
La reconnaissance d’image est l’enjeu majeur du deep learning (les algorithmes d’apprentissage à « plusieurs niveaux) et du monde moderne, car les champs d’application sont innombrables. Néanmoins, entraîner un algorithme et surtout l’utiliser est très coûteux en ressources car il faut utiliser des dizaines de milliers d’images des dizaines de milliers de fois… sauf si on utilise les Mobilenets (abrégé de Mobile Networks) !
Pour des services ponctuels en ligne, cela ne pose pas de problème. Mais pour de l’analyse vidéo en temps réel, comme par exemple dans une voiture autonome, le fait de pouvoir identifier des personnes, la route, des voitures est critique.
Heureusement, les MobileNets, des réseaux de neurones convolutionnels (CNN), viennent de faire leur apparition dans TensorFlow ! Parmi leurs avantages on citera :
- Extrêmement légers et petits (en termes de ligne de code et de poids des modèles)
- Infiniment rapides (avec une borne supérieure, quand même !)
- D’une précision redoutable, surtout pour les ressources consommées
- Facilement configurables pour améliorer la précision de la détection
- Dédiés à l’embarqué et aux smartphones, pour déporter les calculs comme on l’a vu avec l’avènement d’AngularJS et du Front Office
Ainsi que des utilisations variées, tournant autour de la reconnaissance/classification d’images :
- Détection d’objet (personne, bus, avion, voiture, chien, chat, écran TV, etc…)
- Visages (attributs d’un visage notamment)
- Classification « fine-grained« , c’est-à-dire entre des espèces d’une même race (chien, chat, rouge-gorge, …)
- Reconnaissance de lieux et de paysages
Ce Focus est découpé en deux parties
- Présentation de l’algorithme (vulgarisée)
- Mise en pratique de l’algorithme, à partir d’un tutoriel donné par TensorFlow.
On verra dans un cours ultérieur comment faire du boxing en couplant MobileNet avec SSD (Single-Shot multibox Detector) pour faire un MobileDet !
Bonne lecture !
I. Théorie : la reconnaissance d’image avec MobileNets
Tout d’abord, il faut savoir que les MobileNets, comme beaucoup d’algorithmes de Deep Learning, ont été inventés par Google et implémentés dans TensorFlow, donc n’hésitez pas à consulter leur article sur les MobileNets !
a. Qu’est-ce qu’un réseau convolutionnel de neurones
Si les réseaux convolutionnels de neurones, abrégés en CNN (Convolutional Neural Network) ou parfois DCNN (Deep CNN), feront l’objet d’un autre focus, on va prendre le temps d’en rappeler ici les fondamentaux pour bien comprendre les MobileNets.
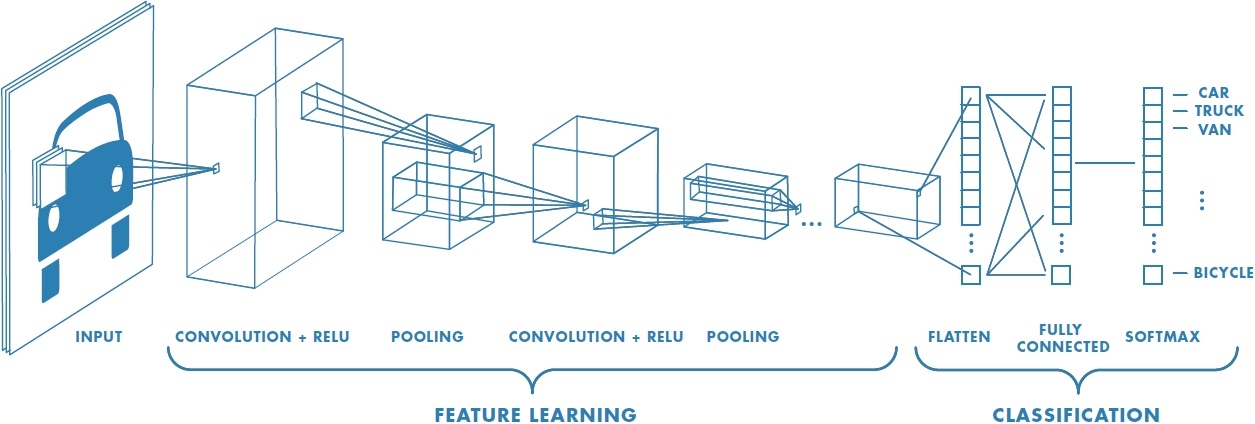
On va définir ensemble les termes utilisés dans cette image pour expliquer le fonctionnement du CNN.
- Input : il s’agit de l’image en entrée, ici une photo avec une voiture. Lorsqu’on a une vidéo en entrée, on la découpe en chacune de ses images et on applique le CNN (en général avec du tracking pour éviter d’avoir à détecter trop souvent)
- Convolution : c’est une sorte de détecteur de features. On prend des paquets de pixels, que l’on compare à une « feature » (une matrice qui représente quelque chose, comme un « nez », un « oeil », un « angle »…), et on note pour chaque paquet à quel point il ressemble à notre feature. En général, on réalise plusieurs convolutions différentes sur toute l’image. Cette notion vient des mathématiques. On parle parfois de filtres, dont vous trouverez facilement des exemples.
- ReLU : signifie Rectified Linear Unit, qui veut dire unité linéaire de rectification. Autrement dit, c’est une fonction mathématique qui annule tout ce qui est inférieur à une certaine valeur et conserve tout ce qui est supérieur : \(relu(x)=\max(0,x)\)
- Pooling : afin d’éviter la sur-information (il faut diminuer la dimension de notre image si on veut améliorer les performances), on utilise le pooling qui consiste, sur une petite région (quelques pixels en carrés), à ne conserver que la valeur la plus élevée.
- Flatten : c’est la mise à plat de l’image, qui passe d’une matrice rectangulaire (ou carrée) à un long vecteur. Pour ce faire, il suffit de concaténer à la suite toutes les lignes de pixels de l’image (ou les colonnes).
- Fully connected : dernière couche du CNN, elle prend en entrée notre image complètement modifiée par les convolutions et autres opérations (en vecteur), et renvoie la prédiction, par exemple si l’image est plus un chien ou un chat. Elle est donc le coeur de l’algorithme CNN, le reste s’apparentant plutôt à du traitement d’image.
- Softmax : c’est une fonction mathématique (exponentielle normaliée) assez simple qui prend en entrée plusieurs nombre et qui donne en sortie ces nombres en « plus petits » pour que leur somme valent 1 : \(softmax_i(a)=\frac{\exp{a_i}}{\sum\exp{a_i}}\). Par exemple, si on a en entrée 0.1 et 0.2, alors softmax donnera 0.48 et 0.52. On utilise souvent le softmax en sortie des algorithmes pour avoir des « probabilités » (l’image ressemble à 52% à un chien et 48% à un loup par exemple).
Donc si on résume un CNN, on a une image. Cette image passe dans un certain nombre de filtres, ce qui donne plein d’images. Elles sont simplifiées, puis passent par une deuxième couche de filtres et re-simplifiées. Ensuite, on les met à plat puis on les envoie à la partie de classification qui nous indique qu’est-ce qu’il a reçu (un chat, un chien, etc…) : c’est la prédiction.
b. Comment fonctionne MobileNet
Maintenant que le CNN est introduit, il va être facile d’expliquer comment marche MobileNet : les deux algorithmes sont identiques, sauf pour la partie convolution.
En effet, pour un CNN, la convolution standard est de taille 3×3, mais dans un MobileNets, celle-ci est divisée en deux parties, que l’on appelle généralement la couche de convolution séparable profonde (depthwise separable convolution)
-
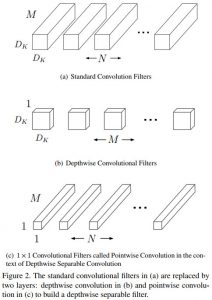
Convolution MobileNet vs CNN (crédit : Article sur arxiv) Une convolution « profonde » (depthwise convolution) de taille 3×3
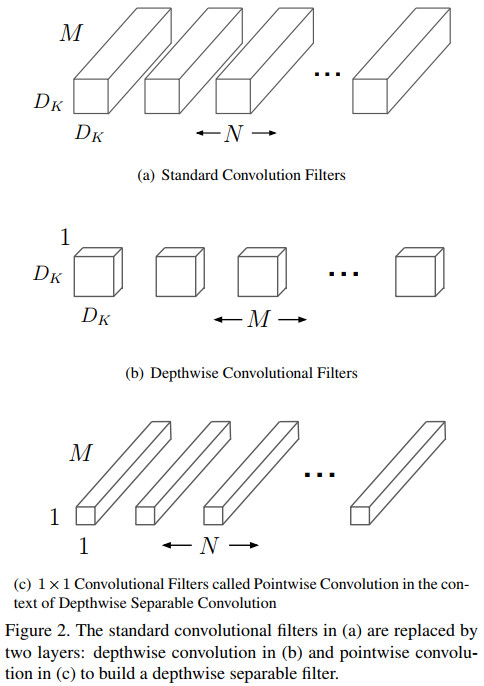
Elle sert à appliquer un unique filtre à chaque channel d’entrée (un channel d’une image représente un niveau de couleur de RGB, il y en a donc trois dans la majorité des cas) : c’est l’application du filtre. Elle diffère donc de la convolution classique qui, au passage, combine ces entrants en un nouvel ensemble de résultats.
- Une convolution « ponctuelle » (pointwise convolution) de taille 1×1
Cette couche est la deuxième phase d’une convolution classique (combinaison), sauf qu’elle est indépendante de la couche précédente (d’où le terme « separate »). Concrètement, elle applique une convolution de taille 1×1 pour combiner les sortants de la depthwise convolution.
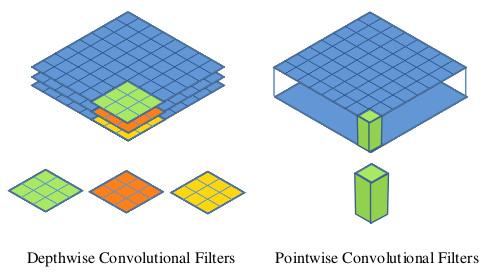
Si on observe l’image fournit dans l’article de présentation des MobileNets par Google, on peut résumer les choses ainsi : une convolution classique va prendre une image classique avec ses channels et appliquer ses filtres puis combiner les résultats; un MobileNets, à l’inverse, va appliquer des filtres à chaque channel puis va recombiner les résultats (la profondeur des parallélépipèdes représente les channels).
c. Plus rapide, plus léger, le rêve de l’embarqué
Bon, maintenant qu’on a dit tout ça, ce n’est pas évident de comprendre en quoi est-ce que « c’est mieux ». La réponse est toute simple : ce modèle de MobileNets (abrégé en MB) requiert largement moins de calculs que celui des CNN, puisqu’au lieu de combiner M (nombre de channels d’entrée) et N (nombre de channels de sortie), il additionne M et N (en les séparants ils ne sont plus multipliés en termes de complexité).
Voici les formules, à titre purement académique (se référer à l’article de Google pour plus de détails) :
- Complexité CNN : \(D_{k}\cdot D_{k}\cdot M \cdot N \cdot D_{F} \cdot D_{F}\)
- Complexité MB : \(D_{k}\cdot D_{k}\cdot M \cdot D_{F} \cdot D_{F} + M \cdot N \cdot D_{F} \cdot D_{F}\)
Ce qui représente un rapport de \(\frac{MB}{CNN}=\frac{1}{N} + \frac{1}{D^{2}_{K}}\)
Cet écart n’est pas anodin, puisqu’au final un algorithme MobileNets entraîné ne pèsera pas plus de 1 mégaoctet (contre au moins une vingtaine pour les concurrents orientés « mobiles » et plusieurs centaines pour les autres), et permettra, par exemple, de classifier des images à 130fps sur une GTX970 pour le MobileNets le plus lourd (avec le plus de couches) et à 450fps pour le plus léger… (contre 15fps maximum pour les autres) !
Cette rapidité incroyable se paye néanmoins par quelques pourcents d’erreur : 95.5% de succès pour reconnaître une route avec un MB et 95.9% pour son concurrent, Inception. N’hésitez pas à lire d’avantage de précisions sur les benchmarks.
Enfin, il grâce à la légèreté de l’algorithme en termes d’opérations, on peut l’entraîner aux 95% de précision en seulement 4 minutes… De quoi faire rêver, lorsque nos anciens CNN mettaient plusieurs heures.
II. Pratique : mettre en place son MobileNet avec TensorFlow Slim
Maintenant que vous êtes au point sur la théorie, place à la pratique, qui est assez simple une fois tous les outils en place… C’est vraiment le problème avec ces algorithmes ultra-optimisés et performant : l’installation est souvent laborieuse, mais ne vous découragez pas !
Voici le github que l’on va suivre dans ce tutoriel.
NB : pour l’utilisation du MobileNet, ce sera détaillé dans la seconde partie de ce tutoriel, avec les MobileDet (détecteurs pour mobiles !).
Préparation de l’environnement
- Pour ce tutoriel, je vous propose d’utiliser Python 3. Vous pouvez aussi utiliser le 2, c’est un choix personnel. En ce qui me concerne, je prône plutôt le 3 car c’est bien évidemment l’avenir, il est plus flexible, même si on attend encore que toutes les librairies du 2 soient migrées !
- Ensuite, une fois Python installé et ajouté au Path, il faudra mettre TensorFlow. Il s’agit d’un Framework de deep-learning développé par Google. L’installation est simple si vous êtes sous Windows. Dans la commande windows (dans rechercher, tapez cmd et validez) :
pip install --upgrade tensorflow
Pour plus de détails, je vous recommande néanmoins de bien lire les instructions, surtout si vous voulez utiliser le GPU au lieu du CPU.
Préparation des données TFRecords
Comme on l’a déjà dit, la moitié du travail en machine learning concerne la préparation des données. Afin d’accroître la vitesse d’apprentissage de ses algorithmes, Google (TensorFlow) utilise un système de base de donnée particulier, qui booste donc MobileNet.
Sans rentrer dans les détails (qui feront l’objet d’un autre article et peuvent être retrouvés en anglais), il faut savoir que l’ouverture et la lecture d’un fichier image par un fichier est très lente, comparé à la lecture d’un énorme fichier binaire qui contient toutes les informations « à la suite ». TFRecord est la conversion de plein d’images en un seul gros fichier binaire.
- Afin de ne pas surcharger ce tutoriel, on va utiliser les données proposées par TensorFlow : téléchargez la base d’images CIFAR-10 (CIFAR-10 python version)
Ensuite, on va installer TensorFlow Slim, qui est la version allégée de TensorFlow, dédiée au mobile, avec énormément d’utilitaires et d’algorithmes déjà entraînés et préparés.
- Téléchargez les Models de TensorFlow directement
ou utilisez la commande GIT :
git clone https://github.com/tensorflow/models/
Pour vérifier que tout est ok une fois que vous l’avez extrait, saisissez les commandes windows suivantes (il ne devrait pas y avoir d’erreur), en vous plaçant dans …/models/research/slim :
python -c "import tensorflow.contrib.slim as slim; eval = slim.evaluation.evaluate_once" python -c "from nets import cifarnet; mynet = cifarnet.cifarnet"
Pour convertir nos images en TFRecords c’est tout simple maintenant.
- Depuis …/models/research/slim saisissez dans la commande windows (en remplaçant ./cifar-10-batches-py par le chemin où vous avez décompressé CIFAR-10 au début) :
python download_and_convert_data.py --dataset_name=cifar10 --dataset_dir="./cifar-10-batches-py"
–> Vous aurez alors des TFRecords dans votre dossier dataset_dir !
A noter que le dataset_name doit être l’un des mots suivants : cifar10, flowers ou mnist (on verra dans un cours dédié comment utiliser d’autres sources de données).
Chargement d’un modèle pré-entraîné MobileNet
Quelques informations s’imposent pour bien tout comprendre.
- TensorFlow propose aux développeurs des algorithmes déjà entraînés sur des banques d’images. Par exemple, il propose Inception, ResNet, VGG, MobileNet, NASNet-A Mobile et NASNet-A Large.
- A chaque fois, il existe différents entraînements pour un même algorithme qui correspondent au niveau d’entraînement (si on a fait beaucoup d’itérations ou non, si on a pris des images en 128×128, 256×257, etc…)
- Une précision moyenne du modèle est également donnée, parfois nommée mAP (mean average precision) qui correspond à la moyenne de la précision globale de l’algorithme (puisqu’il est validé sur plusieurs groupes d’images). Sinon, on nous donne le Top-1 Accuracy qui est le meilleur score réalisé par l’algorithme.
Dans notre cas, on va prendre le meilleur MobileNet, avec un score de 70.7, mais ce n’est pas forcément une bonne pratique, surtout si vous voulez le ré-entrainer sur vos données !
Télécharger MobileNet_v1_1.0_224
La suite du tutoriel Github se concentrant sur Inception_V3, un autre modèle que MobileNet, on va s’en détacher à présent, mais n’hésitez pas à en finir la lecture !
Continuer l’entraînement de son modèle, utiliser et tester son modèle…
On a vu beaucoup de concepts ensemble et vu plusieurs méthodes. Maintenant, j’imagine que vous voulez absolument savoir comment utiliser MobileNet sur vos propres données…
Malheureusement, la version actuelle de TensorFlow ne fonctionne plus avec le chargement des modèles pré-entraînés (car ils l’ont été sur une version différente), et on a systématiquement l’erreur « ValueError: No op named SSTableReaderV2 in defined operations. » qui n’est pas encore résolue (le correctif ne marche de nouveau plus). Spoiler : ce n’est pas grave, on va faire beaucoup mieux qu’un simple classifier avec les MobileNet-SSD (alias MobileDet) !
–> Dès qu’un correctif aura été livré, je mettrais à jour cet article pour terminer le tutoriel.
J’espère que ce focus vous a plu, et que la théorie ne vous a pas fait fuir… Merci de me dire ce que vous en avez pensé dans les commentaires 🙂
Crédit de l’image de couverture : Lambert Rosique



{kind=link}
[…] n’y a pas si longtemps, on parlait des MobileNet, de la reconnaissance d’image en temps réel. Véritable enjeux de notre société, son […]
[…] classiques, et applique au total 5 couches de convolutions avant la partie « pooling » (cf le focus sur les MobileNets). Le second est de type ResNet, une architecture qui ajoute cette fois une […]
[…] de reconnaissance d’image avec d’autres subtilités, au même titre que YOLO, MobileNet, […]
[…] lorsque les protagonistes ne regardent pas l’objectif. Ses réseaux neuronaux basés sur MobileNet ont été conçus pour reconnaître cinq expressions classiques du selfie : les sourires, […]