
Si la détection de fraude est un enjeu majeur souvent difficile à aborder en raison de la disparité des données (peu de cas « positifs »), la visualisation finale des attaques est tout aussi importante.
En effet, les pertes d’argent liées à de la fraude bancaire sont estimées à 22.8 milliards de dollars en 2017 et atteindront 33 milliards en 2021 !
Dans cet article nous allons donc découvrir un modèle de Machine Learning surpuissant pour les jeux de données déséquilibrés, LightGBM avant de voir ensemble comment placer les fraudes sur une carte mise à jour en temps réel.
PS : Le code donné ici est complet et pourra facilement être adapté à tout autre besoin, en particulier pour la visualisation temps-réel sur une carte.
Lien vers le Github de ce tutoriel
I. L’algorithme qui a fait ses preuves : LightGBM
Le problème
Pour comprendre le problème, il faut comprendre ce que fait un algorithme supervisé d’IA.
Tout d’abord, lorsqu’on entraîne l’IA, les données sont séparées en deux groupes : les données d’apprentissage et les données de test. Ces deux groupes sont issus des données d’origine (ici, plein de transactions bancaires) que l’on a séparées aléatoirement.
Lors de la phase d’apprentissage, l’IA va regarder les données du premier groupe et essayer de dégager une tendance car son objectif, à terme, est d’avoir le plus de prédictions correctes sur les données de test.
Dans le cas de la fraude bancaire, on a 284 807 transactions bancaires dont seulement 492 sont frauduleuses, soit 0.172%. Imaginons alors l’IA suivante :
- peu importe la donnée que l’on me donne, je dis que ce n’est pas une transaction frauduleuse
Quel serait le taux de précision de cette IA ? 99.8%. Incroyable n’est-ce pas ?
Le souci, c’est que cette IA… ne nous sert à rien, car nous on veut pouvoir trouver les transactions frauduleuses !
L’avantage de LightGBM comparé à beaucoup d’autres algorithmes, c’est qu’il va tout faire pour avoir un bon score de prédiction sur les données non frauduleuses ET sur les données frauduleuses, à l’inverse de beaucoup d’autres algorithmes qui auront tendance à faire ce que j’ai expliqué ci-dessus…
C’est pour cette raison que LightGBM est beaucoup utilisé sur Kaggle et remporte de nombreuses compétitions.
A noter que, si on veut utiliser par exemple un réseau de neurones, l’astuce est de ne garder que 492 transactions non-frauduleuses pour équilibrer les deux classes et qu’une IA qui répondrait toujours « non-frauduleux » n’aurait que 50% de précision (le minimum). On parle de « down-sampling ».
LightGBM l’algorithme de Machine Learning préféré de Kaggle
LightGBM est un algorithme de machine learning basé sur le Gradient Boosting Machine (GBM) que nous allons expliquer dans un instant. Il est rapide, distribué, avec de grandes performances et repose sur des arbres de décisions. Son concurrent principal est le célèbre XGBoost sur lequel nous ne reviendrons pas ici…
Arbre de décision
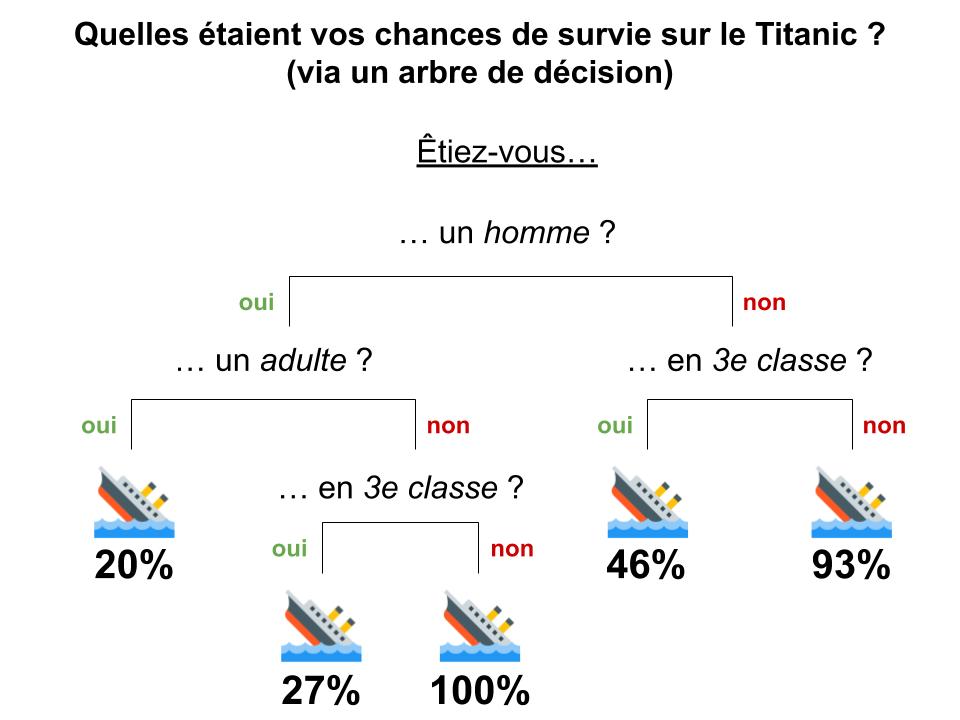
Un arbre de décision est tout simplement un algorithme que l’on va « dérouler » et où l’on trouvera des intersections : une question y sera posée, qui nous orientera vers l’une ou l’autre des branches en fonction de la réponse !
Le concept est simple et intuitif, car on a l’habitude de raisonner de cette manière.
Par exemple, dans l’arbre à gauche, on peut donner la probabilité de survivre à l’accident du Titanic en fonction de 2 ou 3 questions simples : un homme adulte en 3ème classe n’avait que 27% de chances de survie. Le point de départ s’appelle la racine (root), et on parle de feuilles (leaf) pour désigner le bout des branches (ici, les probabilités indiquées).
Les arbres de décisions peuvent être utilisés pour de nombreux problèmes et peuvent apprendre de différentes manières : en général, on va partir d’un arbre simple et on va remplacer certaines de ses feuilles par de nouvelles branches avec leurs feuilles, en s’appuyant sur les données d’apprentissage.
Gradient Boosting Machine
Il s’agit d’une technique de Machine Learning qui consiste à réunir plusieurs petites IA (entraînées sur un même problème mais souvent avec des données différentes/partielles) puis de les faire voter sur le résultat d’une nouvelle donnée.
Le schéma ci-contre présente le mode de fonctionnement de Random Forest, qui est très similaire à Boosted Decision Tree (on reviendra sur la différence juste après).
Pour l’algorithme Boosted Decision Tree (qui est du Gradient Boosting s’appuyant sur des arbres de décisions comme petites IA) on a donc :
- un ensemble de 3 arbres de décision qui ont été entraînés séparément sur les données des survivants du Titanic (et parfois on a enlevé une colonne d’informations pour certains : cela permet d’éviter que les arbres aient « les mêmes domaines d’expertise »)
- ensuite, on les a fait voter sur une nouvelle donnée entrante pour évaluer lesquels sont performants et lesquels le sont moins
- en fonction de leurs résultats, pour le vote suivant, on leur accorde plus ou moins de crédit (ce qui améliore la qualité de notre prédiction)
Quelle différence entre Random Forest et Gradient Boosting Machine ?
Les deux diffèrent dans la manière dont les arbres sont construits et dont les résultats sont assemblés (par exemple si on fait un vote majoritaire sur le résultat final, ou si on pondère les réponses en fonction du taux de prédiction correct individuel).
Ainsi, dans Gradient Boosting, les arbres sont construits 1 à 1, avec chaque nouvel arbre qui vient corriger les prédictions incorrectes de l’arbre précédent : ils sont donc mis bout à bout, ce qui ralentit le processus de fabrication des arbres car dans Random Forest, on peut tous les entraîner en même temps, ils sont indépendants.
Mise bout-à-bout : Light GBM
Light GBM appartient à la famille des GBM, avec tous les avantages que cela comporte (haute précision surtout lorsque les données ne sont pas équilibrées) et les inconvénients (lenteur d’apprentissage). Heureusement, grâce à son architecture particulière, Light GBM est en réalité très rapide (surtout comparé à XGBoost) !
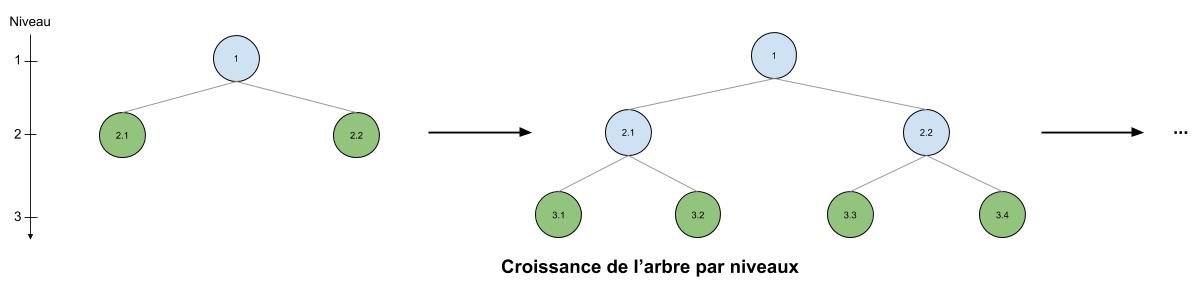
Habituellement, les arbres dans les algorithmes de Gradient Boosting apprennent en divisant leurs feuilles par étage. On parle de « level-wise tree growth » pour signifier que d’une itération à l’autre, on a divisé toutes les feuilles de l’arbre en un nouveau lot de feuilles, ce qui a créé un nouveau niveau (ou étage).
Dans le schéma ci-dessous, ce sont donc les feuilles 2.1 et 2.2 qui sont sélectionnées à l’étape 1 pour être divisées : chacune devient le noeud (et n’est plus une feuille) qui va vers deux feuilles. A l’étape 2, on sélectionne les feuilles du niveau suivant : 3.1, 3.2, 3.3, 3.4 pour qu’elles soient divisées.
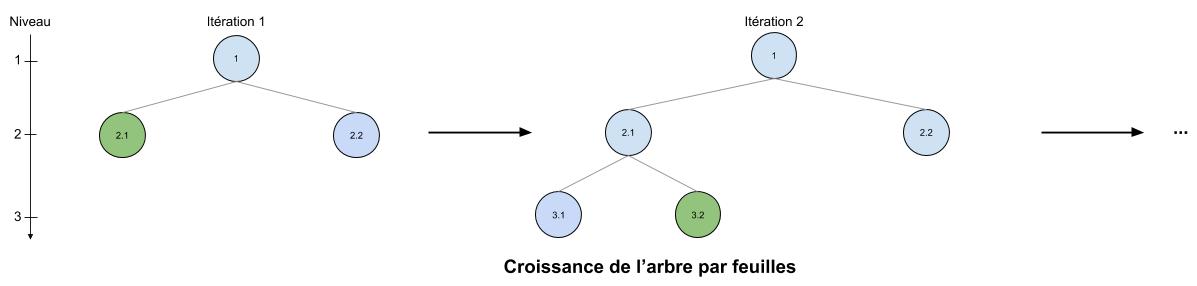
A l’inverse, pour Light GBM, la division des arbres se fait par les feuilles et non les niveaux : on parle de « leaf-wise tree growth« . Ce coup-ci, on ne se soucie plus de prendre les feuilles du dernier niveau mais on choisit une feuille dans l’arbre et elle se divise. Par exemple (cf schéma ci-après) à l’étape 1 on choisit la feuille 2.1, puis à l’étape 2 on prend la feuille 3.2 (qui va donc se diviser en deux nouvelles feuilles), mais à l’étape 3 on peut très bien prendre la feuille 2.2 car on n’est pas restreint au dernier niveau de l’arbre !
Attention toutefois avec LightGBM : il peut facilement sur-apprendre, donc il est déconseillé de l’utiliser avec moins de 10 000 lignes, et il faut être vigilant dans ses résultats.
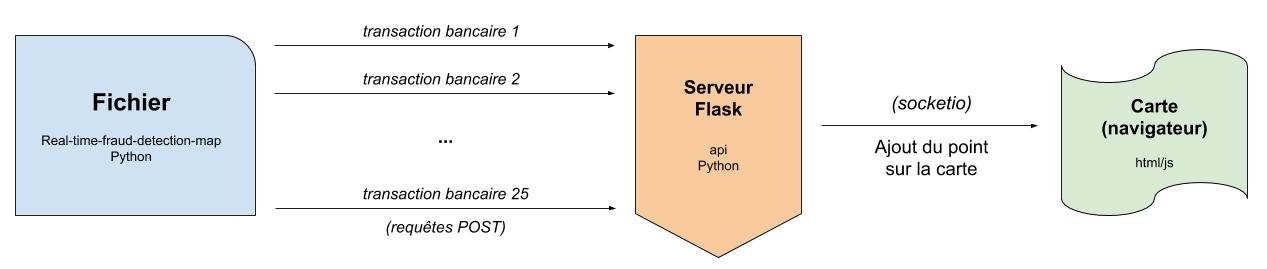
Codons notre LightGBM
Voici l’architecture que nous allons mettre en place dans ce tutoriel :
Pré-requis
Tout ce dont nous aurons besoin pour ce tutoriel a été mis sur le github du projet, donc commencez par télécharger les sources.
Github du projet de détection de fraude
Nous allons re-coder ensemble une partie du fichier « real-time-fraud-detection-map.py » dans cette partie. Si vous voulez consulter les jeux de données indépendamment, nous en utilisons deux :
- celui de la compétition Kaggle sur la détection de fraude bancaire, avec 492 fraudes sur 284 807 opérations bancaires répertoriées !
- celui de SimpleMaps (Basic) qui dispose des coordonnées géographiques (longitude et latitude) de 13 000 villes
Important : dézippez le fichier data.zip dans le répertoire de votre projet (vous aurez alors un dossier data avec les deux csv de données à l’intérieur).
Il faut également avoir Python 3 d’installé, avec certaines dépendances. Ouvrez une invite de commande et saisissez les lignes suivantes :
pip install numpy pip install matplotlib pip install pandas pip install lightgbm pip install scikit-learn pip install requests pip install flask pip install flask_socketio
- numpy, matplotlib et pandas sont des librairies standards de machine learning qui permettent respectivement de travailler avec des vecteurs, de tracer des graphiques et de manipuler des données
- lightgbm est une librairie qui contient l’implémentation de l’algorithme Light GBM et scikit-learn est une librairie plus générale de machine learning avec beaucoup d’outils
- enfin, requests, flask et flask_socketio nous permettront de créer un serveur et de l’appeler.
Remerciements
Un grand merci à
Entraînement du LightGBM
On commence par réaliser les imports de notre fichier « real-time-fraud-detection-map.py » que nous codons ensemble.
Pour convertir certains objets en json, nous allons avoir besoin de la librairie json. « lightgbm » est évidemment indispensable ici, ainsi que l’import de notre fichier qui regroupe des petites méthodes utiles : fraud_utils. Enfin, par anticipation, on ajoute requests et time, pour les appels au webservice.
import json import lightgbm as lgb import fraud_utils as fu import requests import time
Ensuite, on va découper nos données en données d’apprentissage et données de test. Pour ce faire, la colonne « Class » de notre fichier csv de fraude bancaire contient l’information « est-ce que cette transaction est frauduleuse ou non ». Dans fraud_utils, on a écrit une méthode qui permet de diviser aléatoirement le dataset en deux parties (avec la proportion indiquée : 0.2 pour 20% de test et 80% de training, soit la proportion classique).
Il suffit donc d’appeler
# Découpage des données en train/test sets
X_train, X_test, y_train, y_test = fu.split_train_test(fu.data_creditcard.drop('Class', axis=1), fu.data_creditcard['Class'], test_size=0.2)
On crée alors un objet Dataset itérable (via la méthode dédiée dans le module lightgbm) qui viendra alimenter l’algorithme dans la phase d’apprentissage :
# Datasets lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
Enfin, on configure les paramètres de notre LightGBM. Cette étape est la plus importante, car le paramétrage va bien évidemment influer sur la qualité de vos prédictions.
Il est recommandé de tester plusieurs configurations (quitte à utiliser un outil qui en teste plusieurs à la suite, comme Talos pour Keras).
On a donc :
- Le nombre de feuilles des arbres (num_leaves)
- La vitesse d’apprentissage comme dans beaucoup d’algorithmes (learning_rate)
- L’indication comme quoi le dataset est déséquilibré, très importante ici (is_unbalanced)
- Le gain minimal à atteindre pour couper un arbre (min_split_gain)
- Le poids minimal d’une feuille, pour éviter l’overfitting (min_child_weight)
- La régularisation L2 voulue (reg_lambda)
- Le ratio voulu de données à garder, par exemple si on veut accélérer l’entraînement ou éviter de l’overfitting, on peut enlever une partie des données à la volée ainsi (subsample)
- Le type d’output attendu et donc le « loss » à utiliser pour évaluer l’erreur commise par l’algorithme : ici c’est du binary, puisque soit la donnée est frauduleuse = 1 soit elle ne l’est pas = 0 (objective)
- Eventuellement le paramètre « device » pour forcer l’utilisation du GPU plutôt que du CPU par l’algorithme (ce n’est pas indispensable, puisqu’avec le CPU l’entraînement est terminé en moins de 10s)
- Et enfin la tâche à accomplir, ici de l’entraînement (task)
- Ainsi que le nombre d’epochs qui viendra en paramètre externe à LightGBM
Pour savoir combien d’epoch réaliser, il « suffit » de regarder la courbe d’apprentissage et de repérer le moment où il y a de l’overfitting ou plus de gain. Ensuite, on peut soit s’arrêter là, soit diminuer la vitesse d’apprentissage et continuer (pour améliorer plus finement les résultats).
# Parameters
parameters = {'num_leaves': 2**8,
'learning_rate': 0.1,
'is_unbalance': True,
'min_split_gain': 0.1,
'min_child_weight': 1,
'reg_lambda': 1,
'subsample': 1,
'objective':'binary',
#'device': 'gpu', #comment if you're not using GPU
'task': 'train'
}
num_rounds = 300
Enfin, il ne reste plus qu’à lancer l’entraînement du modèle avec la ligne :
# Training clf = lgb.train(parameters, lgb_train, num_boost_round=num_rounds)
En bonus, on peut évaluer la précision de notre modèle avec une matrice de confusion grâce au code suivant :
# Affichage de quelques métriques pour évaluer notre modèle
y_prob = clf.predict(X_test)
y_pred = fu.binarize_prediction(y_prob, threshold=0.5)
metrics = fu.classification_metrics_binary(y_test, y_pred)
metrics2 = fu.classification_metrics_binary_prob(y_test, y_prob)
metrics.update(metrics2)
cm = metrics['Confusion Matrix']
metrics.pop('Confusion Matrix', None)
print(json.dumps(metrics, indent=4, sort_keys=True))
fu.plot_confusion_matrix(cm, ['no fraud (negative class)', 'fraud (positive class)'])
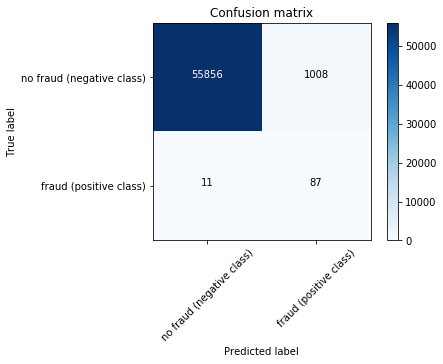
Voici la matrice que l’on obtient (qui peut différer de la votre en raison du découpage des données et de l’initialisation du modèle).
Comment lire cette image ?
- Tout d’abord, on s’intéresse à la diagonale « zone en haut à gauche » – « zone en bas à droite » : au premier endroit (55 856), on a le nombre de transactions non-frauduleuses que notre LightGBM a placé dans la catégorie « transaction non-frauduleuse » (il avait donc raison). A l’autre endroit (87), on a l’inverse soit le nombre de transactions frauduleuses déclarées comme telles (à juste titre)
- Ensuite, en bas à gauche (11), on a le nombre de transaction frauduleuses que l’algorithme a cru être non-frauduleuses. Ce chiffre est crucial, car il implique une perte d’argent pour la banque « qui s’est faite avoir ».
- Enfin, en haut à droite, on a le nombre de transactions non-frauduleuses que le LightGBM a classé comme étant une fraude (à tort). En général, les banques vont soit refuser ces transactions (car elles ne savent pas qu’elles sont en réalité légitimes), ce qui va engendrer le mécontentement des utilisateurs, soit engager un humain pour vérifier chaque transaction et confirmer si elle est frauduleuse ou non.
II. Visualisation en temps réel des détections de fraude, sur une carte !
Sans plus de suspense, voici ce que nous allons créer ensemble comme type de visualisation (tout a été assemblé en un GIF) :
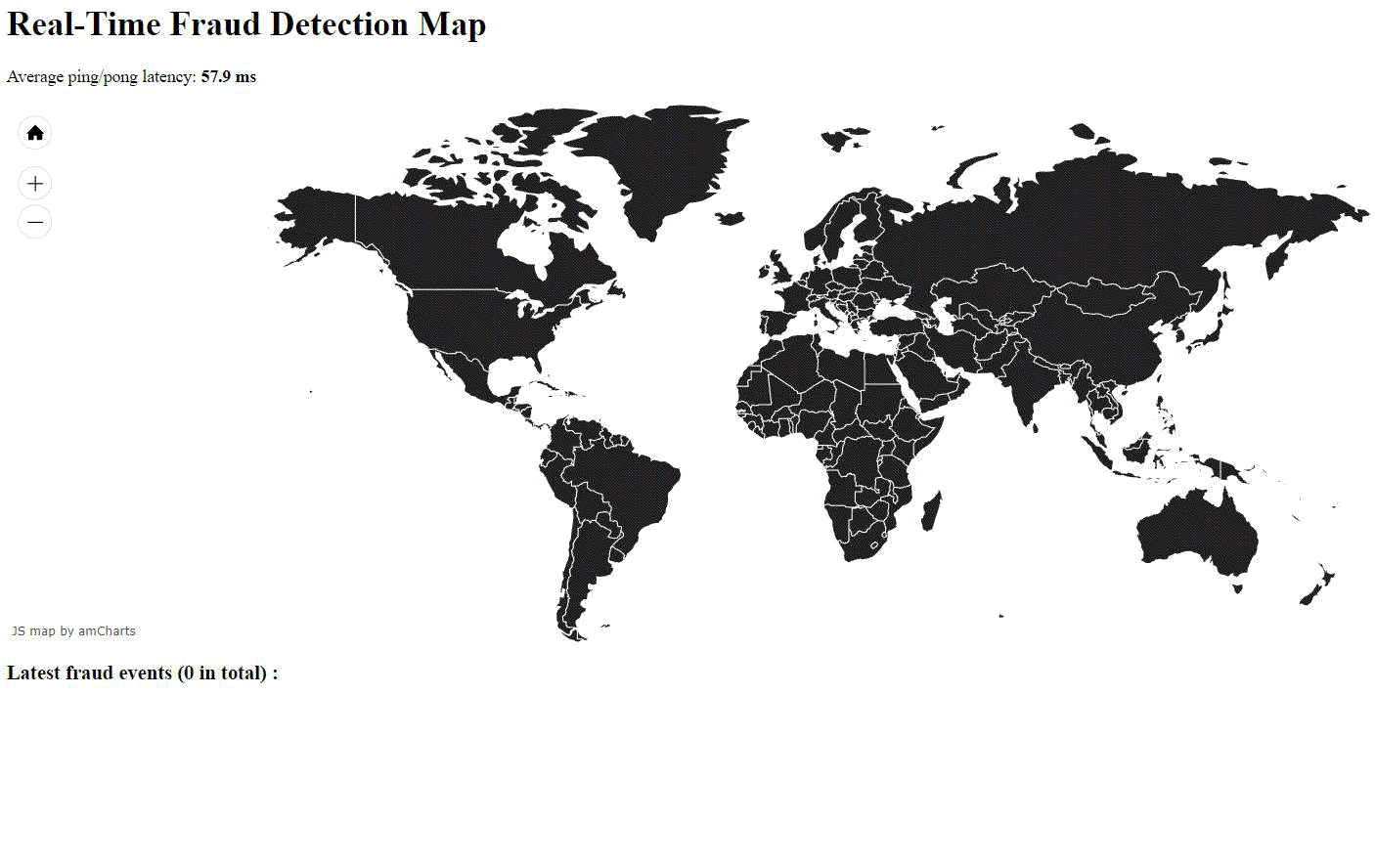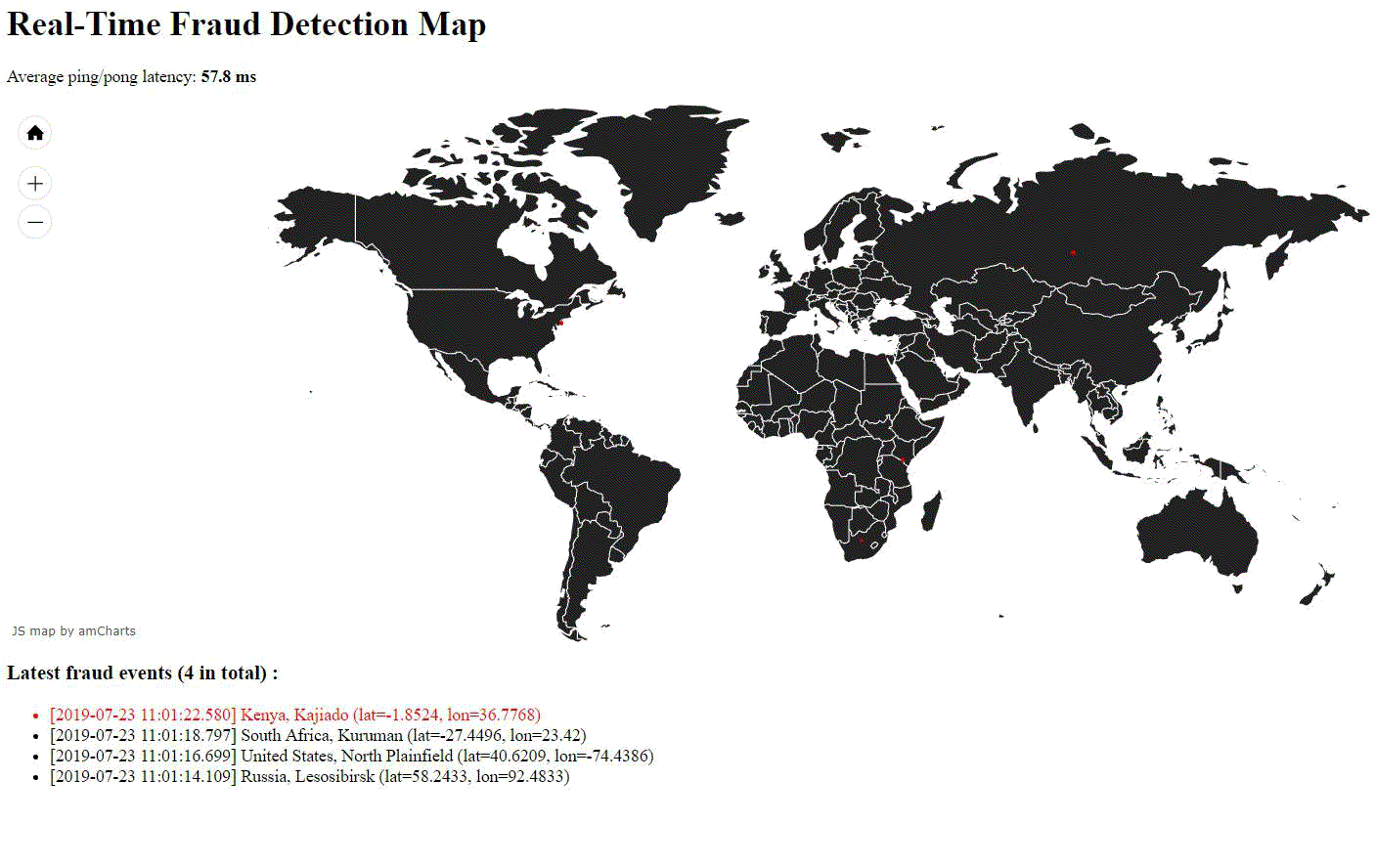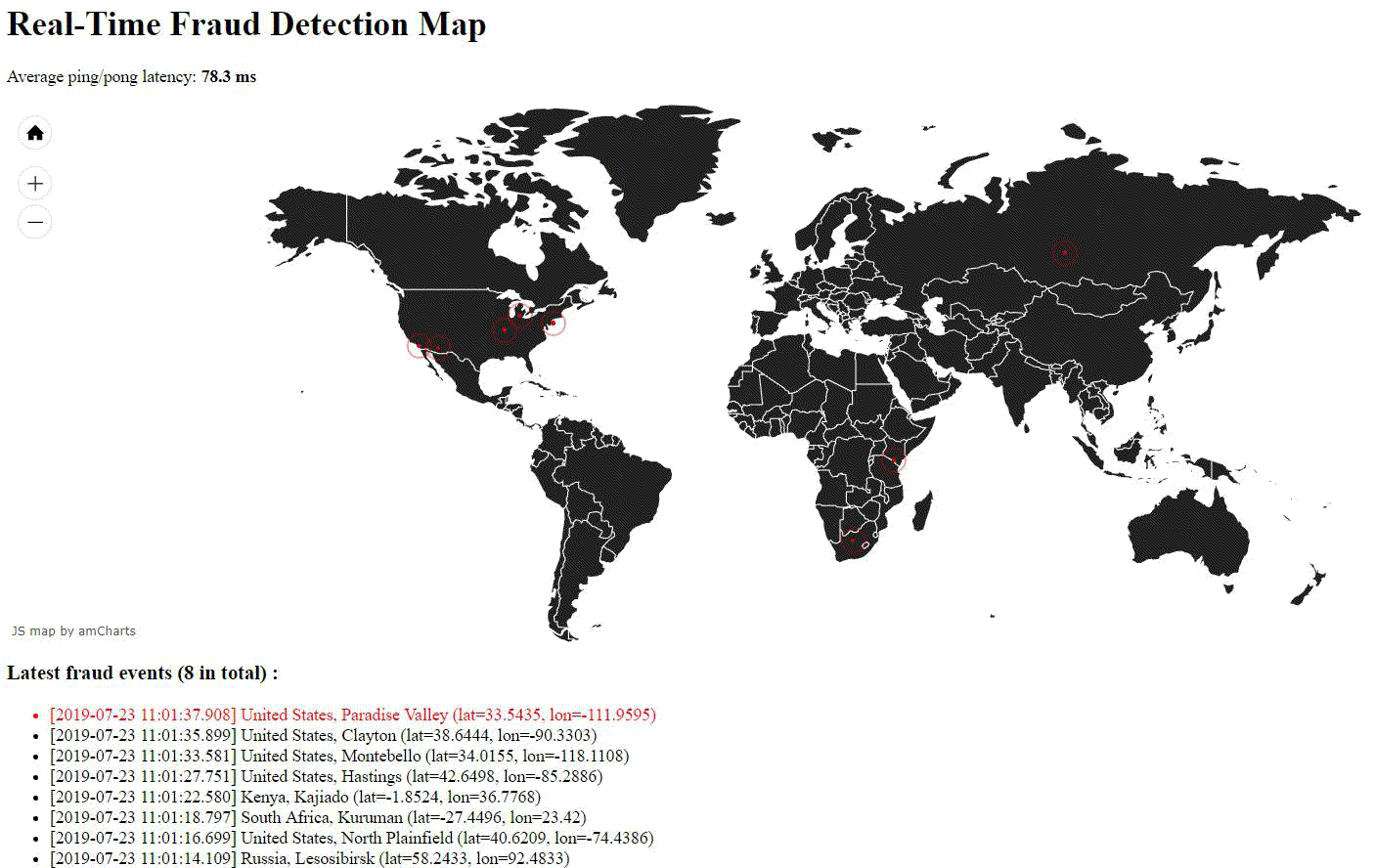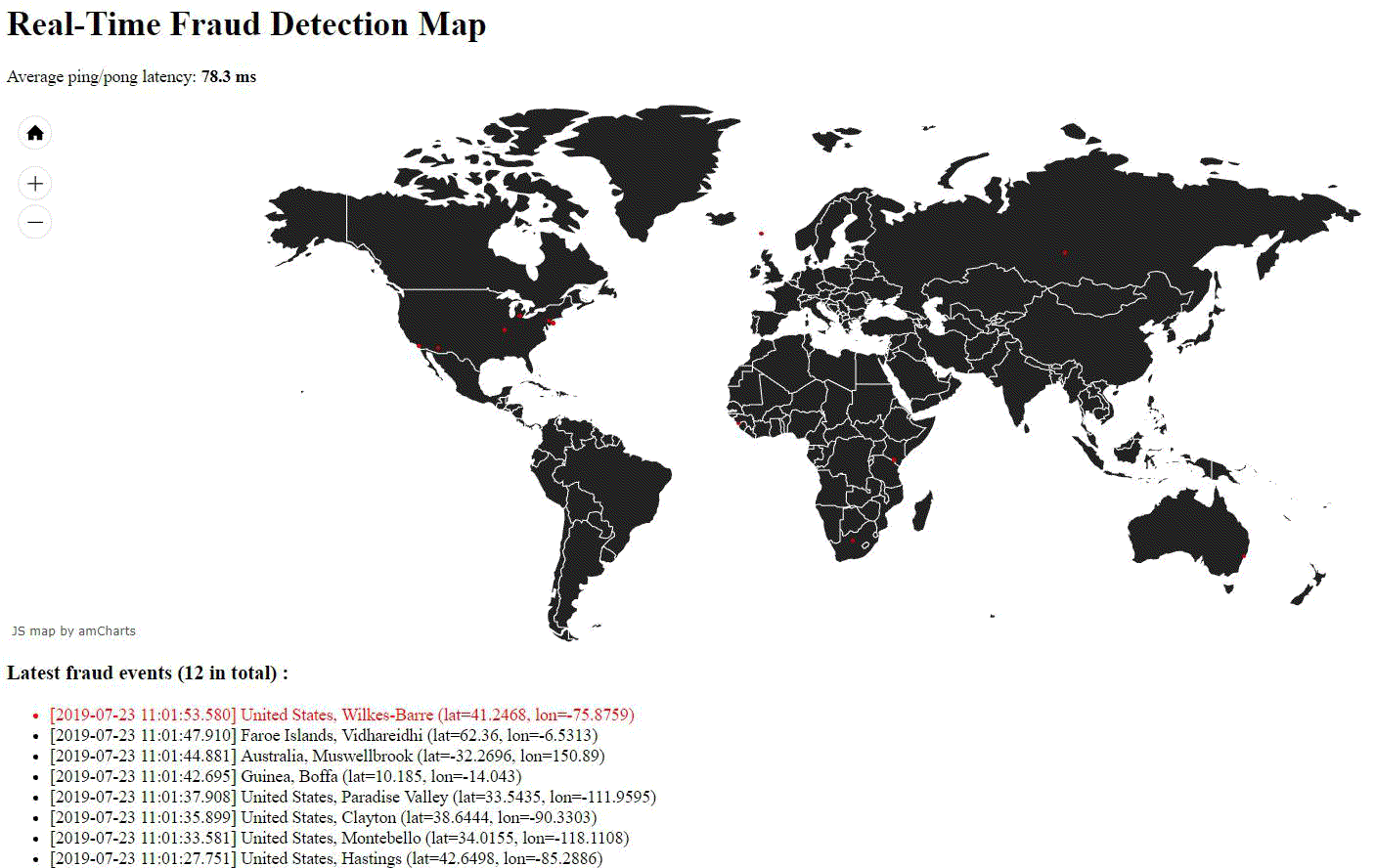
Codons notre API
Notre API est très classique à ceci près qu’il utilise des websockets grâce à flask_socketio.
Qu’est-ce qu’un websocket ? Pour effectuer des requêtes (ou recevoir des données), une page web utilise différents canaux de communication. Par exemple, on a l’AJAX qui peut rafraîchir le contenu de la page (via ces appels) sans tout recharger (à condition de contacter lui-même le serveur, sinon il ne peut rien recevoir)…
Sauf qu’AJAX ne permet pas de conserver des informations une fois l’appel terminé. Pour améliorer les performances de notre application, qui devrait ouvrir un canal puis le refermer à chaque fois qu’une donnée arriverait sinon, on utilise les websocket qui vont conserver le canal de communication ouvert ET permettre les échanges à double sens : votre serveur pourra, de lui-même, contacter la page web !
Créons un fichier « api.py » et commençons par les imports qui, sans surprise, concernent surtout Flask (et ce dont nous aurons besoin pour lire les données/faire les prédictions) :
from flask import (Flask, request, abort, jsonify, make_response, render_template) from flask_socketio import SocketIO, emit import pandas as pd import lightgbm as lgb import fraud_utils as fu import os import time
Ensuite, on définit quelques paramètres (codes HTTP par exemple) et une clé secrète si besoin. On note au passage l’enregistrement dans SocketIO de notre serveur Flask, indispensable à la suite : « socketio » désignera notre canal de communication et permettra d’envoyer/recevoir des informations de la page web.
BAD_REQUEST = 400 STATUS_OK = 200 NOT_FOUND = 404 SERVER_ERROR = 500 app = Flask(__name__) # app app.static_folder = 'static' # define static folder for css, img, js app.config['SECRET_KEY'] = 'secret!' socketio = SocketIO(app)
A présent, on définit un certain nombre d’endpoint i.e. des fins d’URL qui afficheront différentes pages web. Par exemple, si on se rend sur http://localhost:5000/connect, on verra s’afficher à l’écran le message « Client connected ». On en profite aussi pour créer des handlers d’erreurs qui s’activeront s’il y a un problème dans les requêtes.
Pour ne pas charger le tutoriel, merci de regarder le code du fichier api.py qui est dans notre projet Github : de la ligne 28 à 78
La seule partie vraiment intéressante du code ci-dessus est :
@app.route('/map')
def map():
return render_template('index.html')
Sur l’URL http://localhost:5000/map, on aura donc la page index.html qui s’ouvrira (avec la carte et les javascripts qui font tout en temps réel) !
A des fins de test, on crée le endpoint /predict (à regarder dans le fichier du github également) mais aussi et surtout /predict_map qui va :
- récupérer la donnée envoyée par quelqu’un d’autre (cf paragraphe suivant)
- demander au LightGBM entraîné de nous prédire s’il s’agit d’une transaction frauduleuse ou non
- si la probabilité est suffisamment élevée que la transaction soit frauduleuse, alors
- récupérer dans les données des coordonnées géographiques une ville au hasard (en effet, dans nos données d’origine, il n’y a aucune information géographique : on l’ajoute nous-même pour plus de réalisme)
- envoyer au site web les coordonnées de la ville de cette transaction frauduleuse
Voici le code :
@app.route('/predict_map', methods=['POST'])
def predict_map():
X = manage_query(request)
y_pred = model.predict(X)[0]
print("Value predicted: {}".format(y_pred))
if y_pred >= fu.FRAUD_THRESHOLD:
row = fu.select_random_row_cities()
location = {"country":row["country"].iloc[0], "title": row["city"].iloc[0], "latitude": row["latitude"].iloc[0], "longitude": row["longitude"].iloc[0]}
print("New location: {}".format(location))
socketio.emit('map_update', location, broadcast=True, namespace='/fraud')
return make_response(jsonify({'fraud': y_pred}), STATUS_OK)
La ligne importante est :
socketio.emit('map_update', location, broadcast=True, namespace='/fraud')
qui permet d’émettre un message intitulé « map_update » avec l’objet JSON contenant les coordonnées de la ville où a eu lieu la fraude. Broadcast=True signifie que l’on envoie le message dans le canal socketio à tous ceux qui y sont abonnés, et que cela concerne la partie « fraud » (ici on n’a pas d’autre partie, donc on pourrait se passer du namespace… disons que ça permet de limiter rapidement et facilement qui doit analyser/recevoir ce message).
Enfin, on ajoute un bout de code qui s’assure qu’il y a un modèle pré-entraîné de LightGBM avant de démarrer le serveur (tentatives toutes les secondes pendant 120s) :
# Load the model as a global variable
max_try=120
cpt = 0
while cpt < max_try and not os.path.exists(fu.BASELINE_MODEL):
cpt += 1
print("No model found ("+str(cpt)+") : "+fu.BASELINE_MODEL)
time.sleep(1)
if cpt == max_try:
raise Exception("Launch aborted")
Puis on charge le modèle entraîné et on démarre le serveur avec socketio.run (très important !) :
model = lgb.Booster(model_file=fu.BASELINE_MODEL)
if __name__ == "__main__":
try:
print("Server started")
socketio.run(app, debug=True)
except:
raise
finally:
print("Stop procedure")
Un bout de code pour ajouter des données
Maintenant que notre API est prêt à recevoir des transactions et à les analyser (pour ensuite les afficher sur la carte si elles sont frauduleuses), on va ajouter un bout de code dans « real-time-fraud-detection-map.py » qui va :
- Vérifier si le serveur est démarré (1 tentative par seconde pendant 120s)
- Générer autant d’appels que ce qui est demandé, en les espaçant d’un temps aléatoire compris entre 0.2s et 5s, pour plus de réalisme dans la visualisation
On commence donc par vérifier si le serveur est démarré avec une boucle while s’appuyant sur notre méthode « test_server_online » de fraud_utils :
max_try=120
cpt = 0
while cpt < max_try and not fu.test_server_online():
cpt += 1
print("Server is not ready ("+str(cpt)+")")
time.sleep(1)
if cpt == max_try:
raise Exception("Max attempts reached")
print("Server ready for real-time fraud detection !")
print("You can now go to "+fu.URL_API + '/map')
Puis on crée notre boucle qui va générer des appels de service avec des données. Pour que des points s’ajoutent rapidement à la carte, on va envoyer des données frauduleuses tirées du dataset de test. L’URL de l’API à contacter est : http://localhost:5000/predict_map
nb = 25 #nombre de points à ajouter à la carte
for i in range(nb):
# Récupération d'une fraude
vals = y_test[y_test == 1].index.values
X_target = X_test.loc[vals[0]]
dict_query = X_target.to_dict()
# Affichage sur la carte via un appel au webservice
headers = {'Content-type':'application/json'}
end_point_map = fu.URL_API + '/predict_map'
requests.post(end_point_map, data=json.dumps(dict_query), headers=headers)
fu.wait_random_time(0.5,5)
Il suffit d’exécuter ce code pour ajouter 25 points sur la carte, dans votre navigateur.
Codons notre site web (HTML/JS)
On ne va pas tout recoder, mais s’intéresser à la mécanique qui se cache derrière la communication Flask -> HTML en temps réel.
Fichier HTML
Il n’y a quasiment rien dedans, à part l’import des différents fichiers (css, js) ainsi que quelques div avec des identifiants : le code javascript va venir écrire à l’intérieur de ces div et autre.
Par exemple,
<ul id="list-incidents"></ul>
est une liste vide (sans aucun « li » à l’intérieur) dans laquelle on pourra ajouter des lignes avec (en javascript)
document.getElementById('list-incidents').innerHTML = "<li>une ligne de liste</li>"
La carte amCharts
amCharts est une librairie Javascript permettant de créer très facilement des cartes ou des graphiques et de les animer. Bien sûr, vous êtes libres d’utiliser n’importe quelle librairie (par exemple d3js est fortement conseillée), car c’est indépendant de notre système de communication avec Flask !
Ceci étant, on a placé le fichier « ammap.js » fourni par amCharts pour animer la carte « map.png ».
Le Javascript
Il s’agit du coeur de notre communication entre Flask et la page web affichée dans notre navigateur. Tout le code intéressant est dans le fichier « frauddetection.js ».
D’abord, il y a la définition du namespace : tout message dont le namespace correspond à celui indiqué ici sera analysé par le script.
var namespace = "/fraud";
Ensuite, il faut se connecter au canal socketio :
var socket_url = location.protocol + "//" + document.domain + ":" + location.port + namespace; var socket = io.connect(socket_url);
Après ça, il y a du paramétrage de la carte (qui ne nous intéresse pas vraiment dans ce tutoriel), et surtout la partie où « on surveille les messages qui circulent dans socketio et en particulier ceux dont le libellé est map_update » :
// Location updated emitted by the server via websockets
socket.on("map_update", function (msg) {
var message = "New event in " + msg.title+", "+ msg.country + ", (latitude=" + msg.latitude
+ ", longitude=" + msg.longitude + ")";
console.log(message);
eventDate = moment().format("YYYY-MM-DD HH:mm:ss.SSS")
var newLocation = new Location(msg.title, msg.latitude, msg.longitude, msg.country, eventDate);
mapLocations.push(newLocation);
document.getElementById('totalfraud').innerHTML = mapLocations.length
document.getElementById('list-incidents').innerHTML =
'<li class="latest">[' + eventDate + '] '+msg.country+', '+msg.title+' (lat='+msg.latitude+', lon='+msg.longitude+')</li>'
+ document.getElementById('list-incidents').innerHTML.replace("latest","");
//clear the markers before redrawing
mapLocations.forEach(function(location) {
if (location.externalElement) {
location.externalElement = undefined;
}
});
map.dataProvider.images = mapLocations;
map.validateData(); //call to redraw the map with new data
});
- socket.on permet de créer un listener qui va réagir dès qu’un message arrivera depuis le serveur, s’il a le libellé « map_update » (comme les messages envoyés depuis Flask : /predict_map)
- pour récupérer le contenu du message, il faut se rappeler qu’il s’agit de json : on écrit donc msg.country, msg.latitude, etc… (comme dans le json envoyé depuis Flask)
- puis on fait ce que l’on veut de ces informations, comme les afficher sur la carte, les compter, les supprimer si elles sont trop vieilles, etc… !
Enfin, pour afficher le ping en haut de l’écran (temps de réponse entre le serveur et la page web) on va procéder ainsi :
- la page web envoie une demande de statut au serveur
- celui-ci reçoit la demande et répond que tout va bien
- la page web reçoit la réponse et mesure le temps écoulé entre sa question et sa réponse : nous avons ainsi obtenu la latence entre le serveur et la page
L’émission se fait grâce à :
socket.emit("my_ping");
Et la réception grâce à :
socket.on("my_pong", function () {...
Pour rappel, le serveur a reçu de son côté my_ping (et répondu) grâce à :
@socketio.on('my_ping', namespace='/fraud')
def ping_pong():
"""Receives my_pong from the client and sends my_pong from the server"""
emit('my_pong')
Comment réutiliser ce code pour une autre visualisation ?
Comme vous l’avez vu, le code n’est pas compliqué et le principe est toujours le même :
- on crée un serveur Flask qui va d’une part « render_template » une page web (fichier html avec le javascript qu’on veut) et d’autre part recevoir, de la part de n’importe qui, des données à traiter
- on crée un script qui va envoyer des données à traiter à notre serveur (très facilement avec requests.post)
- enfin, en javascript, on récupère les informations envoyées depuis le code Python Flask vers la page web grâce à « socketio.emit » : on utilise la détection de l’event « socket.on »
Ensuite, on est en javascript et on peut faire tout ce qu’on veut, comme afficher une carte, écrire quelque part qu’il y a eu tel ou tel événement, etc…, c’est du développement très classique à partir de là !
Crédit de l’image de couverture : screenshot de page web de Lambert Rosique à partir de la carte de



{kind=link}