LSTM. Ce n’est donc pas une librairie générique qui pourra faire beaucoup de choses avec vos données, mais ça pourrait être LA solution à un problème donné de NLP.
Les 1000 librairies de data science

Nous y voici, on connait désormais les principales librairies en fonction de leur utilité. Si ici on s’est beaucoup concentré sur le python (même si elles existent pour la plupart dans d’autres langages), le github regroupant toutes les librairies et leur utilité traite de tous les langages ! APL, C, C++, Lisp, Clojure, Crystal, Elixir, Erlang, Go, Haskell, Java, Javascript, Julia, Lua, Matlab, .NET, Objective C, OCaml, Perl, PHP, Python, Ruby, Rust, R, SAS, Scala, Swift et TensorFlow sont ainsi alimentés.
Voici le lien vers le github de Joseph Misiti et son « awesome machine learning« .
Conclusion
Si on compare à l’article de Medium, en mai 2017, on voit que la plupart des libraires ont beaucoup évoluées en l’espace de 10 mois, toutes pour le meilleur. Cela montre bien qu’il y a une véritable demande autour de la data science, et qu’elle est tellement large qu’il faut des dizaines de librairies distinctes pour ne pas s’égarer en traitements « auxiliaires » et faire vraiment ce qui doit être fait.
La liste des mille librairies de data science est régulièrement mise à jour, ainsi que l’Excel de ActiveWizards, donc n’hésitez pas à les consulter occasionnellement. Quant à nous, on refera le point sur les librairies dans quelques mois !
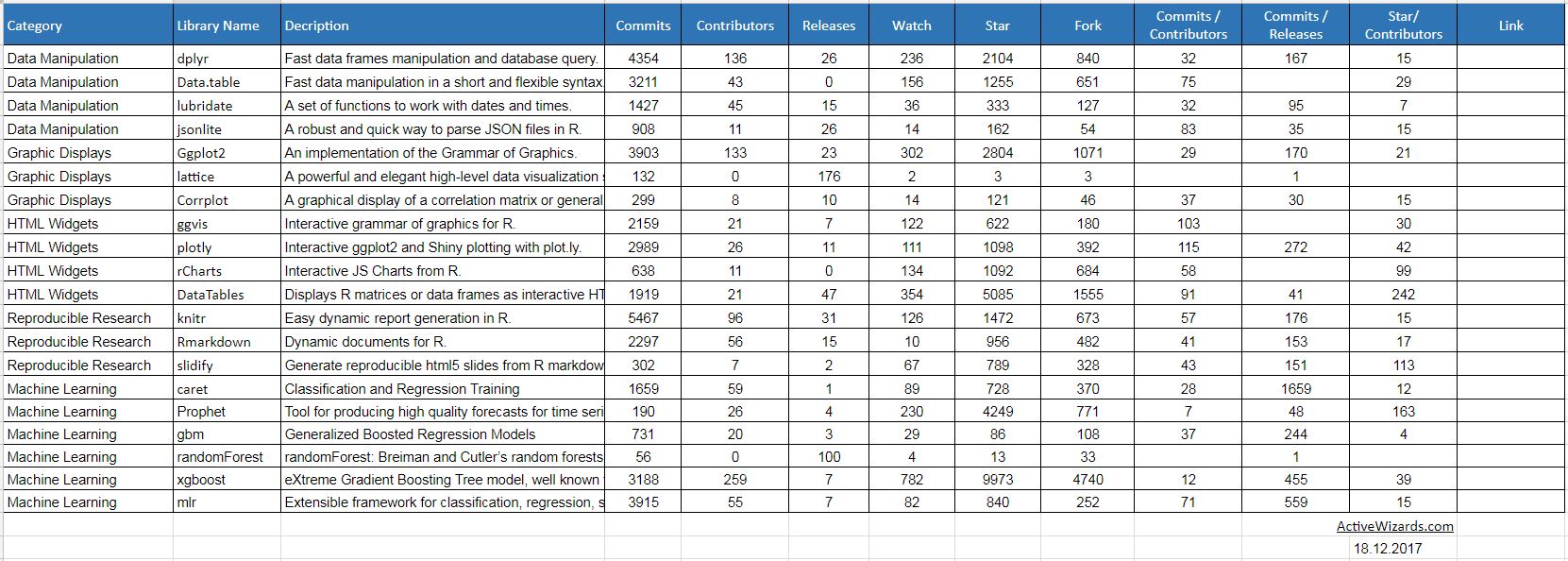
Pour aller plus loin : R
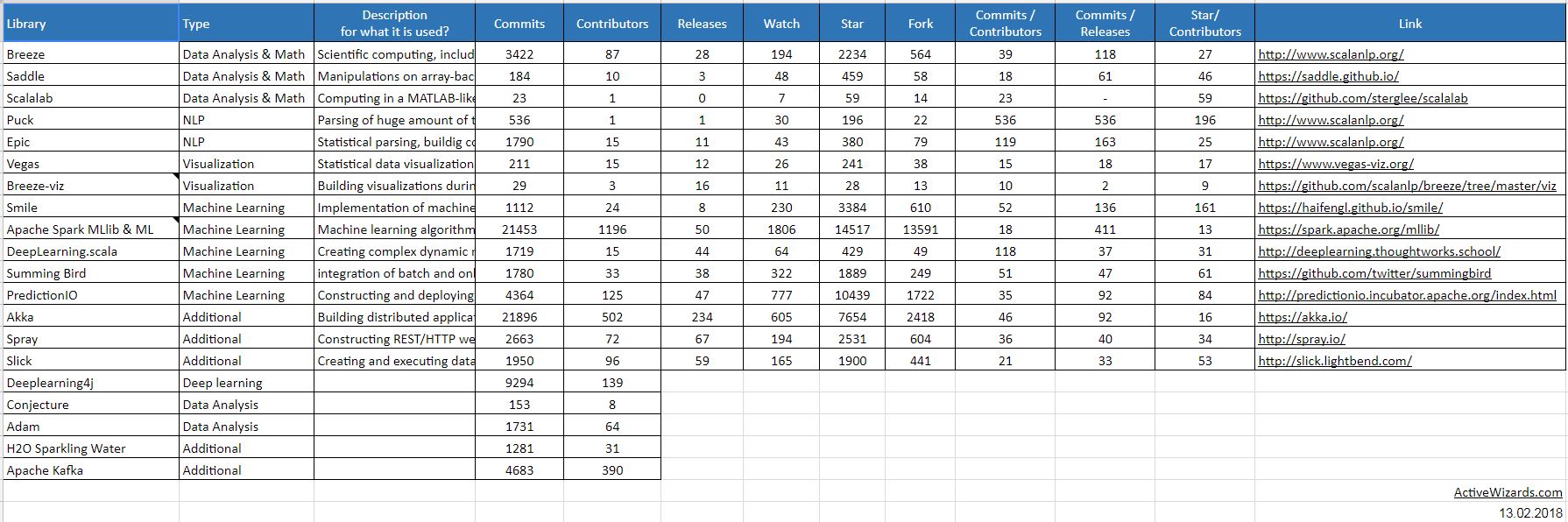
Pour aller plus loin : Scala
Crédit de l’image de couverture : PhotoMIX-Company – Pixabay License



){kind=link}