
Dans la partie 1 de cette série, dont le but est de fournir un panel de connaissances autour de l’IA sans rentrer trop dans le détail, nous avons vu une chronologie de l’intelligence artificielle ainsi que les choix techniques de programmations.
Aujourd’hui, nous allons aborder plusieurs notions transverses telles les données (de leur préparation à la mise en production de l’IA associée) et la loi, ainsi qu’une partie de l’écosystème de la data science, fortement lié au machine learning. Bonne lecture !
Remarque : la série est divisée en plusieurs articles :
Tutoriel 1 = sur l’IA en général et les choix techniques (langage, framework…)
Tutoriel 2 (ici) = sur les notions transverses (la donnée, la législation, la data science, hadoop…)
Tutoriel 3 = sur comment se former à l’IA, comment valoriser son savoir et surtout comment se démarquer en restant pro-actif !
Tutoriel 4 = sur le machine learning, avec tous ses algorithmes principaux en exemple : k-means, random forest, SVM…
Tutoriel 5 = sur le deep learning en détail (avec son utilisation) : réseaux de neurones artificiels, convolutifs, récurrents, etc…
Tutoriel 6 (à venir) = des grandes questions que l’on se pose sur l’IA, avec des pistes de réflexion et mon avis personnel ouvert au débat 🙂
II. Notions transverses à l’IA
Les données et leur stockage
On attaque avec le cœur même de l’intelligence artificielle : la donnée. Contrairement à ce qu’on pourrait croire, le plus long dans le développement d’une IA ce n’est pas « trouver le bon algorithme » ni même « l’optimiser » (même si les temps d’entraînement se comptent en heures pour chaque test)… mais quelles données utiliser et comment les préparer !
Sur le schéma à droite, on peut voir que le machine learning ne nécessite pas de grands volumes de données (comprendre par là un petit millier d’exemples). Cependant, la performance (le taux de prédictions correctes) stagne rapidement : même si on injecte davantage d’exemples, l’IA ne deviendra pas meilleure.
A l’inverse, le deep learning (représenté par trois versions d’un algorithme ici) nécessite un minimum de données pour pouvoir prédire quoi que ce soit, sans quoi il ne sert à rien. Mais la courbe de performance croît très rapidement jusqu’à dépasser largement le machine learning et fournir des taux de prédictions particulièrement élevés ! Il faut compter généralement de quelques milliers d’exemples à plusieurs centaines de milliers.
Disposer d’un jeu de données varié est primordial pour l’IA, dont le rôle est de construire un modèle qui prend en entrée ces données et associe une prédiction réaliste (dans le cas d’un modèle supervisé), sans quoi il n’y a pas de généralisation possible.
Prenons un exemple, dont la question est « combien mesure une fille de 13 ans » :
- Jeu de données : voici un garçon de 12 ans qui mesure 152cm (données inventées pour l’exemple)
-> On ne peut pas répondre à la question car on n’a pas assez d’exemples
- Voici de plus un garçon de 13 ans qui mesure 156cm et un garçon de 14 ans qui mesure 164cm
-> On ne peut pas répondre à la question car on sait (en tant qu’humains et d’expérience) qu’une fille sera plus petite qu’un garçon. Mais l’IA répondra que la fille de 13 ans mesure 156cm, car elle n’a accès qu’à ces informations qu’on lui montre. On n’a pas assez de variété dans nos données pour généraliser le modèle !
- Voici maintenant une fille de 12 ans qui mesure 150cm
-> A priori à 13 ans elle fera donc environ 154cm (puisqu’elle fait 2cm de moins à 12 ans qu’un garçon, elle fera probablement aussi 2cm de moins à 13 ans). C’est juste en théorie (et pour ces données précises) mais faux en pratique (si on ajoute plus d’exemples), car la relation n’est pas linéaire (âge – taille). On peut encore améliorer le résultat en ajoutant l’exemple d’une fille de 14 ans qui ne mesure pas 162cm mais… 158cm. On en déduit que la taille attendue à 13 ans sera plutôt de 152cm (réponse finale du deep learning, tandis que le machine learning restera sur son 154cm si on a atteint le plateau de performance) !
De plus, la question de comment accéder à ces données rapidement, puisqu’elles doivent être fournies à l’IA pour son entraînement, représente un certain défi : faut-il les charger dans la RAM, les requêter depuis le web ou un serveur (mais alors pour des images cela peut ajouter un certain temps)… Il n’y a pas de réponse précise à donner ici, il faut simplement être conscient des optimisations que l’on peut faire pour accélérer l’apprentissage.
La donnée est primordiale : il en faut beaucoup, il la faut variée, et il la faut accessible
Annoter les jeux de données
Avoir des données c’est une chose, avoir des données utilisables ça en est une autre ! En effet, pour entraîner une IA à trouver des chats dans une image, il ne suffit pas d’avoir plein de photos de chats… il faut également qu’elles soient annotées. C’est-à-dire il faut que le chat soit encadré et qu’il soit précisé que ce cadre correspond à un chat !
Dans l’image ci-dessus, pour « object detection », des humains (puisque le but est de créer une IA capable de faire ça, cela signifie qu’il n’y en a pas encore et que tout doit être fait à la main) ont donc pris des milliers d’images et encadré sur chacune tous les objets que l’IA devra détecter et encadrer. Un travail titanesque (même s’il existe des outils pour gagner du temps), souvent effectué par des étudiants et peu rémunéré (ni reconnu). Les GAFAM (Google Amazon Facebook Apple Microsoft) notamment utilisent naturellement les données collectées, que l’on annote pour eux. Par exemple, pour certains CAPTCHA, lorsqu’on vous demande d’entourer les feux rouges… ce n’est pas pour vérifier si vous êtes humains, mais pour obtenir l’annotation « feux rouges » sur cette image (ou vérifier qu’elle est correctement annotée) !
Souvent par manque de moyens, dans les petites entreprises, soit les jeux de données sont achetés, soit ce sont les data scientists ou les data engineers qui « préparent » les données, en téléchargeant des images (par exemple) sur internet et en les annotant si besoin.
L’annotation est la phase la plus longue et importante : DE mauvaises annotations entraîneront de mauvaises prédictions
Retour sur les lois autour de l’IA (et la donnée)
Sans trop rentrer dans le détail car la loi (française et européenne) évolue vite et il sera plus pertinent de se renseigner sur le sujet, il faut savoir qu’il existe un certain nombre de contraintes (légales) sur vos intelligences artificielles :
- Toutes les données utilisées, que ce soit pour des tests ou pour de vrais entraînements, doivent appartenir à l’entreprise ou être libres de droits. En particulier, il est interdit d’aller télécharger des images de chats sur Google Image si l’on n’a pas les droits d’auteur dessus ! Même si, dans la pratique, cette législation est difficilement applicable (un tribunal aura du mal à avoir la preuve qu’une image privée a été utilisée). A noter qu’il existe un flou juridique sur « est-ce que l’apprentissage d’une IA est considéré comme une reproduction (soumise aux droits d’auteurs donc) ou non », donc suivant les cas il est « possible » d’utiliser des images sous copyright…
- De plus, les données sont soumises au RGPD. En particulier, toute donnée sensible doit être anonymisée ! Pas question d’entraîner (ni même de l’utiliser) une IA avec le numéro de sécurité sociale si vous n’avez pas hashé le nom/prénom de la personne correspondante…
- Ensuite, concernant l’intelligence artificielle, elle n’a pas de responsabilité en tant que telle : c’est l’entreprise qui subit les conséquences. Par exemple, si vous créez une IA de prédiction du marché et que quelqu’un se retrouve ruiné suite à une mauvaise prédiction, il pourra porter plainte (sauf si vous avez précisé que votre IA ne donne que des probabilités, que vous ne pouvez pas être tenus pour responsable, etc…). Soyez donc prudents sur vos conditions d’utilisation (je pense également aux applications de types « puis-je prendre ce médicament en parallèle de celui-ci »). Il en va de même pour un robot qui blesserait un humain (voiture autonome), même si la responsabilité est beaucoup plus floue : la résolution parlement européen 16 février 2017 sur la robotique indique qu’un humain ne devrait pas être tenu pour responsable du comportement d’un robot autonome mais devrait avoir une assurance…
- Aucune loi n’existe sur le degré d’intelligence que peut avoir une IA. Rien ne vous empêche de créer une « intelligence globale » à l’heure actuelle. Par contre, les IA à but militaire (celles capables de tirer de manière autonome sur des cibles) sont décriées de toutes parts et sont illégales pour des particuliers (et on espère pour les gouvernements).
- Comme vous vous en doutez, avec le RGPD, il est interdit de collecter des données sans le consentement des utilisateurs, et encore moins de les utiliser à leur insu.
- Et bien entendu, un robot n’est pas reconnu comme ayant le moindre droit (c’est un objet comme votre smartphone ou votre télévision).
Les biais principaux qui font débat (racisme, sexisme…)
Qu’on se le dise tout de suite, une IA n’est ni raciste ni sexiste. C’est notre interprétation, nos attentes qui en font ce qu’elle est. Dans l’exemple ci-contre, la détection de visage ne marche pas sur la personne de droite car dans les données d’entraînement on ne lui a donné quasiment aucun visage d’afro-américain (en comparaison du nombre de visages caucasiens).
Par exemple, le taux d’erreur d’une IA déterminant le sexe d’une personne est, pour une femme noire, de 35% ! Un nombre alarmant, quand on pense que les IA sont utilisées pour scanner les CV, permettre l’accès à certains services (liés à la reconnaissance faciale ou à l’annotation de ses photos), voire détecter des comportements suspects…
- « Racisme » : comme on vient de le voir, les IA ont beaucoup de difficultés avec les personnes afro-américaines car de manière générale les IA sont entraînées par le GAFAM (Google, Amazon, Facebook, Apple, Microsoft) sur leurs données (ils sont moins implantés/utilisés en Afrique qu’en Europe et aux Etats-Unis). A noter que la Chine développe de nombreuses IA également (par exemple avec Alibaba), dont le jeu de données comporte quasi-exclusivement des personnes asiatiques. La situation inverse de racisme risque donc d’arriver aussi…
- « Sexisme » : la plupart des développeurs étant des hommes, certaines de leurs valeurs peuvent être transmises à l’IA. L’exemple des CV donné ci-après fonctionne, mais là j’avais plutôt en tête les nombreuses photos de femme au foyer comparées aux nombreuses photos d’hommes d’affaires. Si on imagine une IA entraînée à prédire « quel métier convient le mieux à telle personne », alors, sans surprise, la plupart des femmes seront poussées à devenir femme au foyer. Si une telle IA était employée à Pôle Emploi ou par des cabinets de recrutement, cela renforcerait l’absence de femmes dans les postes à hautes fonctions !
- « Xénophobie » : revenons sur l’IA d’analyse des CV. Elle va être entraînée sur de nombreux CV, en retenant lesquels sont intéressants pour l’entreprise. Si cette dernière n’engage que peu/pas de personnes étrangères, ou fournit à l’IA des CV de personnes étrangères (en quantité plus importante que de personnes pas étrangères) non pertinents, l’IA aura fortement tendance à écarter tous les CV dès lors que la personne sera typée par rapport à la population locale. En bref, elle sera « xénophobe » d’un point de vue humain (et elle aura un bon taux de prédiction des bons CV pour elle).
- Biais inconscient : prenons le cas d’une IA entraînée à détecter les comportements suspects dans Londres. Celle-ci apprendra en visualisant des vidéos d’agressions, de vols, etc… souvent commis par le même type de personnes (milieux défavorisés). Ainsi, elle aura tendance à suspecter plus facilement les personnes semblant venir de ces milieux (elle se basera plus sur la couleur de peau que sur les vêtements pour définir ces personnes), provoquant de nombreuses mauvaises arrestations. Bien entendu, d’un point de vue statistiques, elle aura « raison » car ces personnes sont plus « à risque », mais d’un point de vue humain, arrêter 9 personnes noires pour 1 personne blanche est considéré comme du racisme ou au moins un gros biais de sélection des suspects (qui devrait s’appuyer sur le comportement et non la couleur de peau).
Une ia est biaisée par la manière dont on la programme et on l’entraîne. Pourtant, elle n’est pas « mauvaise ».
Comment sauvegarder un modèle d’IA ? Qu’est-ce que le transfer learning ?
Vous avez passé des heures (dizaines, centaines, milliers) à entraîner votre IA, et maintenant vous voudriez la partager, la charger sur un autre ordinateur, la… sauvegarder !
En général, la sauvegarde se fait en deux parties :
- On sauvegarde le modèle, l’architecture de notre IA (ce n’est pas toujours possible, cela dépend du framework) : par exemple, notre IA a 100 neurones en entrée, 5 en sortie, la fonction d’activation utilisée est « softmax », etc…
- On sauvegarde les variables internes de l’IA, très souvent des poids qui lient les neurones entre eux (représentant la puissance d’une liaison entre deux neurones)
- Et parfois les deux se font en même temps (encore une fois, ça dépend des outils que l’on utilise)
Prenons l’exemple de Keras :
# Le modèle est converti en JSON
saved_model = model.to_json()
with open("model.json", "w") as file:
file.write(saved_model)
# Les variables (poids) sont convertis en HDF5
model.save_weights("model.h5")
Le modèle est sauvegardé en json d’une part, et les variables en hdf5 d’autre part. On parle de « sérialisation » des objets ou de « dump ». Pour charger un modèle sauvegardé, la procédure est toute aussi simple :
# load json and create model
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
# load weights into new model
loaded_model.load_weights("model.h5")
Ces formats sont propres à Keras. Dans Caffe, on obtiendra plutôt un caffemodel ou un prototxt. Avec scikit-learn, on utilisera soit la librairie « pickle », soit « joblib ». Pour Tensorflow, on dispose d’un Saver (qui donne un ckpt : checkpoint, un fichier meta, un « frozengraph »… en fonction de ce que l’on veut accomplir). Enfin, pour PyTorch, vous obtiendrez un pt ou pth.
Remarque : il est possible (et conseillé) de faire des sauvegardes durant l’entraînement, de manière régulière. On parle de checkpoints, qui permettront par la suite de prendre un modèle d’IA qui généralise bien mieux que celui obtenu à la fin de l’entraînement (on détaillera ce phénomène dans la une prochaine partie).
Comment s’organise le temps d’un développeur ?
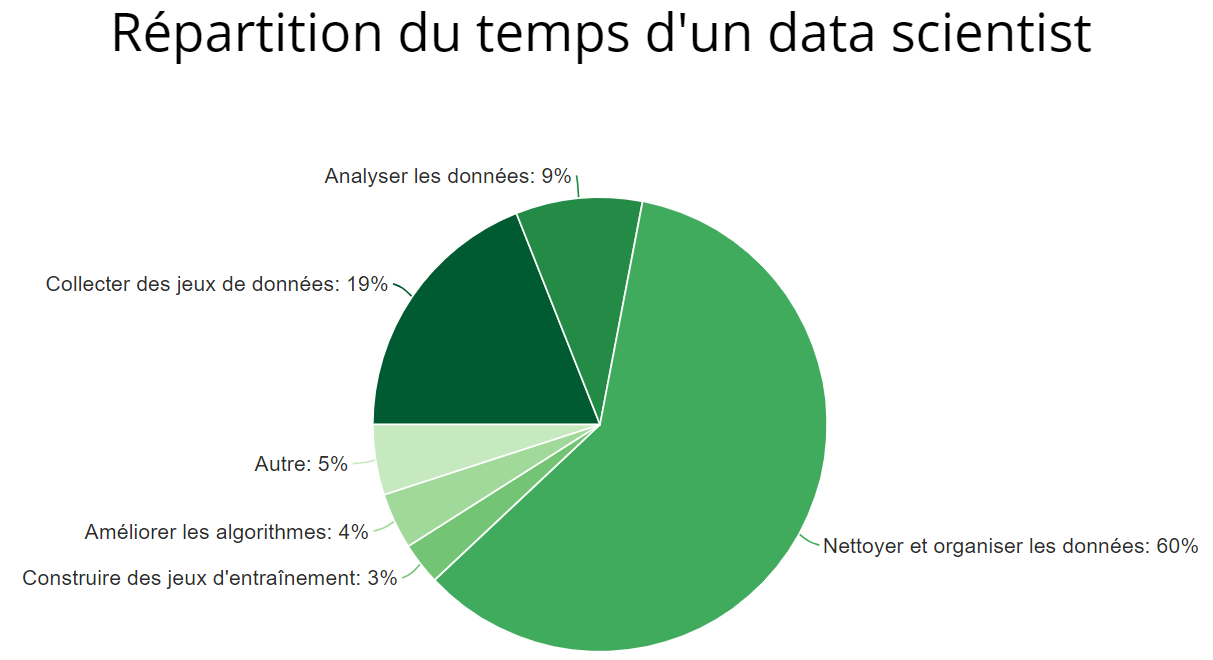
Puisqu’on en a déjà beaucoup parlé et que l’on va beaucoup en parler, je ne vais donner dans ce paragraphe que le pipeline d’un développeur en IA. A noter que cela dépend de beaucoup de paramètres liés à l’entreprise, la mission, le rôle (data scientist, machine learning researcher…). L’idée est plutôt de voir « tout ce qu’il y a à faire ».
- Définir précisément la valeur métier que doit avoir l’IA. Par exemple, être capable de prédire quel produit de la boutique sera le plus à même d’être acheté avec celui qui est consulté
- Choisir un modèle d’IA pour répondre au besoin. Faut-il plutôt partir sur du machine learning classique (Random Forest avec ses arbres de décisions) ou sur du deep learning (avec des deep autoencoders) ? Remarque : en général, on teste plusieurs types d’IA différentes
- Agréger les données pour l’entraînement : les télécharger ou les récupérer depuis des logs, etc…
- Analyser les données pour en déduire certains schémas, certaines corrélations (généralement le choix du modèle d’IA vient ici, surtout pour du machine learning)
- Préparer les données d’entraînement : les recadrer/transformer, les annoter, etc…
- Coder son IA, en choisissant les paramètres liés au modèle
- Entraîner l’IA sur les données préparées
- Tester d’autres paramètres et ré-entraîner l’IA avec, à répéter un certain nombre de fois… car la qualité d’une IA peut varier du tout au tout en fonction de ces « hyper-paramètres »
- Mettre son IA en production : la déployer sur un serveur et la rendre accessible
L’agrégation des données peut être longue en fonction du projet. La préparation des données est la phase la plus critique, car d’elle dépend en grande partie la performance finale. Par exemple, pour la reconnaissance faciale (bon ok, faudra que je trouve un autre exemple ça devient redondant), si on ne découpe pas les visages au préalable, l’IA détecte correctement à 60%. Si on découpe les visages avant de les identifier, on passe à… 97% (ces chiffres dépendent du projet bien sûr) !
Ensuite, ce qui va prendre beaucoup de temps à l’ordinateur mais moins au développeur (qui peut alors faire autre chose), c’est la partie « entraînement » : de quelques minutes à plusieurs jours.
Déploiement d’une IA : Docker, Kubernetes…
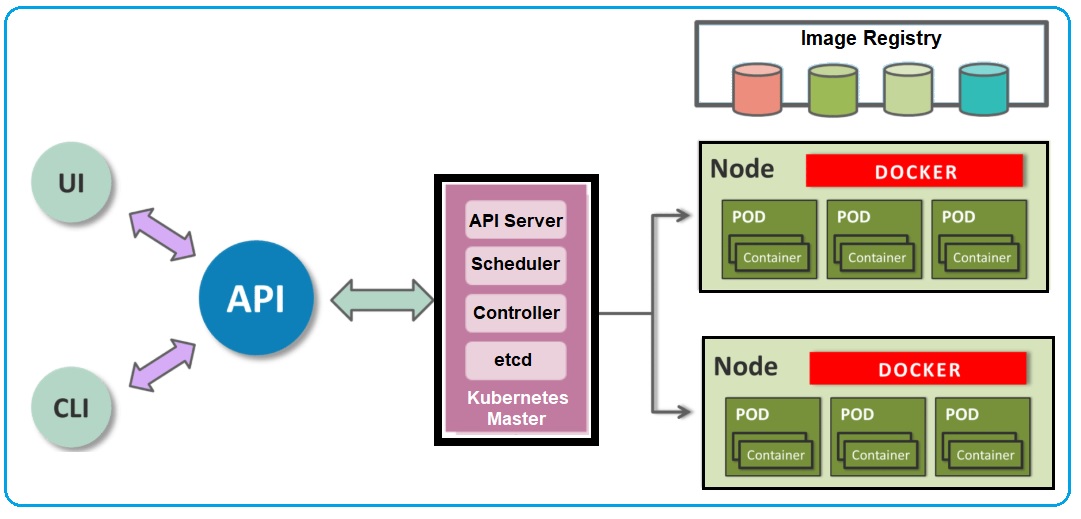
Chaque entreprise a sa manière de faire, mais en général deux outils principaux sont retenus pour le déploiement des applications (i.e. des IA) : docker et kubernetes.
- Docker : c’est une plateforme de conteneurs, qui ressemblent beaucoup à des machines virtuels (par exemple un Linux qui tourne dans Windows) à ceci près qu’ils s’appuient sur le système d’exploitation de la machine plutôt que de simuler tout un nouveau système. Il est donc extrêmement performant et rapide, permettant de déployer plusieurs environnements entiers (par exemple un Python avec une IA) sur n’importe quelle machine, avec toute la configuration associée ! Les images Docker (i.e. tout ce que va contenir cet environnement à déployer) se programment en fonction de ses besoins, voire se trouvent sur Internet. A noter que son principal concurrent est Rocket (alias rkt) (mais je ne l’ai jamais utilisé).
- Kubernetes : (le mot vient du grec « pilote, barreur ») Kubernetes fonctionne souvent en complément de Docker, qui gère le vie des conteneurs, car pour sa part, développé par Google, il se concentre sur l’orchestration des conteneurs. Concrètement, Docker va démarrer un conteneur avec votre IA et vous permettre de l’administrer, tandis que Kubernetes va chercher une machine pour héberger ce conteneur (ou démarrer une nouvelle machine virtuelle si besoin), chacun de manière à optimiser son travail !
D’un point de vue plus « implémentation« , les intelligences artificielles sont généralement accessibles (grâce à Flask par exemple) via des appels HTTP classiques : appelez une adresse web avec un GET (les adresses sont généralement au « format » REST) et obtenez souvent une réponse en JSON contenant votre prédiction. Le développement de micro-services (avec notamment le module Connexion en Python) est d’ailleurs régulièrement encouragé dans les sociétés, car cela apporte beaucoup de libertés et de flexibilités.
Une ia est souvent un micro-service rest géré avec du docker + kubernetes
Autres outils de data science : spark, hive, hadoop…
On revient très brièvement sur les données, avec cette fois-ci des outils permettant de les gérer et de travailler dessus (en en extrayant certaines lignes par exemple). N’hésitez pas à enquêter sur les différentes solutions de l’image, et n’oubliez pas que les offres et la concurrence évoluent avec le temps.
- Hadoop : c’est un framework dédié aux applications distribuées et scalables (i.e. les données et applications sont présentes sur plusieurs serveurs dans le « monde », et il est facile d’ajouter de nouveaux serveurs avec les mêmes données/applications pour répondre à davantage d’utilisateur sans temps de latence). Ecosystème regroupant beaucoup de modules (dont MapReduce, l’algorithme qui permet de paralléliser des recherches ou d’autres actions), tous ses outils ne sont pas estampillés « hadoop », mais sont développés par Apache.
- Spark : dédié au calcul distribué, Spark est l’un des frameworks les plus en vogue dans le milieu de la data science et du machine learning de par ses capacités de calcul élevées. Que ce soit pour du big data (avec des millions d’entrées) ou pour des bases de données plus modestes, Spark est capable d’effectuer des requêtes distribuées avec beaucoup d’efficacité.
- Hive : souvent opposé à Spark SQL, il s’agit d’un outil permettant de lancer les requêtes (donc généralement il ne va effectivement pas avec Spark vu qu’ils font le « même » travail). Je vous recommande cette infographie sur les différences entre Spark et Hive si ça vous intéresse.
- Yarn : sert à gérer le cluster (grappe de serveurs i.e. tous les serveurs qui contiennent notre IA)
- HDFS : système de base de données, sert au stockage. On le remplace souvent par des bases « no-sql » comme MongoDB.
Conclusion de cette seconde partie
Cette seconde partie touche à sa fin ! Nous nous sommes concentré sur l’écosystème de l’IA, en particulier ce qui touche à la data science, car tout développeur, manager ou chef de projet a besoin de ce type de connaissance. Non pas forcément dans le détail, mais a minima d’une idée générale !
Dans la prochaine partie, nous allons voir ensemble comment se former à l’IA et comment rester compétitif / pro-actif.
Crédit de l’image de couverture : Pexels – Pixabay License



 et la loi, ainsi qu'une partie de l'écosystème de la data science, fortement lié au machine learning){kind=link}