
Lorsqu’on s’attaque à un problème de Deep Learning, on s’interroge quasi-systématiquement sur le framework à utiliser. Beaucoup revendiquent être le plus populaire, mais qu’en est-il réellement ?
De Reddit qui prône PyTorch à François Chollet avec TensorFlow/Keras, on peut s’interroger sur la place de Caffe, Theano et bien d’autres en 2019. L’étude suivante, réalisée par Horace He, sépare l’industrie de la recherche pour vous permettre de faire le point sur cette année et de décider du meilleur outil pour 2020 (en fonction de vos besoins) !
Quel framework IA pour de la Recherche ? PyTorch monte en flèche
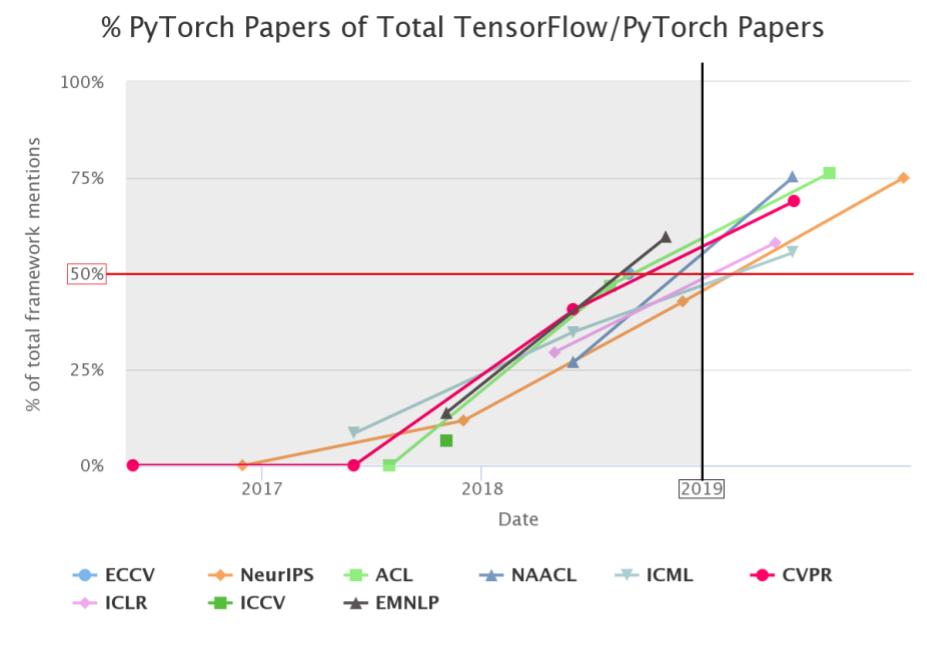
Pour chacune de ces émérites conférences d’intelligence artificielle (ECCV, NeurIPS, ACL, …), on a comptabilisé le nombre de papiers s’appuyant sur PyTorch et le nombre de papiers s’appuyant sur TensorFlow, les deux frameworks principaux en recherche.
En 2019, à NeurIPS, on a donc constaté que dans 75% des papiers considérés (nombre de PyTorch + nombre de TensorFlow) PyTorch était utilisé ! Une grosse progression puisqu’en 2017 PyTorch n’apparaissait que dans 1 papier sur 9…
Si on observe attentivement le graphique, on peut constater qu’aucune conférence de 2019 avait pour majorité des papiers avec TensorFlow, contrairement à 2018 où la barre des 50% était rarement dépassée :
PyTorch est le framework le plus populaire en 2019 dans la recherche académique. Sa tendance est largement à la hausse.
TheGradient propose un second graphique présentant le nombre de mentions unique de l’un ou l’autre framework, afin de confirmer la tendance : les grandes conférences recensent davantage de mentions de PyTorch ! 69% pour CVPR, 75% pour NAACL et ACL, 50% pour ICLR et ICML, etc…
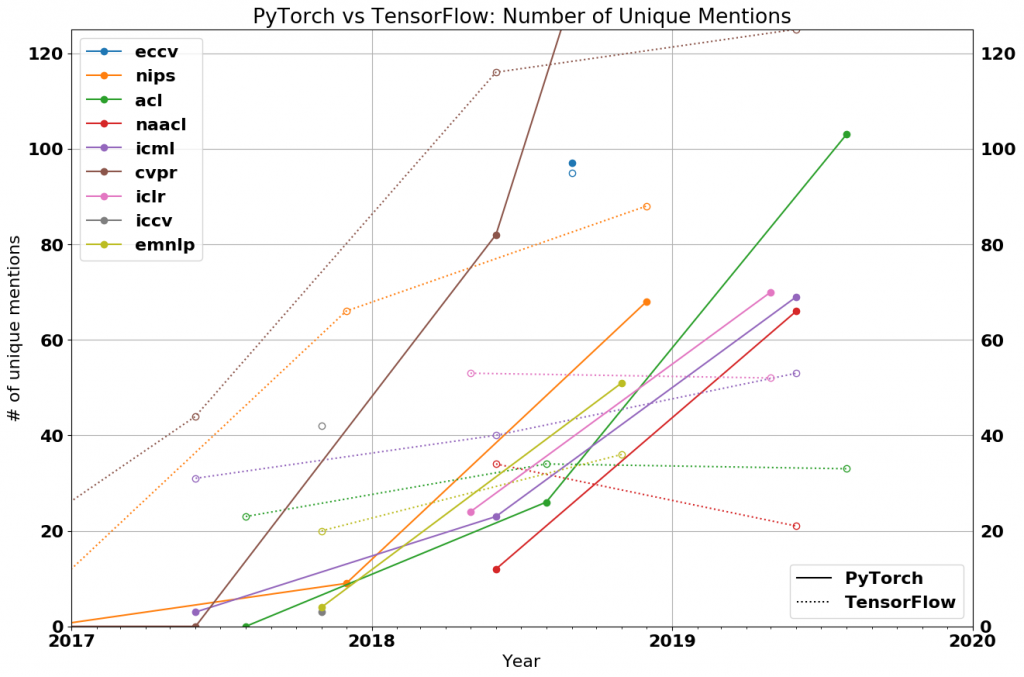
En particulier, on constate peu d’augmentation du nombre de papiers parlant de TensorFlow, ce qui indique une stagnation (voire régression) de l’utilisation de TensorFlow dans la recherche.
Comment expliquer l’engouement des chercheurs pour PyTorch ?
Plusieurs critères entrent en compte lorsqu’un chercheur souhaite implémenter un algorithme de Machine Learning / Deep Learning :
- La simplicité : il faut que le code soit simple à lire et qu’il s’intègre bien dans l’écosystème de Python, car un chercheur fonctionne surtout par POC (proof of concepts). Il va essayer rapidement un algorithme et le jeter ensuite si les résultats ne sont pas probant
- Une bonne API : le framework doit être stable au sens où les chercheurs utilisent souvent les dernières versions de ce dernier et ne veulent pas réapprendre à l’utiliser (ou même avoir de l’ancien code obsolète)
- Des performances : ce critère plutôt réservé à l’industrie trouve sa place ici puisque l’objectif est d’avoir rapidement des premiers résultats
Que vaut TensorFlow (TF) vis-à-vis de PyTorch pour ces critères ?
- TF n’est clairement pas simple, c’est la première raison qui m’en a éloigné personnellement. Par exemple, pour déboguer un modèle, il faut activer une session et écrire du code difficile à interpréter (placeholder, etc…). Tandis que dans PyTorch, on peut le faire rapidement et de n’importe où grâce aux pdb breakpoints…
- TF a également changé plusieurs fois d’API et demande des versions très précises de numpy & cie, au risque de remonter plein d’erreurs sinon : c’est un véritable jeu de l’équilibriste
- Enfin, pour les performances, aucun des deux frameworks n’est meilleur que l’autre
Peut Tensorflow remonter dans la recherche académique/R&D ?
A priori la situation est difficile du côté de Google : cette stagnation/baisse de son framework aux grandes conférences d’intelligence artificielle va inciter les chercheurs à se tourner vers PyTorch (et à utiliser du code publié en PyTorch).
Un retour en force de TensorFlow ne pourra qu’être lent, d’autant qu’une partie des chercheurs de Google/DeepMind montre des signes de préférence pour PyTorch (selon des sources internes) et souhaite avoir le choix du framework, afin que la communauté continue de participer à la vie des projets de Google.
A noter que le passage de TensorFlow à sa version 2.0 pourrait néanmoins induire un retour du framework, même si personnellement je n’ai pas été convaincu pour ce type d’applications.
Et les autres frameworks ?
Comme vous le constaterez par la suite, aucune place n’est laissée aux concurrents de PyTorch et TensorFlow : Caffe, Theano, Keras et bien d’autres encore.
La raison en est toute simple : ils ne sont pas assez utilisés comparés aux deux premiers, et sont bien plus limités en termes de fonctionnalités et utilisabilité (à l’exception de Keras, mais on peut considérer que ce framework n’existe plus et est embarqué dans TensorFlow 2.0).
Ainsi, je ne conseillerai jamais d’utiliser l’un de ces « autres frameworks », à l’exception de Keras pour s’entraîner aux bases de l’IA et, de toute façon, ils ne sont pas sur le podium des meilleurs framework de machine learning de 2019 !
Quel framework utiliser pour la Production / Industrie ?
Pour la recherche, la tendance est sans appel. Mais qu’en est-il des applications pratiques ? Celles qui partent en production dans les sociétés et sont largement employées par l’industrie ?
Commençons par des indicateurs évidents : le nombre d’offres d’emploi, le nombre d’articles utilisant l’un ou l’autre framework sur Medium, et le nombre d’étoiles sur Github (qui montrent l’engouement des utilisateurs pour le projet)
| Critère | PyTorch | TensorFlow |
| Offres d’emploi | 1437 | 1541 |
| Articles Medium | 1200 | 3230 |
| Etoiles Github | 7 200 | 13 700 |
Même si on peut expliquer ces résultats par le temps que met l’industrie à s’emparer des outils de recherche (on parle d’inertie), TensorFlow (qui est sorti plusieurs années avant PyTorch) dispose d’atouts indéniables qui séduisent les « professionnels » :
- Les performances de TensorFlow sont plus élevées. Un algorithme seulement 10% plus rapide peut permettre d’économiser des millions d’euros à une société, tandis que pour un chercheur cela ne fera aucune différence (ce qui compte pour lui c’est de pouvoir implémenter rapidement une idée et d’avoir des premiers résultats sur un petit jeu de données, sans perfectionner immédiatement l’IA)
- Le déploiement et le monitoring de TensorFlow est plus aisé/optimisé, avec de nombreux outils à disposition (par exemple TensorBoard). TensorFlow est ainsi capable de s’adapter aux contraintes internes des entreprises
- Choisir de ne pas utiliser Python : dans certains cas, l’industrie peut préférer employer des scripts en C++ sans le runtime Python, ce qui est possible avec TensorFlow (par exemple, pour un téléphone, avec la version Mobile de ce dernier)
TensorFlow est un framework avec beaucoup de sous-versions, chacune avec ses spécificités et sa capacité à répondre à des problématiques précises : c’est ce qui en fait sa force. Que vous vouliez une version sans Python et vous aurez le format graphe avec le moteur natif d’exécution. Que vous souhaitiez une version allégée et adaptée aux mobiles ou aux cartes embarquées, et vous prendre TensorFlow Lite ou Serving…
A l’inverse, PyTorch n’a pas autant de souplesse.
TensorFlow est le choix logique de 2019 pour l’industrie : souple, performant, à l’écosystème riche qui adresse toute problématique d’entreprise (mobile, monitoring, etc…).
L’éveil de PyTorch avec TorchScript et les graphes
Revenons brièvement sur les graphes en intelligence artificielle : lorsque l’on définit un modèle de deep learning, par exemple un réseau de neurones artificiels en TensorFlow, on écrit le code avec les différentes couches :
# Define the model.
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])Ce modèle est du code Python, qui doit être interprété par le langage pour être utilisé. TensorFlow a donc eu l’idée de représenter les modèles sous forme de graphes i.e. des noeuds reliés à d’autres noeuds par des flèches, pour améliorer ses performances :
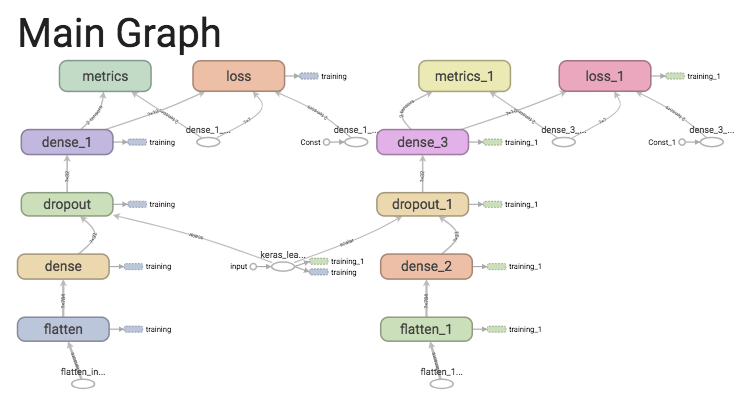
Au-delà de l’interactivité proposée par l’outil de visualisation de TensorFlow Graph, ces graphes sont la manière interne dont fonctionne TensorFlow : au lieu d’évaluer le code directement, il crée une représentation en graphe mais ne l’exécute que dans une session (on parle de dataflow)… Ce sont les fameux « tensors » que l’on retrouve partout et qui nous empêchent (bien souvent) de voir le contenu des variables !
PyTorch, pour sa part, fonctionnait différemment jusqu’à sa version 1.1 qui inclut le compilateur JIT (just in time i.e. qui compile à la volée) !
Du code PyTorch du JIT peut être lu de deux manières distinctes :
- le mode TorchScript = qui peut, en plus, sérialiser et dé-sérialiser des modèles facilement
- le mode Tracing = qui repose davantage sur du Python/C++

Le JIT dispose ensuite, une fois le code lu dans l’un des deux modes, d’une représentation intermédiaire (intermediate representation ou PyTorch IR) à partir de laquelle on peut travailler : exécuter le code, l’optimiser, le factoriser, etc…
Cette représentation intermédiaire du code PyTorch est l’équivalent du mode graphe de TensorFlow, où on peut exporter nos modèles en C++ sans Python (par exemple via LibTorch).
Plus fondamentalement, le mode « script » (de TorchScript) prend une classe ou une fonction, en réinterprète le code Python et renvoie directement le TorchScript IR. Généralement, il est plus difficile d’écrire le code JIT permettant de passer par le mode TorchScript (car il n’est pas directement utilisable).
A l’inverse, le mode « trace » d’un fichier PyTorch est facile d’utilisation mais limité : il prend en entrée une fonction et un input puis enregistre toutes les opérations qui sont exécutées en interne sur cet input, pour construire le PyTorch IR. Le défaut immédiat que l’on peut voir ici est qu’il y a un risque de ne pas passer par tous les états internes possibles. Imaginons par exemple que l’on ait un « if… else… » dans notre fonction : si dans l’input il n’y a rien qui nous fasse passer par la condition false, alors celle-ci ne sera tout simplement pas enregistrée dans le graphe !
PyTorch, avec le JIT et TorchScript, peut désormais être employé en embarqué !
La contre-attaque de TensorFlow et son mode « eager », souple et pratique
On a vu que PyTorch a su réagir et trouver une solution à son principal reproche. Qu’en est-il de TensorFlow, que je trouvais trop difficile à déboguer/prendre en main (à cause du système de sessions et donc de la représentation en graphe) ?
Depuis la version 2.0 de TensorFlow, le mode « eager » qui vient améliorer tout ça en étant automatiquement activée/activable (comme dans PyTorch) !
Voici une courte vidéo (en anglais) qui illustre bien l’intérêt d’avoir un mode « eager ».
Concrètement, TensorFlow est maintenant capable d’évaluer un noeud du graphe sans avoir d’abord à créer une représentation de la totalité du graphe. Ceci peut sembler évident mais implique quelques contraintes :
- Un modèle eager Tensorflow ne peut pas être exporté vers un environnement sans Python
- Il ne peut pas non plus être optimisé
- Il n’est pas compatible avec les mobiles
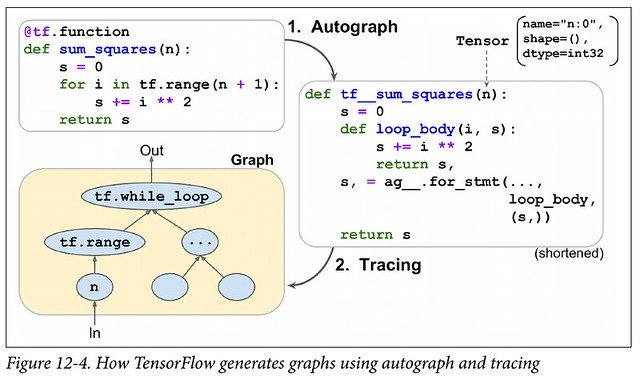
- Mais il permet de tracer son code (via tf.function)
- Et de réinterpréter le code Python avec l’Autograph dont voici un schéma expliquant le passage de code TensorFlow au graphe (à droite)
Qu’attendre de demain ?
Comme on l’a vu, PyTorch est un concurrent très sérieux qui a fini par prendre les devants à TensorFlow dans le milieu académique. Cependant, le framework de Facebook n’existait pas il y a de ça quelques années… On peut donc légitimement s’interroger sur la montée d’un nouveau framework ou d’une technologie disruptive, même en 2020 !
L’arrivée de Jax et des dérivées secondes
La première ouverture dont je souhaitais discuter ici, même s’il ne s’agit pas d’un concurrent pour l’instant, est de Jax. Commençons par en comprendre l’enjeu.
En deep learning, les réseaux de neurones (supervisés) apprennent en comparant ce qu’ils ont prédit à la réalité. Par exemple, qu’un appartement devrait coûter (d’après le modèle que l’IA a imaginé) 100k€ alors qu’il en vaut 200k€ en réalité : l’erreur commise est de -100k€. Ensuite, l’algorithme va regarder toutes les opérations qu’il a réalisé pour arriver à cette conclusion « ça coûte 100k€ » en partant de la fin et en remontant jusqu’aux données d’entrée (appartement de 100m² dans le centre-ville, avec 4 pièces). Il va chercher, au fur et à mesure, à évaluer l’impact qu’avaient les variables impliquées dans ces opérations (les poids et le biais par exemple) sur l’erreur commise : en mathématiques, cela se traduit par le fait de calculer une dérivée (en IA, appelée le gradient) et de regarder comment se comporte la fonction par rapport à une variation de telle ou telle variable ! Toute cette phase d’apprentissage vers l’arrière est appelée « backpropagation » ou rétro-propagation, alias le « reverse-mode auto-differentiation » du framework de machine learning (TensorFlow, PyTorch, …).
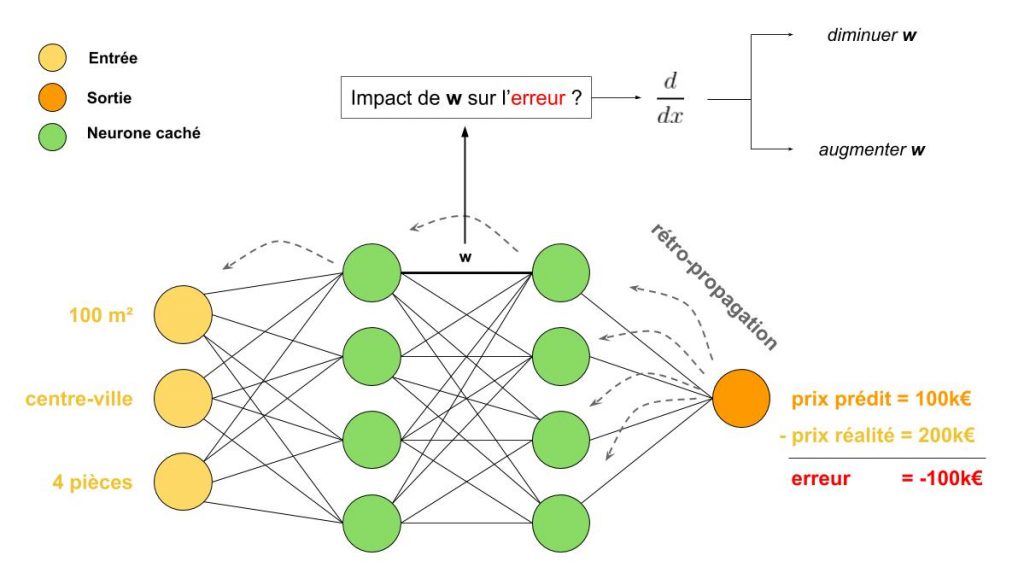
Si les frameworks actuels sont optimisés pour ce reverse-mode auto-differentiation, ils ne le sont pas pour les réseaux où on a besoin non pas de dériver 1 fois mais plusieurs fois d’affilé (calculer la dérivée de la dérivée i.e. l’impact qu’à l’accélération d’un changement de poids), par exemple pour des produits de vecteurs Hessiens. Ce genre de calcul passe par le « forward-mode auto-differentiation« , non-inclus/optimisé avec les frameworks modernes.
C’est là qu’intervient Jax, développé par des anciens du projet Autograd, avec sa capacité à réaliser ce type de calculs en un temps record comparé à ses concurrents. A noter qu’il embarque d’autres outils comme le batching (création de batch) automatique via vmap et la parallélisation automatique via pmap, et voit sa communauté grandir.
La génération de code hardware : un enjeu pour 2020
On va parler ici de la partie purement hardware qui vient faire le lien entre le code écrit par le développeur en PyTorch par exemple, et les calculs réalisés par l’ordinateur (ou la machine).
En effet, contrairement à ce qu’on pourrait penser, lorsqu’on exécute un modèle PyTorch ou TensorFlow, la plupart des opérations ne sont pas réalisées par le framework mais par des noyaux externes (third party kernels) qui sont gérés soit par le fournisseur de matériel : MKLDNN pour de nombreux processeurs, cuDNN pour les cartes graphiques Nvidia, etc…
Ainsi, le framework va découper son code en morceaux (chunks) qu’il va envoyer à la librairie du matériel pour l’évaluer avant d’agréger les résultats. Chaque librairie est ainsi développée par une équipe différente, et a souvent du mal à suivre la recherche ou les optimisations. Typiquement, les réseaux capsules qui utilisent une architecture originale ont mis longtemps à être optimisés (et donc utilisables).
D’ailleurs, de plus en plus d’architectures de machine learning ont des besoins en matériel non-standard, en tenseurs clairsemés (sparse tensor), ou même en nouveaux opérateurs (hessiens par exemple). Même s’il existe plusieurs outils comme XLA, Taco, Tensor Comprehension ou encore Halide, le risque ici est que la recherche (et donc l’industrie) se retrouve limitée par ce code hardware.
Que se serait-il passé si les réseaux capsules avaient été dix fois plus longs à entraîner ? Ne les aurai-t-on pas abandonnés directement, pensant qu’ils ne convergeraient pas ? Et s’il avait été impossible de les implémenter directement ? Contrairement à l’informatique quantique qui n’avance pas vite car on n’a pas le matériel, ici on l’a mais on n’a pas le temps/les compétences pour en élargir le périmètre. C’est donc un sujet important pour notre ouverture d’esprit/recherche de nouvelles solutions, à garder en tête pour 2020.
Conclusion : Etat de l’art des frameworks de Machine Learning fin 2019
Vous l’aurez compris, la réponse doit être contextualisée :
- Dans le milieu de la recherche (R&D) ou pour la réalisation de POC (preuve de concept), PyTorch est le meilleur framework grâce à ses fonctionnalités
- Dans l’industrie et pour la mise en production d’algorithmes de machine learning, TensorFlow est encore à ce jour la solution la plus employée pour sa versatilité et ses performances
Ceci étant, chacun des deux framework travaille à combler ses lacunes et 2020 pourrait bien nous réserver des surprises, même si, a priori, PyTorch a bien plus de chances de venir concurrencer TensorFlow dans les entreprises plutôt que l’inverse en recherche !
Voici quelques questions auxquelles il peut être important de réfléchir.
1) Est-ce que la préférence de la R&D pour PyTorch va influencer cette course au meilleur framework ? Très certainement, puisque la plupart des entreprises cherchent à recruter des thésards : PyTorch sera donc le framework qu’ils connaîtront et maîtriseront le mieux.
2) Est-ce que le mode « eager » de TensorFlow peut lui redonner un coup d’éclat et rattraper l’avancée de PyTorch dans ce domaine ? TensorFlow existe depuis de nombreuses années et a ses propres limitations historiques. En l’état, son mode eager est moins performant et risque d’être limité par l’existant. A noter aussi que le passage de TF 1 à TF 2 risque d’être compliqué pour de nombreuses sociétés (il faut repenser une partie de son code avec le mode eager, donc peut-être est-il plus intéressant d’investir dans PyTorch)
3) Est-ce que PyTorch peut être utilisé en production ? Suivant l’utilisation et les limites, PyTorch se révèle être bien plus limité que TensorFlow. Dans l’absolu, oui, on peut utiliser PyTorch maintenant qu’il est accessible sur mobile (avec les graphes) sans Python et peut travailler avec des modèles quantifiés (i.e. les calculs sur les tenseurs sont réalisés avec des entiers plutôt qu’avec des nombres à virgule, ce qui augmente considérablement les performances). Pour l’instant en tout cas, il faut rester vigilant sur ces nouvelles fonctionnalités de PyTorch et ne pas se jeter sur la production !
4) Est-ce que les autres grandes sociétés vont se tourner vers TensorFlow ou PyTorch ? Prenez Microsoft, Amazon, Nvidia ou même Apple : Google cherche à contrôler l’ensemble de la verticale du machine learning, des algorithmes jusqu’aux serveurs (avec sa plateforme Cloud). Cette stratégie est souvent payante, car elle permet de proposer une solution de bout-en-bout clef en main, ce que beaucoup de clients (souvent des PME) apprécient grandement. Afin de contrer l’hégémonie de Google, surtout dans les services de Cloud, Microsoft/Amazon/Nvidia voient PyTorch d’un très bon oeil (d’autant qu’il s’agit de la seule alternative actuelle à TensorFlow) !
Remerciements et sources de l’étude
Je tiens à signaler que cet article est fortement inspiré de celui d’Horace He sur TheGradient, que je vous invite à consulter si vous préférez l’anglais. En effet, son étude étant très complète, il n’y avait pas de valeur ajoutée à refaire son travail, donc, avec son accord, j’ai utilisé une partie de ses images ainsi que ses propres résultats et projections (inspirés de ses travaux chez Google et Facebook).
Je remercie donc vivement Horace et TheGradient, et j’espère que vous avez maintenant une vision claire de quel framework d’IA est le plus populaire en 2019… N’hésitez pas à nous dire sur Twitter ou Facebook vers où va votre préférence/votre besoin !
Crédit de l’image de couverture : image modifiée d’Horace He – The Gradient



{kind=link}