Si on a vu en détail le Machine Learning dans le précédent article, aujourd’hui nous allons nous intéresser au Deep Learning : une famille d’algorithmes plus complexes mais d’autant plus autonomes dans leur apprentissage (et aux applications plus vastes).
De la prédiction toute simple à l’analyse d’images, à la synthèse de texte ou l’étude de séries temporelles il n’y a qu’un pas, faisons en sorte qu’il ne soit pas trop « géant » avec cet article !
Remarque : la série est divisée en plusieurs articles :
Tutoriel 1 = sur l’IA en général et les choix techniques (langage, framework…)
Tutoriel 2 = sur les notions transverses (la donnée, les lois, la data science, hadoop…)
Tutoriel 3 = sur comment se former à l’IA, comment valoriser son savoir et surtout comment se démarquer en restant pro-actif !
Tutoriel 4 = sur le machine learning, avec tous ses algorithmes principaux en exemple : k-means, random forest, SVM…
Tutoriel 5 (ici) = sur le deep learning en détail (avec son utilisation) : réseaux de neurones artificiels, convolutifs, récurrents, etc…
Tutoriel 6 (à venir) = des grandes questions que l’on se pose sur l’IA, avec des pistes de réflexion et mon avis personnel ouvert au débat 🙂
V. Le Deep Learning, monument de l’IA
Les différents algorithmes pour bien débuter en deep learning
Il n’est pas aisé de définir exactement ce qu’est le deep learning aujourd’hui (un peu comme l’IA), mais généralement un algorithme qui repose sur l’utilisation de neurones artificiels ou de couches en fait partie. Quelle vision d’ensemble peut-on en définir ?
- On a tout d’abord les réseaux de neurones artificiels, qui sont simples et efficaces.
Ils constituent un très bon point d’entrée dans la logique « en couches » du deep learning, et trouvent des applications dans toutes sortes de prédictions à base de nombres.
- Ensuite on a les réseaux spécialisés dans l’analyse d’image : les convolutifs.
Leur rôle est de pouvoir extraire de l’information cachée dans les images pour en tirer des conclusions, par exemple reconnaître les caractéristiques d’un chat. A noter que cette approche « image » est aussi utilisée dans l’analyse de sons ou de textes que l’on met sous la forme de « photographies ».
- Parce qu’ils utilisent souvent des réseaux de neurones convolutifs MAIS que leur intérêt est de pouvoir générer tout ce qu’on veut, les GAN seront la pierre suivante que nous poserons dans notre approche du Deep Learning.
Que vous vouliez générer des oeuvres d’art, des romans, des jeux de données pour entraîner d’autres IA, les GAN sont faits pour vous !
- Lorsque l’on monte encore d’un niveau de complexité, on trouve les neurones récurrents qui sont capables de garder en mémoire des informations.
Action -> Réaction. Un principe qui régit notre vie chaque jour, et que l’on se devait d’intégrer dans l’IA pour qu’elle puisse mieux saisir les tenants et les aboutissants d’un problème.
- Enfin, même s’il ne s’agit pas à proprement de deep learning mais d’une technique d’apprentissage (que l’on peut donc appliquer pour n’importe quoi), l’apprentissage par renforcement permet d’aborder des problématiques plus larges (et en même temps plus spécialisées).
En particulier, tout ce qui est d’apprendre à jouer à un jeu vidéo ou à se déplacer dans un labyrinthe sera abordé sous cet angle.
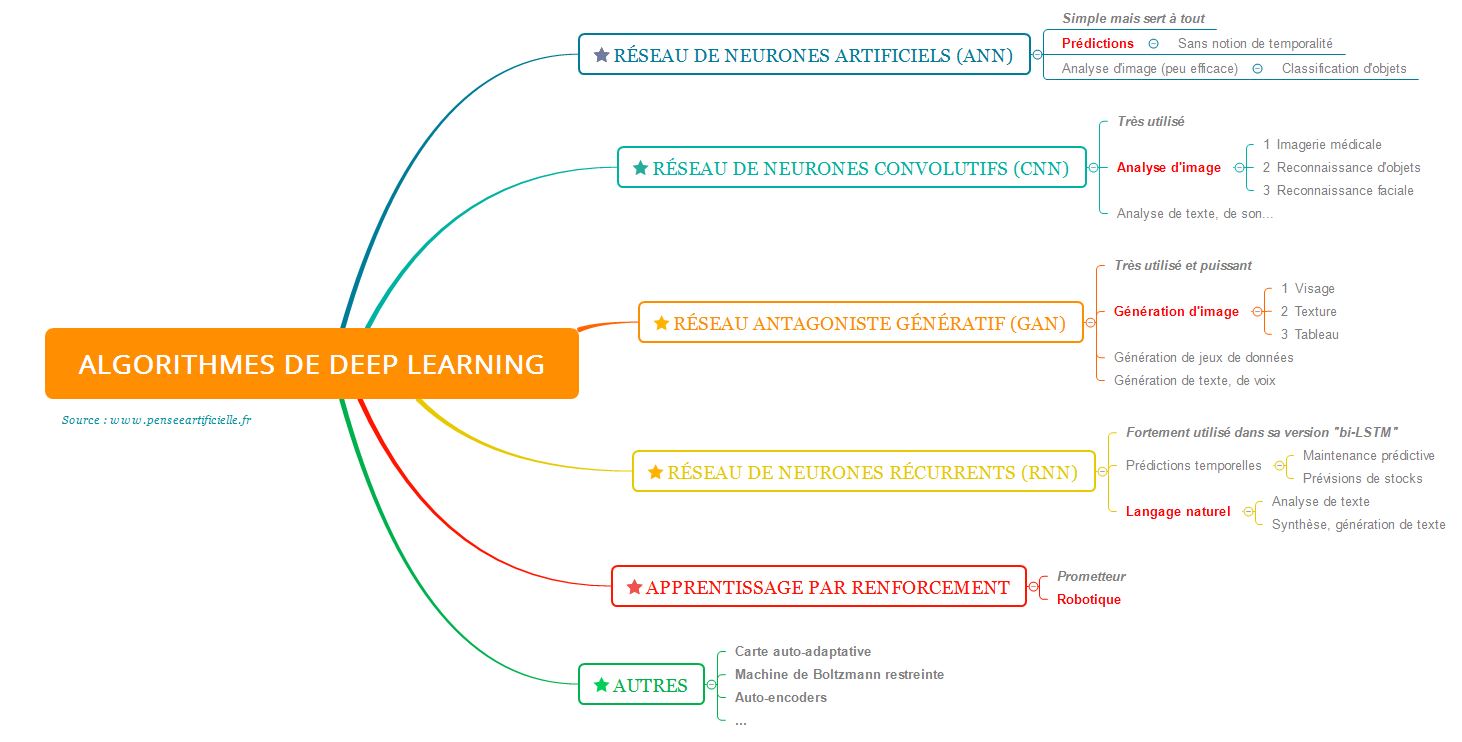
Fin des présentations, rentrons un peu plus dans les spécificités de chacun de ces algorithmes
Explications sur le réseau de neurones artificiels
On ne présente plus le réseau de neurones artificiels sur internet tant il y a de tutoriels. Vous devez probablement en avoir entendu parler sous l’un de ces noms :
- réseau de neurones artificiels (ANN en anglais pour Artificial Neural Network)
- réseau dense (Dense en anglais et dans beaucoup de librairies de deep learning)
- perceptron ou perceptron multi-couches (MLP en anglais pour Multi-Layer Perceptron), un peu plus précis que les autres mots car cela désigne un système particulier
- fully-connected (FC en anglais)
- réseau de neurones profonds (DNN en anglais pour Deep Neural Network)
- feed forward ou deep feed forward (FF et DFF en anglais, termes que je n’ai personnellement jamais utilisé ni trop vu)
Le terme le plus général dans tout ça est ANN (et DNN qui est équivalent). Les autres sont également des ANN, à ceci près qu’ils n’ont pas forcément de couches cachées (ou au contraire qu’ils en ont forcément). C’est vraiment la seule différence, et en général on utilise tous ces termes de la même manière en précisant l’architecture de l’algorithme…
Mais d’ailleurs, qu’est-ce que l’architecture de l’ANN ?
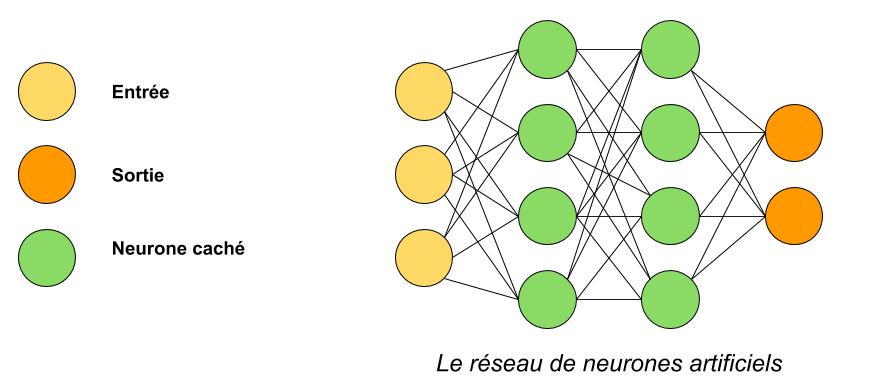
Un réseau de neurones artificiels est toujours organisé ainsi :
- Un certain nombre de neurones d’entrée, par exemple l’un qui recevra la superficie d’un appartement, l’autre le code postal, l’autre le nombre de pièces, etc…
- Un certain nombre de couches cachées : une couche cachée c’est simplement une colonne verte dans le schéma.
On voit que des neurones d’une même couche cachée ne sont pas reliés entre eux mais sont en parallèle ! Augmenter le nombre de couches cachées, c’est donc augmenter la complexité de notre algorithme (au risque de perdre en généralité mais on va revenir dessus).
- Un certain nombre de neurones cachés par couche cachée, sachant qu’il n’a pas à être le même partout.
- Un certain nombre de neurones de sortie, qui correspondent aux prédictions que l’on veut. Par exemple pour le prix d’un appartement, il n’y aura qu’un neurone (le prix), mais pour dire si on a en entrée les caractéristiques d’un chien ou d’un chat, on aura 2 sorties (la probabilité de chien et la probabilité de chat, chacune dans un neurone différent).
Comment est-ce que ça marche ?
Le but de cette partie 5 n’est clairement pas d’entrer dans les détails techniques, mais de donner une idée globale. Ici pour l’ANN, ce qu’il faut vraiment retenir c’est que chaque neurone va recevoir un signal par neurone de la couche d’avant, plus ou moins atténué (on parle de poids de la liaison), et qu’il va juste tout ajouter avant d’envoyer son résultat aux neurones suivants ! Ce résultat passe par une fonction d’activation avant de sortir : c’est une fonction mathématique simple dont le rôle est juste d’éviter que les résultats ne deviennent trop grands (elle va donc les ramener entre -1 et 1).
Pour plus de détails sur le fonctionnement de l’ANN, je vous invite à lire notre article sur le perceptron multi-couches.
Comment est-ce que l’ANN apprend ?
En regardant des données d’entrée et leur sortie, le réseau modifie les poids entre les neurones pour que le résultat final soit égal à la sortie attendue pour l’entrée donnée.
Explications sur le réseau de neurones convolutifs
Les réseaux convolutifs ou réseaux de neurones convolutifs (CNN : convolutional neural network en anglais), à ne pas appeler réseaux de neurones convolutionnels (mauvaise traduction) viennent d’une opération mathématique que l’on appelle la « convolution ».
Plus compliqué que l’ANN que nous venons de voir, le CNN reste simple quand on prend le temps de bien le connaître !
Quelle en est l’architecture ?
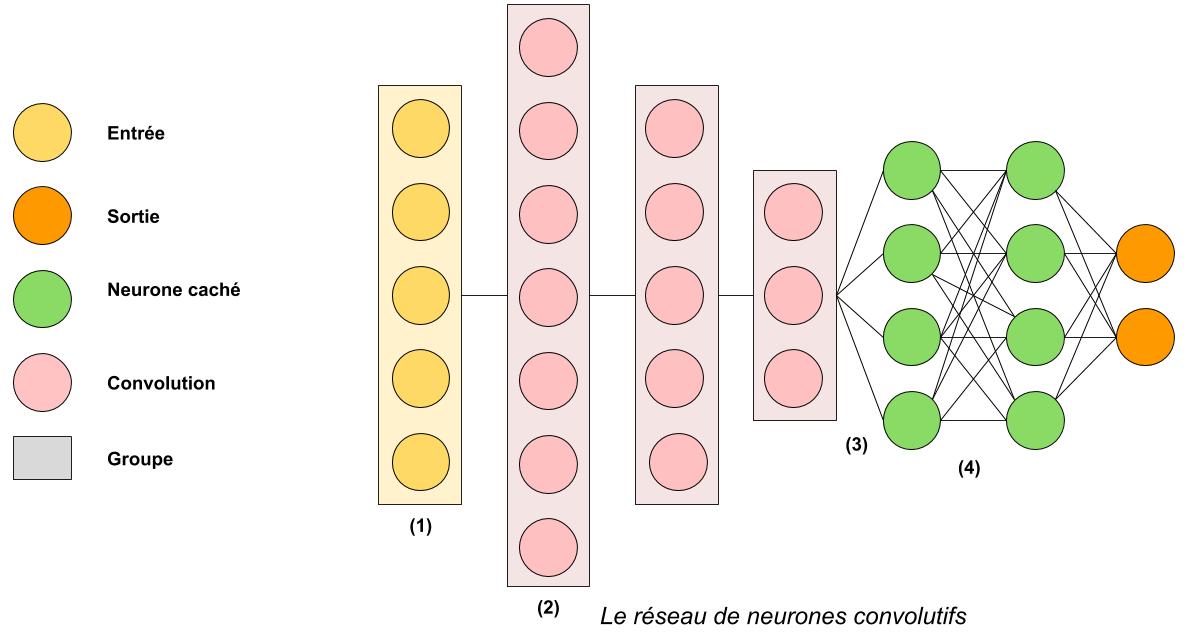
A la grande différence de l’ANN, ici on ne va pas traiter chaque sortie « indépendamment » des autres mais on va essayer de garder en tête la notion d’image.
(1) : pour simplifier l’explication, considérons que l’entrée du réseau soit une image. On aura donc dans chaque neurone d’entrée la valeur d’un pixel, et c’est l’ensemble des pixels qui est envoyé à la couche suivante (et pas chaque pixel séparément comme dans l’ANN, même s’ils interagissent encore ensuite par le biais de l’addition des valeurs)
(2) : notre ensemble de pixels arrive dans la première couche de convolution, composée de neurones convolutifs. Un neurone convolutif est un filtre au sens de Photoshop par exemple : lorsqu’on l’applique à une image, il va la déformer, en faire ressortir les arêtes, la flouter, la nettifier, la retourner, etc… ! La première couche de convolution est donc un ensemble de filtres que l’on va appliquer séparément à l’image qui arrive pour former un ensemble d’images filtrées.
Ces images filtrées sont envoyées à la couche de convolution suivante, qui va à son tour appliquer un certain nombre de filtres en parallèle sur ces images filtrées, puis envoyer le nouveau lot d’images à la couche suivante.
Remarque très importante mais technique : une convolution de la deuxième couche, appliquée aux (par exemple) 64 images filtrées qui arrivent de la couche précédente ne donnera qu’une seule image filtrée et non 64 images… Pour plus de détails, n’hésitez pas à consulter notre tutoriel sur le réseau de neurones convolutifs ou son TP !
A noter, comme pour la « fonction d’activation » dans l’ANN dont je n’avais pas voulu parler, il y a pour l’ANN ce que l’on appelle une « normalisation », un « relu » et un « pooling » qui peuvent intervenir à divers endroits du réseau. Grosso modo, leur rôle est de simplifier les images pour éviter que les traitements ne soient trop longs.
(3) : après la dernière convolution, le lot d’images filtrées final est mis à plat : chaque pixel de chaque image va venir dans un réseau de neurones artificiels (ANN) qui est collé au CNN. Si on a par exemple 10 images de 5×5 pixels à la fin des convolutions, alors on enverra tous ces pixels à la suite dans un ANN qui a 10x5x5 = 250 neurones d’entrée.
(4) : c’est un ANN classique, sans couche cachée. On peut en enchaîner plusieurs (2 ou 3 souvent) pour de meilleurs résultats, la sortie finale étant toujours les prédictions (par exemple est-ce que la photo est celle d’un chien ou d’un chat).
Pourquoi diviser le CNN en deux parties ?
- La partie avec les convolutions (i.e. avec les filtres) sert à analyser l’image. Les premières convolutions vont mettre en avant les textures de l’image (s’il y a des lignes horizontales, etc…) tandis que les dernières convolutions (filtres de filtres de filtres de filtres) vont découvrir plus facilement des formes complexes (une roue, un museau, etc…), car un museau est composé de lignes horizontales (poils), d’une forme triangulaire avec deux fentes (narines), etc… C’est la partie analytique du CNN.
- La partie avec les neurones artificiels va récupérer le résultat de tous ces filtres, donc en gros s’il y a beaucoup de lignes horizontales, s’il y a un museau dans l’image, etc… puis en tirer des conclusions comme il sait si bien le faire (i.e. est-ce que l’on a affaire à un chien ou à un chat). C’est la partie prédictive du CNN.
Comment est-ce que le CNN apprend ?
Les filtres sont des matrices de petite taille que l’on applique à l’image via le « produit de convolution » (outil mathématique dont je parlais au début et qui donne le nom au réseau). Les valeurs de ces matrices sont modifiées pour que les filtres soient plus efficace sur les données d’entraînement. Par exemple, si le réseau analyse beaucoup de chats et de chiens, il n’y aura probablement aucun filtre qui trouvera des roues dans l’image, par contre il y en aura pour différencier les oreilles pointues (chats) des oreilles tombantes (chiens).
La partie prédictive (ANN) apprend grâce à ses poids, de manière classique.
Explications sur les GAN (Generative Adversarial Network, GANs au pluriel)
Les GANs sont des réseaux en deep learning qui peuvent prendre de très nombreuses formes (architectures) ainsi qu’utiliser différents types de neurones, en fonction de l’utilisation que l’on veut en faire. Impossible de débuter en deep learning sans les connaître, car tout le monde en parle !
Vous les trouverez notamment :
- dans les images (par exemple le fameux tableau d’Edmond de Belami), les vidéos (deep fakes)
- dans les IA de jeux vidéos : que ce soit pour générer des textures ou avoir des agents (des « bots ») intelligents
- dans la générations de jeux de données : récemment, un GAN a permis d’entraîner une IA à résoudre un problème de classification de chiffres manuscrits avec seulement 10 images par classe, au lieu des 15 000 utilisées habituellement !
Quel en est le principe général ?
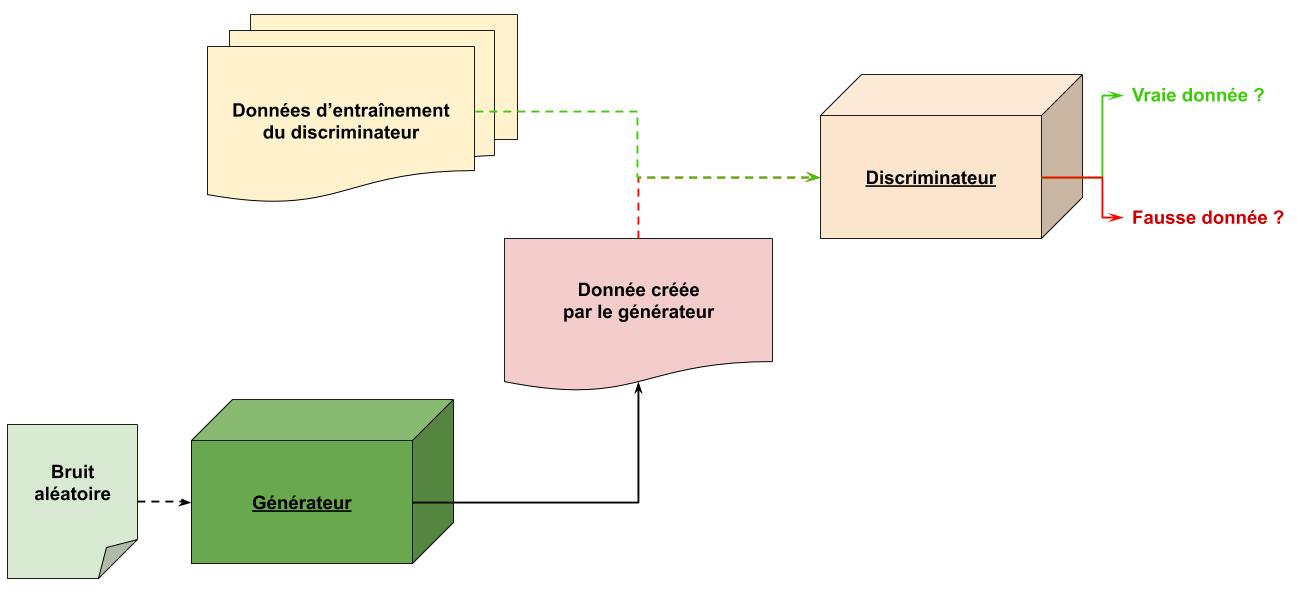
Les GAN reposent sur la notion de compétition et sur l’utilisation de 2 IA distinctes :
- le Générateur (generator G en anglais) est l’IA qui, à partir de « rien » (un vecteur aléatoire, une image de bruit, etc…) va créer une donnée, par exemple une nouvelle image ou bien un exemple d’appartement
- le Discriminateur (discriminator D en anglais) est l’IA dont le rôle est opposé : il va devoir déterminer quelles données parmi toutes celles qu’il reçoit sont « fausses » i.e. ont été glissées par le Générateur dans le jeu de données réelles
Pour être plus concret, imaginons que l’on souhaite créer des visages virtuels à l’aide d’un GAN.
- Tout d’abord, le générateur (peu entraîné pour l’instant) va créer un premier visage qui sera très mauvais
- Le discriminateur va recevoir des visages tirés de vraies photos et le faux visage, puis va indiquer, selon lui, lesquels sont vrais et lesquels sont faux. Puisque les faux ont été générés par le générateur, on peut, à la fin, dire au discriminateur « tu t’es trompé ici et là » : il apprend de cette manière
- Ensuite on revient vers le générateur et on peut lui dire « cette image et cette image ne sont pas passées, par contre celle-ci a trompé le discriminateur » : il va donc essayer de se rapprocher des images qui sont passées et de s’éloigner de celles qui ont été détectées comme fausses !
- On répète ce processus un grand nombre de fois, le générateur et le discriminateur s’améliorant à chaque itération, jusqu’à obtenir deux réseaux :
- un premier réseau capable de créer des visages très réalistes, indiscernables de vrais visages
- un second réseau qui reconnait bien les visages générés par une IA et donc non réels.
De cette manière, on peut créer des IA qui vont lutter contre les Deep Fake ou à l’inverse créer des Deep Fake (comme la vidéo de Barack Obama qui prononce un discours différent dans la vidéo d’origine et dans la version modifiée, sans que l’on puisse voir que le texte n’est pas l’original).
Allons plus loin brièvement
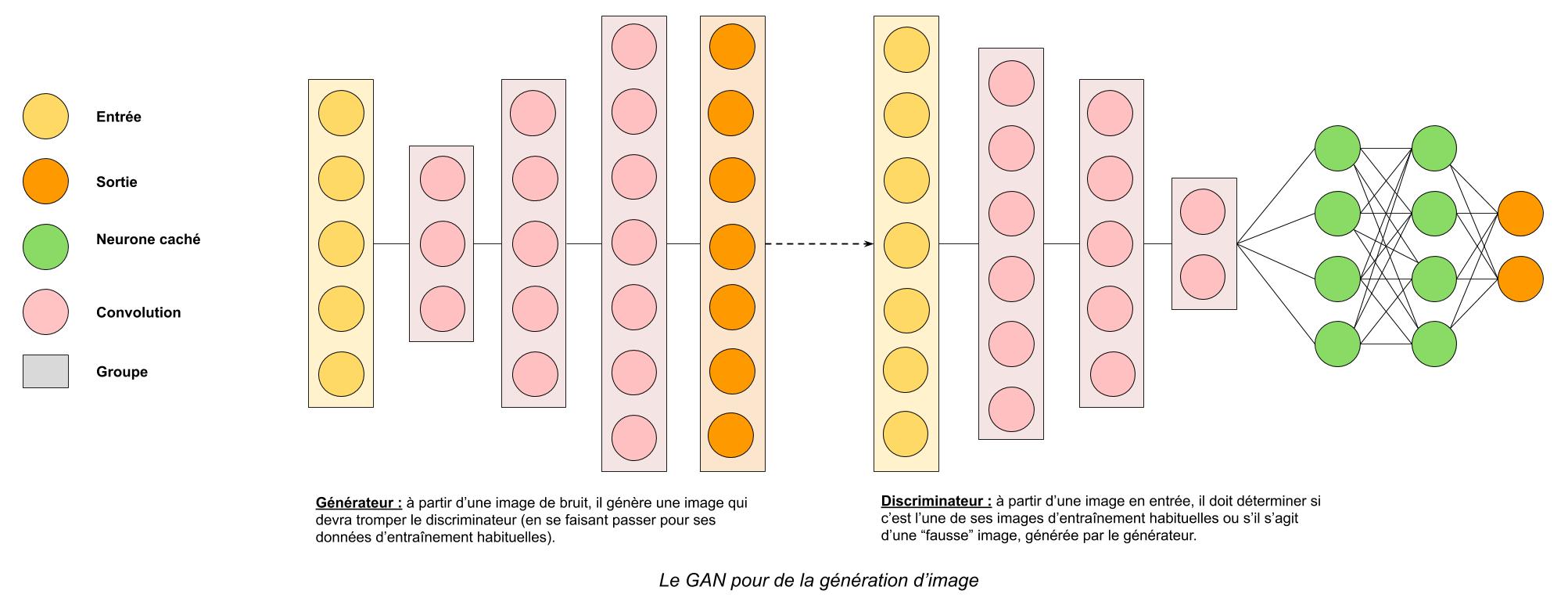
Ici nous avons un GAN spécialisé dans la génération d’images, parce que son générateur et son discriminateur utilisent des neurones convolutifs. Quelle différence cela fait-il, me direz-vous ?
En fait, grâce aux convolutions, le discriminateur est capable de repérer des éléments de l’image qui vont lui servir à juger. Par exemple pour la génération de visage, s’il n’y a pas d’yeux ou de nez dans l’image générée, il pourra conclure très rapidement que c’est une fausse image (les neurones convolutifs sont les plus adaptés à ce type d’analyse).
Mais il y en a aussi dans le générateur, car il doit comprendre un minimum comment fonctionne le discriminateur s’il veut espérer le tromper… Donc grâce à ses « convolutions inversées » (une convolution diminue la taille d’une image, on a une perte d’information, tandis que là on veut ajouter de l’information, en créer), le générateur est capable d’injecter un nez et des yeux dans l’image qu’il crée !
A noter, en toute logique, que vous pouvez donc avoir des GANs qui reposent sur des neurones artificiels plutôt que des convolutions, ou même d’autres types de GANs dont le générateur et le discriminateur interagissent différemment du schéma précédent (dit traditionnel) ! Chaque GAN a alors son petit nom, mais porte très souvent les lettres « GAN » dedans, donc vous les repérerez facilement !
Explications sur le réseau de neurones récurrents (et les LSTM)
Pour terminer avec les principaux types d’algorithmes de Deep Learning, on va parler des réseaux de neurones récurrents (RNN) même si au final ils sont très peu utilisés aujourd’hui : on préfère très largement les LSTM (voire les bi-LSTM) ! Mais comme nous allons le voir, la différence est subtile et n’aura pas d’impact dans cet article.
Le principe général est qu’un RNN pour réaliser sa prédiction va utiliser les informations de la prédiction précédente (une partie seulement).
Quelle est l’architecture du RNN ?
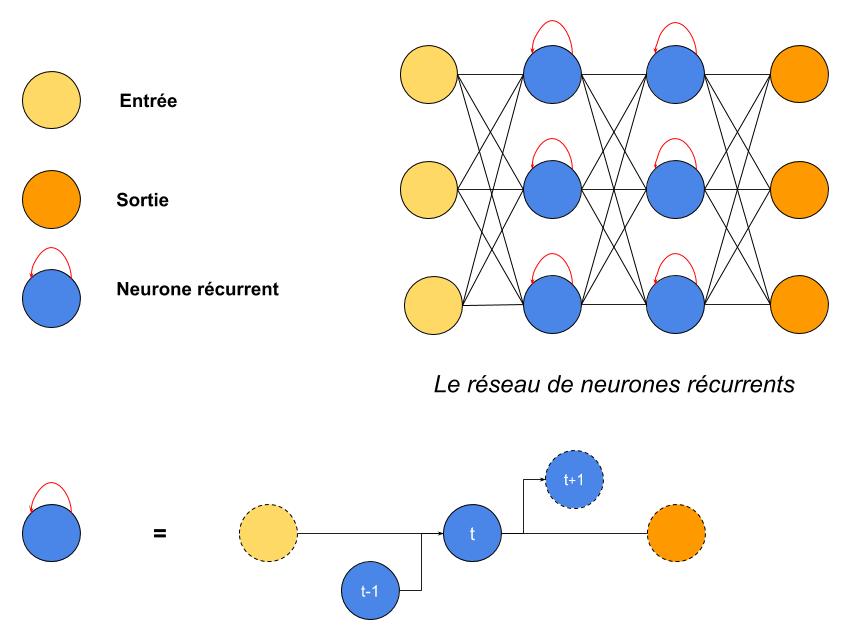
Comme pour le réseau de neurones artificiels, on a des entrées et des sorties, avec au milieu des neurones « récurrents ».
Il y a cependant un gros piège dans cette représentation : chaque neurone récurrent est, en gros, un neurone artificiel (il réalise des sommes de ce qui entre pour aboutir à une sortie), avec la flèche de récurrence rouge au-dessus qui signifie
- Lorsque l’on considère le RNN pour la t-ième donnée (on parle aussi d’instant t, car c’est souvent la donnée temporelle qui suit la donnée t-1), l’entrée d’un neurone récurrent est la sortie de la couche précédente (comme pour le réseau de neurones artificiels) ET la sortie de ce neurone pour la donnée précédente !
- Par exemple, si le premier neurone bleu en haut à gauche du schéma reçoit à t=0 une « valeur totale » (je vous épargne les calculs et on simplifie) de 0.8 et qu’il renvoie alors aux neurones suivants la valeur 0.4, alors à t=1 il recevra (à cause des données d’apprentissage) par exemple la valeur 0.7 ainsi que la valeur 0.4 (i.e. ce qu’il a renvoyé à t=0 : c’est sa mémoire du résultat précédent) et renverra 0.1. Puis à t=2, il aura oublié ce 0.4 mais se souviendra toujours avoir renvoyé un 0.1, qui rentrera en même temps que la valeur d’entrée du réseau pour les données t=2.
A noter que la mémoire d’un neurone dépend de la configuration du réseau. Dans le schéma ci-dessus, le neurone ne se souvient que « d’une itération avant », mais il est tout à fait possible de se souvenir des 2, 3, 4… dernières valeurs renvoyées par le neurone, et ce, pour chaque neurone !
Et les LSTM ou les bi-LSTM ?
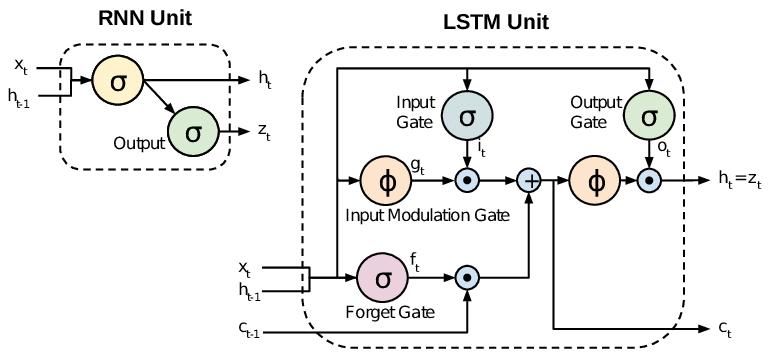
LSTM signifie Long Short-Term Memory, et bi-LSTM est l’abréviation de « bidirectionnal LSTM ». Ils ne sont pas l’idéal pour débuter en deep learning, mais mieux vaut en avoir entendu parler…
Si un neurone d’un RNN va travailler comme un neurone artificiel (en faisant plus ou moins la somme des valeurs d’entrée qu’il reçoit), un LSTM va avoir un fonctionnement beaucoup plus complexe mais, dans l’idée, similaire.
Ainsi, comme on le voit sur le schéma, tout neurone récurrent dans un LSTM (appelé neurone mémoire) a trois portes distinctes :
- La porte d’entrée (input gate)
- La porte de sortie (output gate)
- La porte d’oubli (forget gate)
On ne va pas en décrire le fonctionnement, car ce sera l’objet d’un autre tutoriel sur Pensée Artificielle, mais retenez qu’un LSTM, grâce à tous les traitements plus poussés qu’il peut faire sur les données d’entrées réelles VS les données en mémoire, a la capacité de réaliser de grandes choses, surtout en traitement du langage naturel !
Remarque : d’autres types de RNN comme les GRU (Gated Recurrent Unit n’ont pas de porte de sortie mais sont, sans ça, des LSTM).
Remarque : un bi-LSTM, encore plus compliqué qu’un LSTM, peut (pour l’instant) être vu comme un double réseau LSTM dont la première version va de gauche à droite et la seconde version de droite à gauche.
Un modèle d’attention ?
Un concept récurrent dans les RNN, sans jeu de mots, est celui du modèle d’attention. Vous le retrouverez mis en oeuvre dans les algorithmes de deep learning de bi-LSTM les plus performants à l’heure actuelle comme par exemple avec BERT de Google (Bidirectional Encoder Representations from Transformers), même si d’autres approches n’utilisant pas forcément les bi-LSTM sont envisagées (cf MT-DNN de Microsoft qui a de meilleurs résultats).
Explications sur l’apprentissage par renforcement
Il ne s’agit pas d’algorithme de Deep Learning à proprement parler, mais je trouvais qu’ils étaient extrêmement importants à l’heure actuelle et liés à cette partie.
Le grand principe de l’apprentissage par renforcement est de laisser à un agent, par exemple un petit robot, le loisir d’explorer son environnement – mettons un labyrinthe – et, lorsqu’il trouve la sortie, de valoriser les actions qui l’ont conduit ici.
Si vous avez compris cet exemple, alors vous avez tout compris !
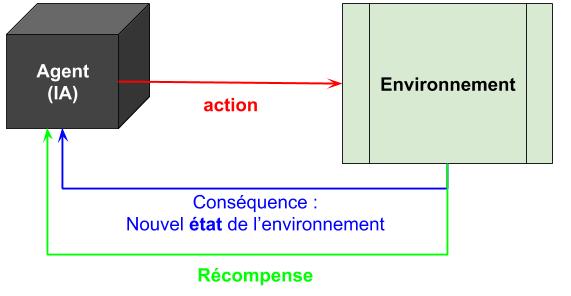
L’apprentissage par renforcement c’est que pour chaque état de l’environnement, l’agent est capable d’évaluer les conséquences de l’action qu’il choisit (i.e. quel sera le nouvel état), et réalise donc l’action dont la récompense est la plus élevée.
Pour notre labyrinthe, le robot va se déplacer aléatoirement au début, et aura une récompense négative (car il n’aura pas trouvé la sortie et son énergie est limitée et diminue, ce qui va le motiver à sortir). Au bout d’un moment, un choix lui permettra de sortir et lui donnera une récompense positive, qui viendra renforcer les derniers choix qu’il a fait de manière dégressive (par exemple, la dernière action aura une récompense de 1, celle d’avant de 0.8, celle encore avant 0.5 et voilà).
Après plusieurs itérations, quand le robot se retrouvera à 3 cases de la sortie du labyrinthe, il regardera sa politique d’action et verra que depuis cette case, le plus intéressant (i.e. ce qui apporte la plus grande récompense) est de tourner à droite plutôt qu’à gauche car, d’expérience, ça nous rapproche de la sortie !
Et après encore plus d’itérations, il sera capable de trouver la sortie tout seul. Si on ajoute des événements aléatoires lors de l’apprentissage, il pourra même se débrouiller (par exemple si la présence d’eau sur sa route le retarde, il l’évitera lorsqu’il en rencontrera).
Qu’apporte cette approche ?
- on n’a pas besoin de coder les règles métier ou quoi que ce soit, l’IA va les découvrir d’elle-même
- on peut donc s’adapter à toutes les situations peu importe les entrants (pas besoin d’être exhaustif, il y a une part de « généralisation »)
- un tel système peut également évoluer dans le temps, par exemple pour du SPAM leur structure change en fonction des mesures déployées pour l’arrêter, ou alors pour le labyrinthe on peut imaginer des versions de plus en plus complexes
- et enfin, on évite la partie « compréhension du problème »
Pour ce dernier point, à titre d’exemple, imaginons que je veuille créer un robot qui marche. Je pourrai programmer chacun de ses moteurs pour qu’il ait le bon mouvement, qu’en cas de chute il puisse se relever, etc… mais ce serait extrêmement laborieux et difficile.
Ou alors, je peux créer un environnement virtuel de simulation, placer mon modèle de robot dedans et le laisser apprendre à se lever et marcher grâce à un apprentissage par renforcement. Après des dizaines de milliers de tentatives, il sera en mesure de le faire, et peu importe comment il tombe, il saura se relever !
Analyse d’image : comment passer au mobile ou à l’embarqué ?
Il existe trois manières distinctes d’aborder le mobile/l’embarqué :
- faire des réseaux plus simples, quitte à perdre (beaucoup) en efficacité des algorithmes
- utiliser un framework adapté, comme Tensorflow Mobile ou Tensorflow Lite, ou se limiter à du Machine Learning ou à des algorithmes adaptés comme YOLO ou MobileNet SSD (pour la détection d’objets)
- utiliser une clé usb movidius d’Intel branchée à une Raspberry Pi 3B+ ou 4, pour avoir de très hautes performances dans un mini-boitier
- ou alors s’appuyer sur un Jetson Nano (principe équivalent) de Nvidia
La difficulté de travailler sur le langage (analyse de texte, de voix…)
Pour toutes les personnes qui lisent ces lignes et veulent se lancer dans le traitement du langage, sachez qu’il s’agit d’un domaine compliqué (en français) pour plusieurs raisons.
Tout d’abord, les réseaux utilisés (bi-LSTM essentiellement) demandent beaucoup de données d’apprentissage et sont longs à travailler. Il faut compter plusieurs jours pour parvenir à un résultat.
Ensuite, l’humain est extrêmement exigeant. L’IA oublie ou remplace un seul mot dans une phrase, et on repère directement que ce n’est pas un humain qui a écrit ces lignes.
De la même manière, les enjeux sont critiques : remplacez le mauvais mot au mauvais endroit, et la phrase perd tout son sens… ou pire, elle en prend un autre !
Concernant le « français », il n’y a pas beaucoup d’IA déjà entraînées à travailler avec notre langue, contrairement à l’anglais. Faire du transfert learning pourra donc s’avérer impossible dans certaines situations.
Malheureusement pour nous, la grammaire française (ou l’orthographe) est compliquée et pleine de contre-exemples. Comment s’en prémunir ? En réunissant davantage de données d’apprentissage ! Que chou et genou prenne un « x » au pluriel ne s’invente pas, et ne se déduit pas de quoi que ce soit…
Enfin, les caractères accentués (qui n’existent pas en anglais) posent un problème supplémentaire lors du traitement, car il faudra souvent convertir des documents en utf-8 (on ne pourra pas se limiter à l’alphabet de base) ou en unicode. Je me retrouve ainsi souvent avec des caractères incongrus dans mes textes générés, car à un moment du processus, un fichier a été lu avec le mauvais encodage.
Pour la voix, le principal problème est l’accent de l’enregistrement et donc, en France, le problème sous-jacent est celui de réunir les données d’apprentissage.
Quelques exemples de projets réels
Trouver des exemples réels n’est pas du tout difficile, surtout lorsque l’on va à Viva Technology !
Simulation de maquillage (Adobe, L’Oréal…)
Combiner le monde de la beauté et l’IA ? C’est tout à fait possible grâce aux GANs et aux écrans connectés ! Placez-vous devant un écran avec une caméra, et laissez le GAN entraîné (à appliquer un maquillage sur une vidéo de manière réaliste) faire le travail.
Maintenance prédictive (Orange, l’industrie 4.0 en général)
Prévoir qu’une antenne va tomber en panne ? Qu’une pièce sera défectueuse sur telle chaîne de montage ? Tout à fait réalisable à l’heure actuelle, du moment que vous avez des données de capteurs (vibrations, bruit, tension, à peu près tout marche) et un réseau de neurones artificiels ou récurrents !
Les Deep Fake
Animer la Joconde comme si elle apparaissait dans une vidéo ? Créer un faux journal télévisé ? Faire parler une langue étrangère à n’importe quel acteur en animant sa bouche à la perfection pour cette langue ?
Les GANs, encore une fois, peuvent réaliser toutes ces merveilles… mais attention à ne pas porter atteinte aux personnes (par exemple en manipulant l’opinion publique avec un faux témoignage, dégrader l’image d’une personne, etc…)
Synthétiser des textes
Savoir en une seconde de quoi parle un rapport, ou même un mail, ranger efficacement des documents techniques, synthétiser les informations du jour ou de la semaine… Le traitement du langage naturel a un bel avenir devant lui, grâce aux bi-LSTM (des réseaux récurrents en plus compliqué)
Reconnaissance faciale
Un sujet qui fait débat tant il est puissant mais fait peur (comme les deep fake) : avec seulement un réseau de neurones convolutifs et quelques outils de traitement de l’image, il est facile de créer une IA de reconnaissance faciale ! D’ailleurs, si le sujet vous intéresse, n’hésitez pas à réaliser notre TP dédié.
D’autres notions de l’IA : l’overfitting que l’on voit quand on veut débuter en deep learning !
En vous renseignant sur les différents algorithmes présentés, vous acquerrez beaucoup de vocabulaire. Même si ce n’est pas l’objet de ce tutoriel, il y a au moins une notion qui revient souvent : celle du sur-apprentissage (overfitting).
Pourquoi spécifiquement en Deep Learning ?
Vous l’aurez compris, le deep learning c’est proposer un nombre de couches de neurones et un nombre de neurones par couche, qui permette de traiter efficacement un problème. Globalement, chaque couche de neurones va vous permettre de découper un peu mieux l’espace (c’est un peu comme passer d’un polynôme x² à un polynôme en x³ par exemple).
Dans l’exemple de gauche, la ligne noire correspond à la manière qu’a un réseau disons à 2 couches de séparer l’espace des données, tandis que la courbe verte correspond à celle d’un réseau à 10 couches pour les mêmes données !
En définitive, le réseau « vert » aura parfaitement découpé les données et ne commettra aucune erreur de prédiction, mais il n’aura pas saisi la « tendance » des données et dans les environs des points qui ont passé la ligne noire présentera des résultats très variés. Par exemple pour un appartement à 500€/mois il dira « bon prix », pour 501€/mois il dira « beaucoup trop cher, passez votre chemin » et ensuite pour 502€/mois il dira « c’est quasiment gratuit à ce prix-là », car il aura franchi la ligne verte à 501 avant de revenir !
A noter que l’équilibre est très difficile à trouver (combien de couches, combien de neurones, quels autres paramètres choisir aussi) et demande simplement de l’expérience, du test, et de l’analyse.
Quelques autres mots-clés qu’il vous faudra regarder et comprendre :
- underfitting (opposé d’overfitting) : le réseau n’est pas assez entraîné
- vitesse d’apprentissage (learning rate) : à quel point on autorise le réseau à évoluer lors de l’apprentissage
- batch : lors des phases d’apprentissage, il est judicieux d’envoyer les données par batch avant de procéder à la mise à jour du réseau pour l’améliorer
- transfert learning : partant d’une IA déjà entraînée, on lui apprend d’autres choses pour la spécialiser
- dropout : sujet qui fait débat en ce moment, car un brevet a été déposé sur le concept par Google. Le principe est de jeter une partie aléatoire de l’information circulant dans un réseau pour le forcer à s’adapter
- algorithmes génétiques : on n’en a pas parlé ici, mais ils ont de nouveau le vent en poupe et permettent de plus en plus d’apprendre des problématiques complexes
- ainsi que tous les mots qui concernent votre champ d’étude, par exemple si vous travaillez sur de la classification d’image il y aura les notions de type « channels, pooling, kernels, etc… », si vous êtes dans l’analyse sémantique il y aura « nlp (natural language processing), modèle d’attention, stemmatisation, lemmatisation, etc… »
Le cas des chatbots et le transfert learning
Ne voulant pas m’étendre sur les chatbots, j’ai quand même choisi de leur accorder un paragraphe car ils témoignent de la double approche possible dans le deep learning :
- soit on utilise un outil tout prêt, comme par exemple avec Google DialogFlow, qui permet de créer un chatbot rapidement et sans programmation : le nombre de plateformes où il n’y a qu’à fournir les données d’entraînement, et le « bon » modèle sera trouvé tout seul et apprendra tout seul sans rien avoir à faire
- soit on se lance dans sa propre implémentation et pour cela il faut des données. Beaucoup de données !
En effet, le Deep Learning est très friand en données, et il n’est pas question d’entraîner un réseau sans avoir plusieurs milliers (centaines de milliers) d’exemples à fournir lors de la phase d’entraînement. Il y a un véritable enjeu derrière cela, et les GAN peuvent permettre, dans une certaine mesure, de réduire drastiquement ce pré-requis.
Ceci étant, pour en revenir aux chatbots, si on souhaite les mettre en place soi-même, on est également confronté à un deuxième problème du deep learning : les temps d’entraînement et la puissance de calcul nécessaire ! Pour beaucoup d’algorithmes, dont les réseaux récurrents utilisés dans les chatbots, il faudra compter plusieurs jours d’apprentissage sur de très bonnes machines. Par exemple, comment avoir un chatbot qui nous répond quelque chose de cohérent si, de base, il n’a pas encore appris à parler ?
On en arrive à un concept essentiel du Deep Learning, qui permet de passer outre les difficultés ci-dessus : le transfert learning. Le principe est qu’un grand groupe (souvent Google, Facebook ou une Université) met à disposition une IA déjà entraînée, tel VGG16 qui est capable de reconnaître 1000 objets différents.
Ensuite, en partant de ce modèle tout prêt, il est possible de l’adapter à nos besoins en gagnant beaucoup de temps. Pour les chatbots, toute la partie « apprendre à parler correctement » est téléchargée via un modèle tout prêt, et il ne reste « plus » qu’à lui montrer des exemples de questions/réponses pour qu’il puisse répondre à notre besoin !
Qu’a-t-on oublié ? les SOM, les autoencoders, …
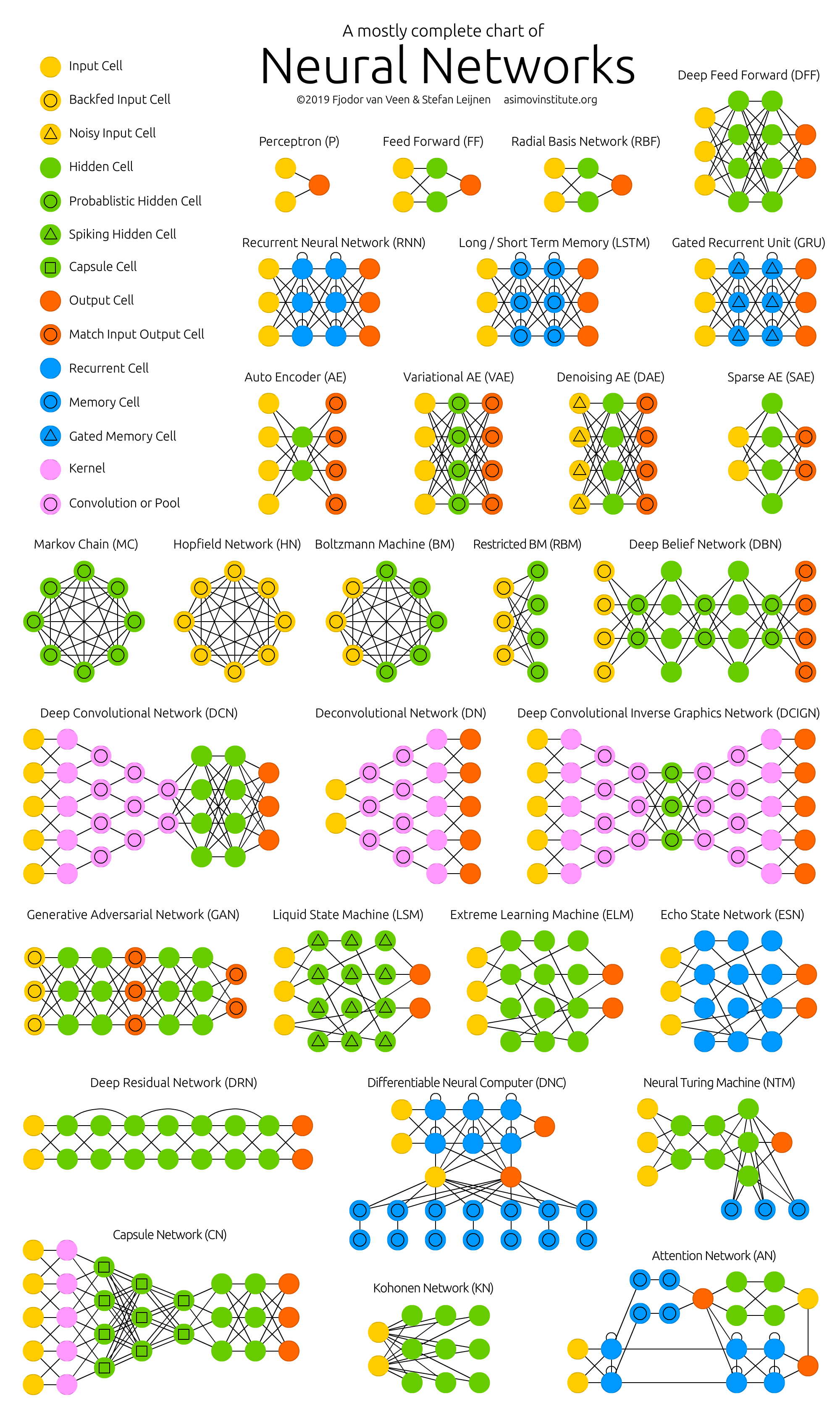
Si le sujet du Deep Learning vous a intéressé, sachez qu’il existe un très grand nombre de types de réseaux, chacun avec ses champs d’applications. N’hésitez pas à approfondir en jetant un coup d’oeil aux :
- SOM (self-organizing maps alias les cartes auto-adaptatives) : algorithmes non-supervisés qui déforment l’espace des données pour le ranger en fonction des ressemblances
- Autoencoders : forts pour grouper les données pour leurs ressemblances aussi, mais dans une optique de « recommandation », par exemple quel film regarder ensuite
- Machines de Boltzmann : dans le même style, avec une approche radicalement différente (il n’y a plus de notion d’entrée/sortie)
- et bien d’autres encore !
Merci à Fjodor van Veen de l’institut Asimov pour sa compilation d’architectures de réseaux de Deep Learning (que vous pouvez creuser, mais dont les principaux ont déjà été abordés).
Conclusion sur le Deep Learning
Débuter en deep learning est réputé plus compliqué qu’en machine learning et à juste titre ! Cependant, les résultats obtenus sont vraiment intéressant, il serait dommage de passer à côté… J’espère que ce tutoriel vous aura bien aidé à avoir la vision d’ensemble du deep learning, et vous aura simplifier bon nombre de concepts et algorithmes.
Force est de reconnaître que le deep learning représente l’avenir de l’IA : toutes les innovations actuelles, de la détection de maladies à la maintenance prédictive en passant par la traduction automatisée de langues, les voitures/robots autonomes ou encore la simple création artistique, ont pour point commun d’utiliser l’un des algorithmes étudié ici…
Il ne reste plus qu’à nous poser quelques questions sur l’IA en général pour avoir fait le tour (dans la prochaine partie) et pour que vous soyez prêts à vous lancer dans la conquête du XXIe siècle !
Crédit de l’image de couverture : Lambert Rosique



 minutes :)){kind=link}