Ce TP fait suite au focus expliquant en détails comment fonctionne un réseau de neurones convolutifs (CNN). Il est fortement recommandé d’avoir lu la partie théorique pour bien comprendre la suite du TP.
Lien vers le focus sur le CNN (convolutional neural network)
II. Petit TP sur les réseaux de neurones convolutifs
La partie théorique est enfin terminée, bravo ! Je vous propose à présent de découvrir un petit TP sur la reconnaissance d’image grâce aux réseaux de neurones convolutifs (si vous n’avez pas suivi notre tutoriel sur les MobileNets), où nous verrons trois réseaux de neurones convolutifs de complexité différente.
1. Le problème
Pour cet exercice, nous allons créer un réseau de neurones convolutionnels capable de reconnaître les chiffres écrits à la main !
Le principe est simple : à partir d’une banque d’images de chiffres écrits à la main (et annoté pour dire de quel chiffre il s’agit), fournie par Keras (un framework de deep learning), nous allons entraîner 3 IA différentes et les comparer.



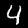

Dataset d’images de chiffres tracés à la main en 28×28 pixels : le MNIST (crédit : MNIST)
2. Mise en place
a) Le github
Comme à l’accoûtumée, les sources sont disponibles sur le github de Pensée Artificielle. Il est également à noter que le code s’inspire des excellents TP de Eijaz Allibhai et de MachineLearningMastery.
Lien GitHub vers le TP complet
b) Les installations préalables
Je pars du principe que vous avez déjà installé Python 3 et savez vous en servir. Si ce n’est pas le cas, n’hésitez pas à relire notre tutoriel sur le réseau de neurone artificiel, ou à simplement aller sur le site de Python et à télécharger la dernière version !
Commençons par installer Tensorflow, le framework de Google pour faire du Deep Learning. Notez dès à présent que nous ne nous en servirons pas… mais on utilisera Keras, qui est un framework s’appuyant sur Tensorflow en backend (il en simplifie les commandes et ajoute certaines fonctionnalités).
Ouvrez une invite de commande et saisissez :
pip install tensorflow
Attention : Si vous préférez utiliser Tensorflow GPU qui est plus rapide (mais nécessite une carte graphique particulière et des installations supplémentaires), on a rédigé un tutoriel dédié !
Ensuite, il suffit d’installer Keras et matplotlib, une librairie permettant de tracer des graphiques (et de visualiser nos images depuis notre éditeur : Spyder 3 ou Jupyter Notebook). On ajoute également Pillow qui permet de manipuler (sauvegarder notamment) des images, car on réalisera un petit export du dataset en bonus. Si vous n’avez pas l’intention de sauvegarder des images, vous pouvez l’enlever des installations et supprimer la partie du tutoriel correspondante.
pip install keras pip install matplotlib pip install pillow
Conseil : si vous n’utilisez pas un éditeur avec une console IPython et donc exécutez vos programmes avec la commande Python appliquée à tout le fichier, je vous recommande fortement de taper :
pip install spyder3 spyder3
Spyder 3 est un éditeur doté de la capacité d’exécuter des bouts de codes Python (surlignez-les et faites CTRL + ENTER) sans perdre sa « session ». Ainsi, une variable déclarée le restera tant que la console ne sera pas redémarrée, et sera même visible dans l’onglet Variables !
c) Notre cible / Nos cibles de CNN
Voici le schéma d’architecture des réseaux de neurones que nous allons réaliser dans ce TP. Vous remarquerez un certain nombre de différences, qui aboutissent à des résultats plus ou moins bons. Les paramètres ont été sélectionnés à la fois par expérience et de manière empirique, car bien souvent on essaie plusieurs architectures avant de trouver la meilleure !
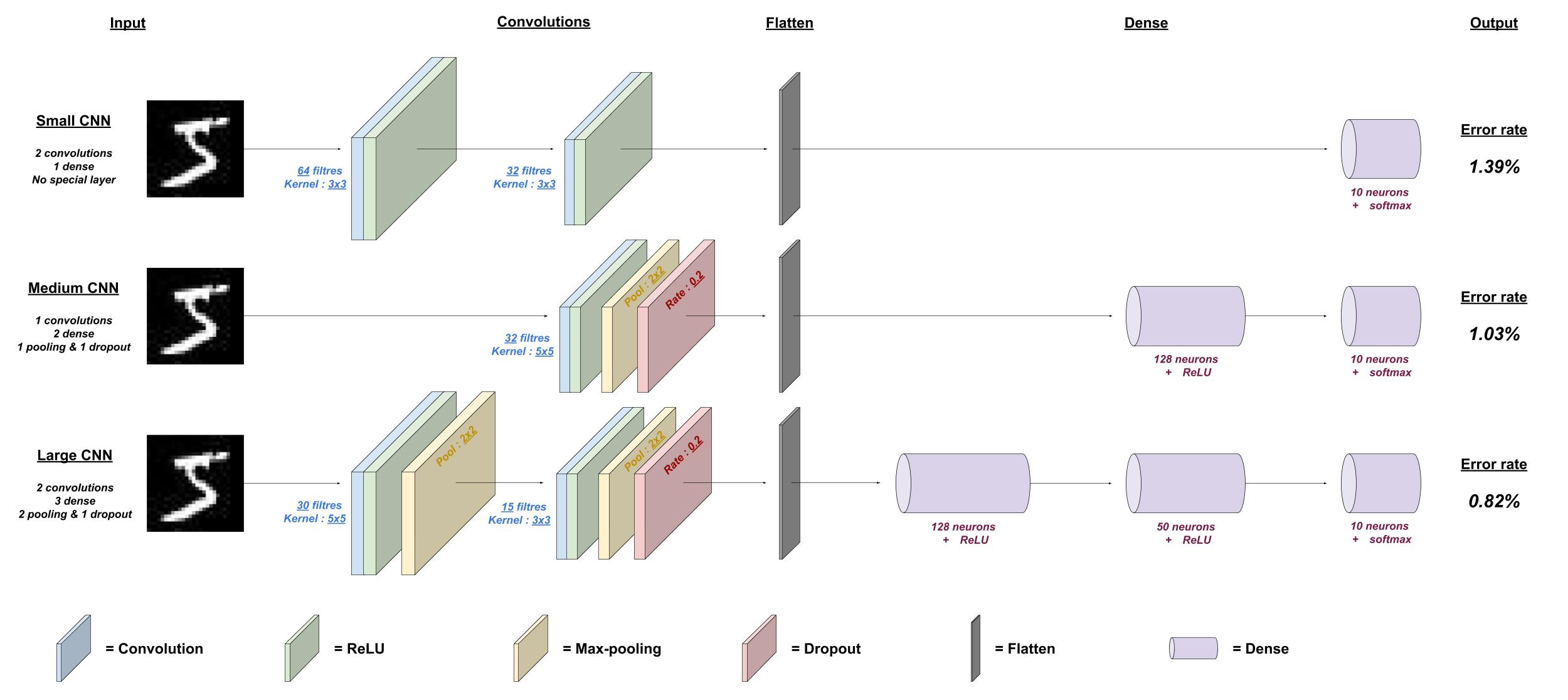
2. Construction du réseau
a) Organisation du code
Au niveau des répertoires, si vous avez récupéré notre projet GitHub (sinon, il va falloir créer les éléments au fur et à mesure), vous devriez en avoir trois :
- data_examples : ce répertoire contient quelques exemples d’images de la base d’apprentissage. Une méthode a été écrite dans cnnutils (voir plus loin) pour en télécharger d’autres et voir ce qu’apprend notre CNN.
- drawings : répertoire dans lequel vous pourrez mettre des chiffres tracés à la main, pour tester vos algorithmes avec votre propre écriture !
- save_models : les sauvegardes des modèles déjà entraînés par votre ordinateur. Afin de vous éviter un entraînement long et fastidieux (en fonction de votre ordinateur, il faut compter de 5min à 1h), les 3 CNN ont été sauvegardés ici.
Au niveau des fichiers, vous en trouverez cinq :
- cnnutils : un fichier Python contenant quelques fonctions déjà écrites qui vous serviront. Nous vous conseillons d’ouvrir le fichier et d’en étudier le contenu. Si vous n’avez pas récupéré le projet GitHub, une partie de ces méthodes sera donnée au fur et à mesure des TP donc ne vous inquiétez pas !
- preparedata : ce sera le premier fichier que nous écrirons dans ce TP. Il contiendra toute la partie « récupération et préparation » des données d’apprentissage
- small-cnn-tutorial-keras : le premier CNN implémenté et le plus simple des trois
- medium-cnn-tutorial-keras : le second CNN implémenté, avec l’ajout du pooling et du dropout
- large-cnn-tutorial-keras : le troisième CNN implémenté, plus complexe
En résumé, nous allons donc écrire ensemble le fichier « preparedata » et « small-cnn-tutorial-keras », puis nous dupliquerons ce dernier et le modifieront pour avoir les medium et large CNN.
PS : voir la partie « Préparation des données » pour le dernier fichier.
b) Les imports du « tp réseau de neurones convolutifs »
Créez le fichier preparedata.py si ce n’est pas déjà fait. Nous allons utiliser les bibliothèques suivantes pour préparer nos données :
- numpy : pour manipuler les vecteurs et interagir avec Keras, notre framework de Deep Learning. Cette bibliothèque est très largement employée.
- keras : le framework de deep learning. L’import de Tensorflow en backend se fait automatiquement par Keras.
De Keras, on ne va prendre que le mnist (qui est le nom du dataset que l’on va utiliser), quelques utilitaires (dans np_utils), et le backend Tensorflow, nommé K, pour lequel on va spécifier le format de saisie des couches du modèle grâce à « th ».
« th » signifie que les kernels des convolutions auront pour format (depth, input_depth, rows, cols), à l’inverse de « tf » qui veut dire (rows, cols, input_depth, depth).
Ajoutez ainsi les lignes suivantes dans votre fichier :
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras import backend as K
K.set_image_dim_ordering('th')
De la même manière, créez le fichier small-cnn-tutorial-keras.py pour lequel nous aurons besoin de :
- numpy, encore une fois
- keras, absolument indispensable
- preparedata (fichier créé juste avant) et cnnutils (si vous l’avez)
Dans Keras nous prendront cette fois le modèle, les couches (convolutions, pooling, etc…) et le backend pour en spécifier le format.
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras import backend as K
K.set_image_dim_ordering('th')
import preparedata as pr
import cnnutils as cu
Enfin, dans les deux fichiers, on va forcer le random de numpy : lors de la génération du modèle, de nombreux paramètres sont choisis aléatoirement par Keras via Numpy. Afin d’avoir exactement le même modèle (et donc les mêmes résultats), il est courant (DANS LES TUTORIAUX UNIQUEMENT) de fixer le random grâce à cette ligne (que vous devez donc ajouter).
# fix random seed for reproducibility seed = 7 np.random.seed(seed)
c) La préparation des données
On attaque les choses sérieuses, puisqu’on va voir ensemble comment importer les données du MNIST et, surtout, quels traitements y apporter avant de les injecter dans notre CNN.
La partie « traitements » est généralement la plus importante (et négligée) en machine learning, car elle a un impact considérable sur les résultats des IA. Les plus curieux trouveront le fichier « no_preparation_small_cnn_tutorial_keras.py » et les deux sauvegardes de modèle correspondantes, qui reprend le modèle Small sans préparer les données. Le taux d’erreur est alors de 2.64% (contre 1.39% pour la version préparée) !!
Commençons par charger les données, qui sont
- 60 000 images d’apprentissages (matrices carrées de taille 28×28) en niveaux de gris (donc 1 seul channel)
- Et 10 000 images de test (mêmes caractéristiques)
depuis le jeu de données du MNIST. Keras nous apprend également que toutes les images sont des chiffres uniques entre 0 et 9 inclus.
# load data (X_train, y_train), (X_test, y_test) = mnist.load_data()
Ensuite, par rapport à notre configuration « th » de TensorFlow, il va falloir modifier légèrement la structure des matrices pour qu’elles soient utilisables dans le modèle.
On a pour l’instant du 60000x28x28, et on voudrait du 60000x1x28x28 (nombre d’entrées, nombre de channels, largeur d’une entrée, hauteur d’une entrée). La commande « reshape » permet exactement de faire ça, à laquelle on ajoute « astype » pour convertir les matrices en float32 au lieu de uint8.
# reshape to be [samples][pixels][width][height]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype('float32')
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype('float32')
Pourquoi convertir en float au lieu de garder des entiers ?
Dans la version no_preparation_small_cnn, on a conservé des entiers entre 0 et 255 alors que dans la version améliorée, on a converti en float avant de diviser par 255 (pour avoir des valeurs entre 0 et 1). Cette conversion et normalisation est une étape très importante de la préparation des données, car elle permet de réduire l’écart entre les valeurs extrêmes et d’éviter les overflow dans les calculs car des nombres supérieurs à 1 peuvent rapidement tendre vers l’infini si on n’est pas prudent.
Prenons un exemple pour se donner une idée de ce qu’il se passe : un pixel valant 200 par rapport à un pixel valant 50 aura une valeur 4 fois supérieure (ou un écart de +150). Dans un réseau de neurones classiques (plus facile à imaginer), on regarde pour un neurone donné tous les signaux qui y arrivent. Pour le neurone relié à notre 200 et notre 50, le pixel à 200 sera donc 4 fois plus important et dictera quasiment toutes les sorties de ce neurone, (ou alors il faudra un entraînement plus long pour que les poids s’équilibrent pour compenser ce x4 / +150). A l’inverse, si les données sont normalisées, la valeur reste toujours 4 fois supérieure MAIS l’écart est très faible. Une liaison entre les neurones peut donc facilement compenser cette différence si besoin, avec moins d’entraînement et plus d’efficacité/justesse.
Pour plus de détails sur l’importance de la normalisation, n’hésitez pas à consulter l’article sur le perceptron multi-couches.
Ajoutons le code pour normaliser les valeurs :
# normalize inputs from 0-255 to 0-1 X_train = X_train / 255 X_test = X_test / 255
Enfin, dernier point, on va travailler les vecteurs de sorties pour qu’ils reflètent la valeur prédite par le réseau. En effet, il serait très compliqué (voire impossible de manière efficace et juste) d’avoir un CNN qui nous renverrait un seul et unique résultat entre 0 et 9 valant le chiffre détecté dans l’image. A l’inverse, il est plus facile pour un CNN de nous donner la probabilité que ce soit un 0, la probabilité que ce soit un 1, etc… jusqu’à 9.
Cette conversion des variables catégoricielle se fait facilement, grâce au système de « one hot encode » :
# one hot encode outputs y_train = np_utils.to_categorical(y_train) y_test = np_utils.to_categorical(y_test) num_classes = y_test.shape[1]
A noter que num_classes représente le nombre de valeurs de sorties du CNN.
Pour conclure, je vous propose d’encapsuler toute cette préparation des données dans une seule et même méthode, qui sera appelée par nos CNN en amont, et qui retournera nos différentes variables. Vous devriez avoir ceci au final :
def get_and_prepare_data_mnist():
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][pixels][width][height]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype('float32')
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype('float32')
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
return (X_train, y_train), (X_test, y_test), num_classes
d) Le modèle de CNN
Les données étant prêtes, on va travailler notre « Small CNN » conformément au schéma d’architecture présenté en début de partie.
Pour commencer, chargeons les données grâce à la méthode get_and_prepare_data_mnist que nous avons créé dans « preparedata » :
# import MNIST dataset (X_train, y_train), (X_test, y_test), num_classes = pr.get_and_prepare_data_mnist()
Pour déclarer un nouveau modèle de deep learning dans Keras, on utilise l’instruction suivante, qui vaut aussi bien pour des ANN que des CNN qu’autre chose :
model = Sequential()
Ensuite, les méthodes à appeler sont très parlantes. Rappelons que notre objectif est d’avoir successivement :
- Une convolution de 64 filtres en 3×3 suivie d’une couche d’activation ReLU
- Une convolution de 32 filtres en 3×3 suivie d’une couche d’activation ReLU
- Un flatten qui va créer le vecteur final à envoyer au réseau de neurones artificiels (alias dense)
- Un dense, réseau de neurones artificiels qui aura 10 neurones et sera suivi d’un softmax
Remarque : softmax est une fonction mathématique qui permet de normaliser un vecteur pour en faire des probabilités (grosso modo).
Pour déclarer une convolution, la syntaxe est d’appeler Conv2D avec en paramètres le nombre de filtres, les dimensions du noyau (3×3), en précisant input_shape : la taille des données d’entrée (uniquement sur la 1ère couche du CNN) et enfin l’activation.
Pourquoi Conv2D et pas juste « Conv » ? Dans Keras, la possibilité existe d’utiliser des convolutions à 1, 2 ou 3 dimensions (ainsi que les convolutions spéciales vues dans le paragraphe dédié). Comme on l’a dit, les convolutions s’appliquent séparément à chaque channel de l’image. Elles sont donc en 2D et non en 3D !
Le Flatten ne prend aucun paramètre, car il n’y a besoin de rien de particulier pour mettre toutes les images bout à bout.
En revanche, le Dense qui sert à déclarer notre réseau de neurones artificiels prend en paramètre le nombre de neurones de la couche de sortie, et offusque tout le reste (sauf le paramètre « activation » qui vaut ici softmax).
Avec ces indications et quelques recherches dans la bibliographie Keras, vous devriez pouvoir écrire la construction du Small CNN sinon la voici :
# create model model = Sequential() model.add(Conv2D(64, (3, 3), input_shape=(1, 28, 28), activation='relu')) model.add(Conv2D(32, (3, 3), activation='relu')) model.add(Flatten()) model.add(Dense(num_classes, activation='softmax'))
Dernière étape dans la déclaration de notre modèle : il faut le compiler via « model.compile » en précisant les informations suivantes, intrinsèques au réseau de neurones convolutifs…
- le loss : c’est une fonction qui va servir à mesurer l’écart entre les prédictions de notre IA et les résultats attendus. Elle évalue donc la justesse du CNN et permet de mieux l’adapter aux données si besoin ! Nous allons utiliser « categorical_crossentropy » comme loss, car on a des données de type « catégories » en sortie de l’algorithme.
- l’optimizer : c’est un algorithme qui va dicter comment mettre à jour le CNN pour diminuer le loss, et avoir donc de meilleures prédictions. Ici on s’appuiera sur « adam » (adaptive moment estimation), très souvent utilisé.
- la metrics : c’est exactement comme le loss, sauf que la metrics n’est PAS utilisée par le CNN, à l’inverse du loss qui sert pour la mise à jour des variables du CNN via l’optimizer. On utilisera cette fois « accuracy », sans que cela ait de réelle importance pour nous.
Au final, en encapsulant le code dans une méthode, vous devriez avoir ceci :
# define the small model
def small_model():
# create model
model = Sequential()
model.add(Conv2D(64, (3, 3), input_shape=(1, 28, 28), activation='relu'))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(Flatten())
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
ATTENTION : lorsque vous chargez un modèle Keras déjà entraîné, il faut impérativement le compiler pour qu’il soit utilisable !
e) L’entraînement et l’évaluation du Small CNN
Félicitations, vous avez créé votre modèle de bout en bout ! Il ne nous reste plus qu’à lancer l’entraînement !
Commençons par le créer grâce à la méthode précédente :
# build the model model = small_model()
Pour entraîner un modèle, il suffit d’appeler la méthode fit qui prend en arguments :
- Les données d’apprentissage, ici X_train
- Les prédictions attendues d’apprentissage, ici y_train
- Le paramètre validation_data : un vecteur qui contient les données d’entrées à tester et les valeurs à prédire, ici (X_test , y_test)
- Le nombre d’itérations de l’entraînement, c’est-à-dire le nombre de fois qu’il va répéter l’entraînement complet (prédire les 60 000 images), via epochs. Je vous propose de mettre 10 (nombre empirique à déterminer en testant : le « loss » ne diminue plus significativement après la 9ème itération, mais on pourrait continuer)
- Et enfin le paramètre batch_size, qui est le nombre de données d’entrées à analyser « à la suite avant de mettre à jour le CNN », qui vaudra 200 (valeur standard). L’intérêt est que mettre à jour son CNN après chaque image demande du temps et a tendance à nous éloigner de la solution générale optimale (je rappelle qu’on veut un CNN capable d’identifier n’importe quel chiffre dessiné, pas seulement ceux de l’entraînement). En indiquant 200, on s’assure que le réseau ne se spécialise « pas trop »
Ce qui donne le code suivant :
# Fit the model model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200)
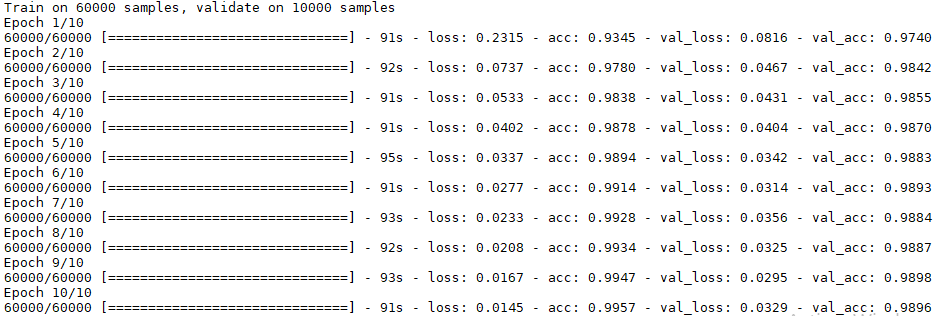
A l’exécution, vous devriez obtenir un résultat similaire à celui-ci (j’utilise mon CPU et non le GPU car je suis sur un ordinateur portable sans carte graphique compatible) :

Il ne nous reste plus qu’à évaluer notre modèle, grâce à la commande (si vous avez récupéré notre projet GitHub) :
# Evaluate the model cu.print_model_error_rate(model, X_test, y_test)
Si vous n’avez pas le fichier cnnutils, voici l’implémentation de la méthode :
# Evaluate a model using data and expected predictions
def print_model_error_rate(model, X_test, y_test):
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Model score : %.2f%%" % (scores[1]*100))
print("Model error rate : %.2f%%" % (100-scores[1]*100))
« evaluate » permet d’évaluer un modèle comme son nom l’indique (plusieurs informations sont remontées par Keras). Pour avoir le taux d’erreur, il suffit de prendre 100% – le taux de succès (scores[1]).
Vous devriez obtenir : 1.39%.
f) Le « medium CNN »
Grâce à notre découpage du code, il va être très rapide de changer l’architecture de notre CNN. A vrai dire, la seule chose que nous allons changer est… le contenu de la méthode small_model() !
Dupliquez le fichier small-cnn-tutorial-keras.py.
Renommez small_model en medium_model puis changeons ensemble la structure du CNN.
Pour rappel, notre objectif est d’avoir :
- Une convolution de 32 filtres en 5×5 avec un ReLU en sortie (n’oubliez pas le paramètre input_shape)
- Un max-pooling de 2×2
- Un dropout de 0.2
- Un flatten
- Un dense à 128 sorties avec un ReLU
- Un dense final à 10 sorties avec un softmax
Par rapport au small CNN, il vous manque le max-pooling et le dropout pour tout coder.
Le max-pooling est ajouté grâce à MaxPooling2D, comme vous vous en doutez, qui prend en paramètre les dimensions du pooling (2,2) dans le paramètre pool_size.
Le dropout pour sa part est ajouté via Dropout, qui reçoit directement le taux de dropout (i.e. 0.2). Cela signifie que 20% des neurones seront ignorés, comme expliqué précédemment.
Voici le code final de la méthode créant le medium CNN :
# define the medium model
def medium_model():
# create model
model = Sequential()
model.add(Conv2D(32, (5, 5), input_shape=(1, 28, 28), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
Le reste du code étant identique, vous pouvez lancer l’entraînement du réseau et arriver au résultat suivant :
Et en évaluant le modèle, vous trouvez un error rate de : 1.03%.
g) Le « large CNN »
Pour le large CNN, on va dupliquer le medium CNN et changer la méthode medium_cnn en large_cnn. Voici l’architecture cible, pour laquelle vous avez toutes les billes à disposition !
- Une convolution de 30 filtres en 5×5 avec une activation ReLU (n’oubliez pas l’input_shape)
- Un max-pooling de 2×2
- Une convolution de 15 filtres en 3×3 avec ReLU
- Un dropout de 0.2
- Un flatten
- Un dense de 128 sorties avec ReLU
- Un dense de 50 sorties avec ReLU
- Un dense de 10 sorties avec softmax
Voici le code complet de la méthode :
# define the larger model
def large_model():
# create model
model = Sequential()
model.add(Conv2D(30, (5, 5), input_shape=(1, 28, 28), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(15, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
Après entraînement, vous devriez obtenir :
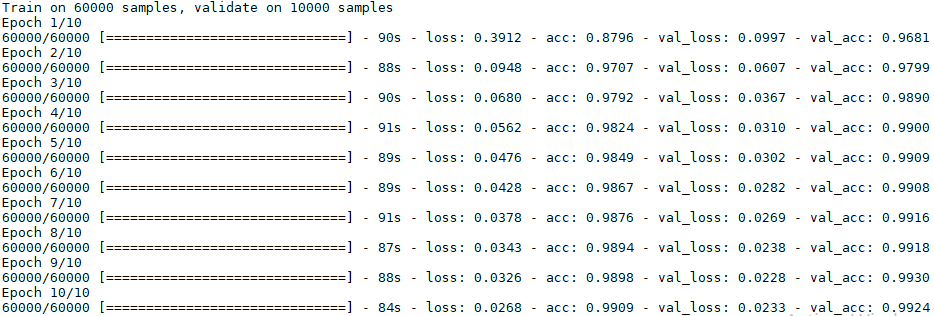
Soit un taux d’erreur de : 0.82%.
h) Bonus : la sauvegarde et le chargement de vos modèles Keras
Dernière petite partie bonus qui porte sur la sauvegarde et le chargement des modèles Keras, car c’est une opération que l’on a tendance à négliger mais qui peut coûter cher (en temps) si on l’oublie !
Pour la sauvegarde, il suffit d’utiliser la fonction « to_json » des modèles de Keras qui permet de réaliser l’export du modèle (l’architecture), à placer dans un fichier json. Il faut également appeler « save_weights » qui sauvera les paramètres du réseau (donc tout ce qui vient avec son entraînement) en h5. En aucun cas il faudra oublier l’un ou l’autre des fichiers, sinon vous devrez soit réécrire l’architecture du modèle, avec les convolutions, etc… (si vous perdez le json) soit ré-entraîner tout le CNN.
Voici la fonction de sauvegarde :
# This function saves a model on the drive using two files : a json and an h5
def save_keras_model(model, filename):
# serialize model to JSON
model_json = model.to_json()
with open(filename+".json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights(filename+".h5")
Concernant le chargement, on a besoin d’un import de Keras :
from keras.models import model_from_json
Ensuite, il faudra lire le json pour charger l’architecture du modèle de CNN puis lire le h5 pour mettre à jour les variables du CNN et récupérer son entraînement :
# This function loads a model from two files : a json and a h5
# BE CAREFUL : the model NEEDS TO BE COMPILED before any use !
def load_keras_model(filename):
# load json and create model
json_file = open(filename+".json", 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
# load weights into new model
loaded_model.load_weights(filename+".h5")
return loaded_model
On rappelle que pour que le modèle soit utilisable, il ne reste plus qu’à le compiler grâce à la commande :
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
Conclusion finale
Dans la partie théorique, nous avons vu en détail comment fonctionne un réseau de neurones convolutifs. En particulier, on a pu comprendre ce que faisaient les différents éléments de l’architecture (convolutions, pooling, relu, flattening, dense…) et découvrir de vrais réseaux utilisés en production (ConvNet et VGG notamment).
Dans la partie TP, on a pu mettre en place trois réseaux de neurones convolutifs avec des architectures différentes et on en a comparé les résultats.
N’hésitez pas à nous faire part de vos retours sur ce TP en commentaire ou sur notre page Facebook (@penseeartificielle) / Twitter (@PenseeArtif) !
Crédit de l’image de couverture : Lambert Rosique



 !){kind=link}